









当前时间
now() 返回年月日时分秒
当前日期
current_date() 返回年月日
开窗函数ROW_NUMBER() OVER()
函数语法:row_number() over (partition by 分组列 order by 排序列 desc)
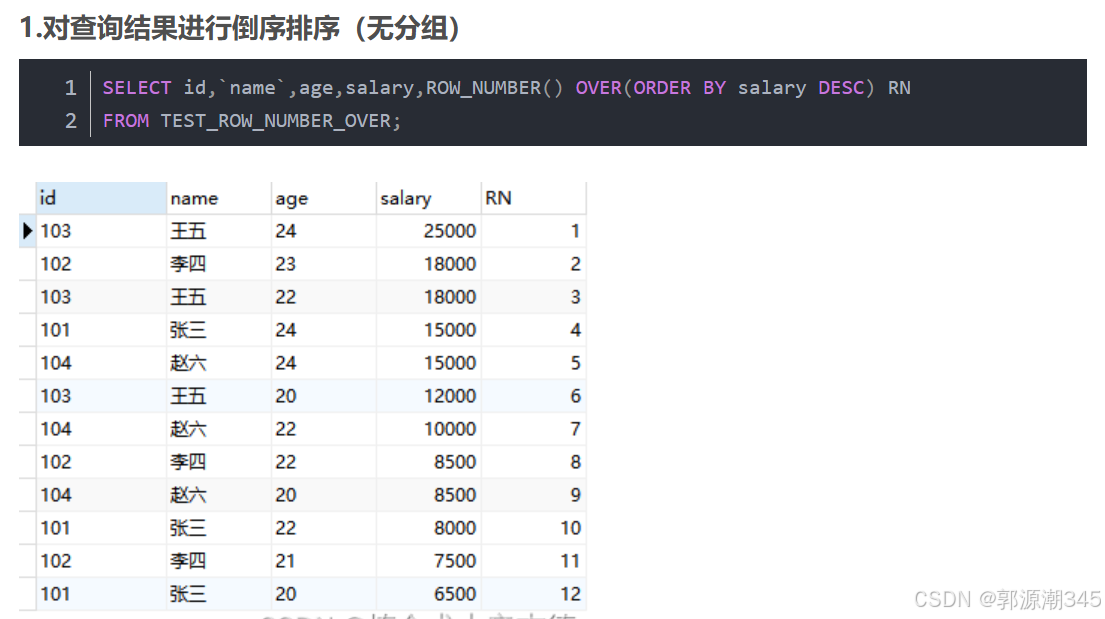
注:如果不指定分组那么会对全局进行排序,将所有数据视为一组;
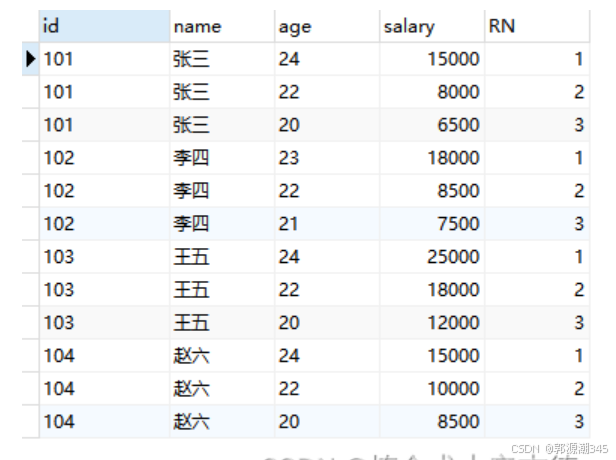
SELECT id,`name`,age,salary,ROW_NUMBER() OVER(PARTITION BY id ORDER BY salary DESC) RN
FROM TEST_ROW_NUMBER_OVER;
SELECT *
FROM (SELECT id,`name`,age,salary,ROW_NUMBER() OVER(PARTITION BY id ORDER BY salary DESC) RN
FROM TEST_ROW_NUMBER_OVER) M
WHERE M.RN < 1 ;
注意:partition by 多个分组字段用逗号分隔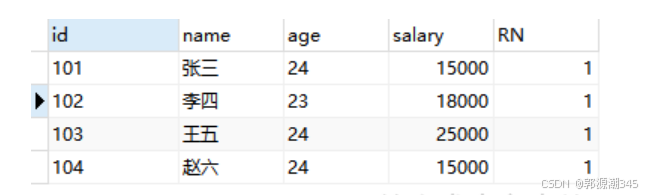
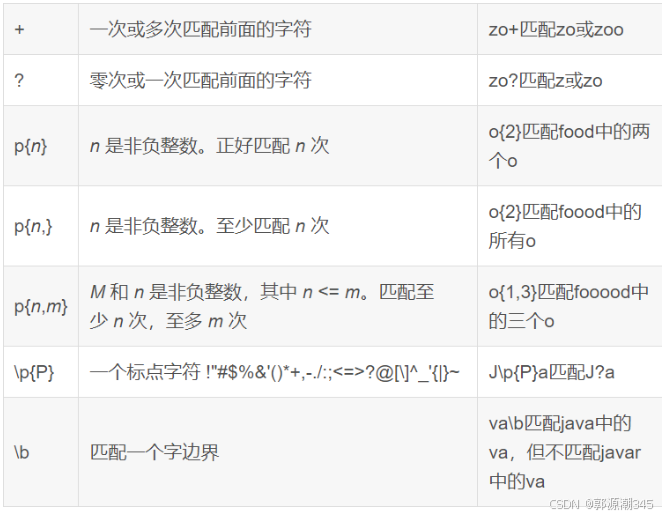
rlike()
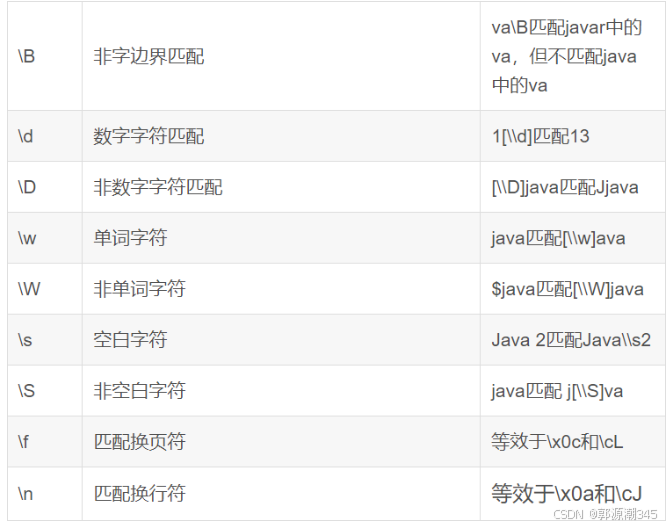

