






在文本处理领域,字符频率统计是一项基础且实用的操作,它能够帮助我们分析文本的特征、挖掘潜在信息。Java 作为一门广泛应用的编程语言,提供了丰富的工具和方法来实现这一功能。本文将结合给定的 Java 代码和运行示例,深入探讨如何使用 Java 进行字符频率统计,希望能为读者在文本处理编程方面提供有益的参考。
一、功能需求与设计思路
(一)功能需求
程序的主要任务是接收用户输入的一个以句号结尾的句子,统计句子中每个英文字母(包括大小写)以及空格出现的频率,并按照特定格式输出统计结果。
(二)设计思路
- 输入处理:利用
Scanner类获取用户输入的句子,通过useDelimiter("\n")方法修改默认分隔符,确保能正确读取包含空格的完整句子。 - 字符数组转换:将输入的字符串转换为字符数组,方便后续对每个字符进行遍历和统计。
- 统计方法设计:编写两个方法
numberA和numberB来统计字符出现的频率。numberA方法用于统计单个字符的出现次数,numberB方法专门处理字符'Y'和'y'的统计,因为它们需要同时考虑大小写情况。 - 结果输出:按照规定的格式,将每个字符的统计结果进行格式化输出,使结果清晰易读。
二、代码实现详解
(一)导入包与主函数框架
import java.util.Scanner;
public class CharFrequency {
public static void main(String[] args) {
Scanner in = new Scanner(System.in);
in.useDelimiter("\n");
System.out.print("Enter a sentence terminated by a full stop:");
System.out.println();
String Sentence = in.next();
char sentence[] = new char[Sentence.length()];
sentence = Sentence.toCharArray();
System.out.println();
System.out.print("Frequency analysis for this sentence:");
System.out.println();
// 后续字符统计及输出代码...
}
}在这段代码中,首先导入java.util.Scanner包,用于获取用户输入。在main函数中,创建Scanner对象in,并修改其分隔符为换行符,以便读取整行输入。接着,提示用户输入句子,将输入的字符串存储到Sentence变量中,并转换为字符数组sentence,为后续的字符统计做准备。
(二)字符统计方法
numberA方法
public static int numberA(char letter, char sentence[], String Sentence) {
int count = 0;
for (int j = 0; j < Sentence.length(); j++) {
if (letter == sentence[j]) {
count++;
}
}
return count;
}numberA方法接收一个字符letter、字符数组sentence和原始字符串Sentence作为参数。通过遍历字符数组,比较每个字符是否与目标字符letter相等,如果相等则计数器count加 1。最后返回计数器的值,即目标字符在句子中出现的次数。
numberB方法
public static int numberB(char sentence[], String Sentence) {
int count = 0;
char letter1 = 'Y';
char letter2 = 'y';
for (int j = 0; j < Sentence.length(); j++) {
if (letter1 == sentence[j] || letter2 == sentence[j]) {
count++;
}
}
return count;
}numberB方法专门用于统计字符'Y'和'y'的出现次数。它定义了两个字符变量letter1和letter2分别表示大写'Y'和小写'y'。在遍历字符数组时,只要字符等于letter1或letter2,计数器count就加 1,最后返回统计结果。
(三)结果输出
char a, b, c, d, e, f, g, h, i, j, k, l, m, n, o, p, q, r, s, t, u, v, w, x, y, z, space;
char A = 'a';
char B = 'b';
char C = 'c';
char D = 'd';
char E = 'e';
char F = 'f';
char G = 'g';
char H = 'h';
char I = 'i';
char J = 'j';
char K = 'k';
char L = 'l';
char M ='m';
char N = 'n';
char O = 'o';
char P = 'p';
char Q = 'q';
char R = 'r';
char S ='s';
char T = 't';
char U = 'u';
char V = 'v';
char W = 'w';
char X = 'x';
char Y = 'y';
char Z = 'z';
char Space ='';
int numspace = numberA(Space, sentence, Sentence);
int numa = numberA(A, sentence, Sentence);
int numb = numberA(B, sentence, Sentence);