row_min()

date_add()

date_after_months()

date_sub()

day_diff()

first_day_of_month()

hour_diff()

last_day_of_month()

minute_diff()

quarter()

time_convert()

to_date()

work_day_of_month()

year_diff()

base64_decode()

concat()

concat_ws('分隔符',`字段1`,`字段2`),可以强制将空字符拼接起来
dist_code()

fbc()

gaode_lat()

gaode_lon()

instring()

ip_location()

packing_json()

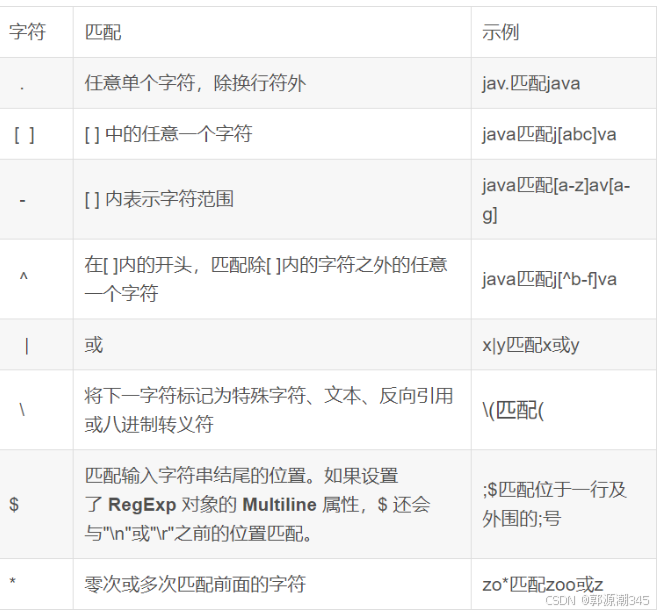
regexp_extract()

repeat()

reverse()

string_split()

ccoalesce()

coalesce()

explode()
explode(split(`字段`,'分隔符'))
将一行内容中按分隔符分隔为多行,其他字段值不变
collect_set()
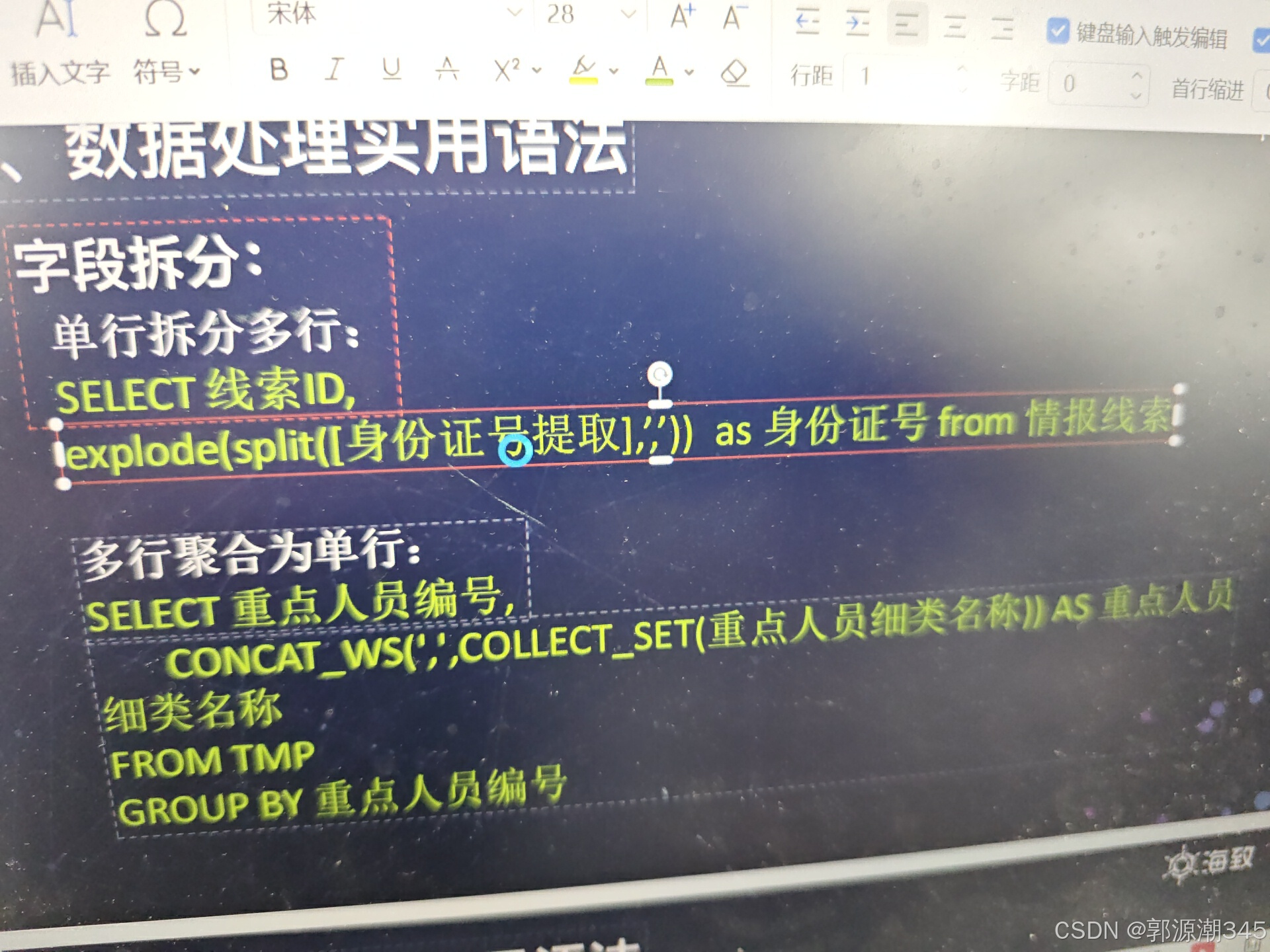
concat_ws('分隔符',collect_set(concat('分隔符',`聚合字段`,'分隔符'))) `new`
group by `聚合字段`
正则表达是解析地址
regexp_extract(address,'[^省]+市',0)
-
从匹配起点来理解
- 对于正则表达式
[^省]+市,[^省]是关键的起始部分。它就像一个筛选条件,规定了匹配必须从一个不是 “省” 字的字符开始。 - 以 “广东省广州市” 为例,这个表达式不会从 “广” 字之前(也就是 “广东” 的 “广” 字之前)开始匹配,因为它要先找到符合
[^省]这个条件的字符作为起点。在这里,它会从 “广” 字开始匹配,因为 “广” 不是 “省” 字,这就确定了匹配的起点是 “广”,从而跳过了 “广东” 这部分在 “省” 字之前的内容。
- 对于正则表达式
-
结合整个表达式理解
- 当从 “广” 字开始匹配后,
+符号的作用是让匹配继续进行。+表示前面的[^省](即除 “省” 字之外的字符)可以出现一次或多次。所以它会继续匹配 “州” 字,因为 “州” 也不是 “省” 字。 - 一直到遇到 “市” 字,整个匹配过程结束。整个过程是按照正则表达式的规则,从第一个不是 “省” 字的字符开始,匹配连续的不是 “省” 字的字符,直到出现 “市” 字,这种规则就导致了 “省” 字之前的内容不会被考虑和匹配。
- 当从 “广” 字开始匹配后,



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