int numc=numberA(C,sentence,Sentence);
int numd=numberA(D,sentence,Sentence);
int nume=numberA(E,sentence,Sentence);
int numf=numberA(F,sentence,Sentence);
int numg=numberA(G,sentence,Sentence);
int numh=numberA(H,sentence,Sentence);
int numi=numberA(I,sentence,Sentence);
int numj=numberA(J,sentence,Sentence);
int numk=numberA(K,sentence,Sentence);
int numl=numberA(L,sentence,Sentence);
int numm=numberA(M,sentence,Sentence);
int numn=numberA(N,sentence,Sentence);
int numo=numberA(O,sentence,Sentence);
int nump=numberA(P,sentence,Sentence);
int numq=numberA(Q,sentence,Sentence);
int numr=numberA(R,sentence,Sentence);
int nums=numberA(S,sentence,Sentence);
int numt=numberA(T,sentence,Sentence);
int numu=numberA(U,sentence,Sentence);
int numv=numberA(V,sentence,Sentence);
int numw=numberA(W,sentence,Sentence);
int numx=numberA(X,sentence,Sentence);
int numy = numberB(sentence, Sentence);
int numz = numberA(Z, sentence, Sentence);
System.out.printf("A%4d; \tB%4d; \tC%4d; \tD%4d; \tE%4d\n", numa, numb, numc, numd, nume);
System.out.printf("F%4d; \tG%4d; \tH%4d; \tI%4d; \tJ%4d\n", numf, numg, numh, numi, numj);
System.out.printf("K%4d; \tL%4d; \tM%4d; \tN%4d; \tO%4d\n", numk, numl, numm, numn, numo);
System.out.printf("P%4d; \tQ%4d; \tR%4d; \tS%4d; \tT%4d\n", nump, numq, numr, nums, numt);
System.out.printf("U%4d; \tV%4d; \tW%4d; \tX%4d; \tY%4d\n", numu, numv, numw, numx, numy);
System.out.printf("Z%4d; \tspace%2d.\n", numz, numspace);在这部分代码中,首先定义了所有需要统计的字符变量,并通过调用numberA和numberB方法获取每个字符在句子中的出现次数。然后,使用System.out.printf方法按照特定格式输出统计结果,每个字符及其出现次数之间用制表符\t分隔,使输出结果呈现整齐的表格形式。
三、代码优化与拓展方向
(一)优化建议
- 代码结构优化:当前代码在字符定义和方法调用部分显得较为繁琐,可以考虑使用数组或集合来存储字符,通过循环进行统计和输出,减少重复代码。例如,可以使用
char[] letters = {'a', 'b', 'c',... 'z'};定义字符数组,然后通过循环调用numberA方法进行统计。 - 忽略非字母字符:目前程序没有对输入句子中的非字母字符进行处理,可能会影响统计结果的准确性。可以在统计前添加过滤逻辑,只统计字母和空格字符,忽略其他字符。
- 大小写统一处理:对于大小写字母的统计,除了
'Y'和'y',其他字母也可以统一转换为大写或小写后再进行统计,这样可以简化代码逻辑。可以使用String类的toLowerCase()或toUpperCase()方法对输入字符串进行预处理。
(二)拓展方向
- 多语言字符支持:可以扩展程序,使其支持更多语言的字符频率统计,例如中文、日文、韩文等。这需要对字符编码有更深入的理解,并使用相应的字符处理方法。
- 文本文件处理:将程序扩展为能够处理文本文件,读取文件内容并进行字符频率统计。可以使用 Java 的文件读取流,如
FileReader或BufferedReader来读取文件内容,然后进行统计。 - 可视化展示:将统计结果以可视化的方式展示,例如使用 Java 的图形绘制库(如 Swing 或 JavaFX)绘制柱状图或饼图,使结果更加直观。
四、结果展示
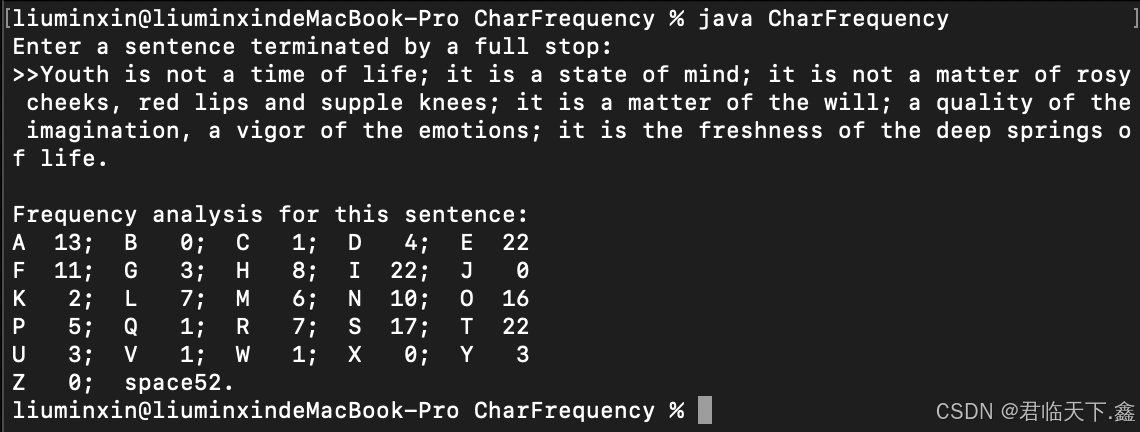
五、总结
通过本文介绍的 Java 代码实现,我们完成了一个简单的字符频率统计程序。在实现过程中,我们学习了 Java 中Scanner类的使用、字符数组的操作、方法的编写以及格式化输出等知识。同时,对代码的优化和拓展方向进行了探讨,希望读者能够在此基础上进一步探索和实践,提升自己在文本处理编程方面的能力。在实际应用中,字符频率统计可以用于文本分析、密码学、信息检索等多个领域,具有重要的实用价值。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









