1.赛题背景
- 商家有时会在特定日期,例如黑色星期五或是双十一开展大型促销活动或者发放优惠券以吸引消费者,然而很多被吸引来的买家都是一次性消费者,这些促销活动可能对销售业绩的增长并没有长远帮助。因此为解决这个问题,商家需要识别出哪类消费者可以转化为重复购买者。通过对这些潜在的忠诚客户进行定位,商家可以大大降低促销成本,提高投资回报率(ReturnonInvestment,ROI)。众所周知的是,在线投放广告时精准定位客户是件比较难的事情,尤其是针对新消费者的定位。不过,利用天猫长期积累的用户行为日志,我们或许可以通过算法建模解决这个问题。
- 天猫提供了一些商家信息,以及在“双十一”期间购买了对应产品的新消费者信息。你的任务是预测给定的商家中,哪些新消费者在未来会成为忠实客户,即需要预测这些新消费者在未来6个月内再次购买的概率
2.数据描述
- 数据集包含了匿名用户在"双十一"前6个月和"双十一"当天的购物记录,标签为是否是重复购买者。出于隐私保护,数据采样存在部分偏差,该数据集的统计结果会与天猫的实际情况有一定的偏差,但不影响解决方案的适用性
- 下面继续了解数据的详细信息,主要有用户行为日志、用户特征表、以及训练数据和测试数据三张表格。
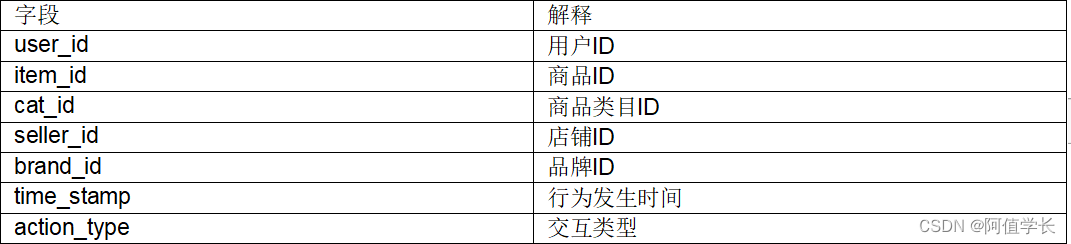
2.1 用户行为日志表
action_type字段:
0 表示点击
1 表示加入购物车
2 表示购买
3 表示收藏
2.2 用户特征表
age_range字段:
1 表示<18
2 表示[18,24]
3 表示[25,29]
4 表示[30,34]
5 表示[35,39]
6 表示[40,49]
7和8 表示>=50
0和Null 表示未知
gender字段:
0 表示女性
1表示男性
2和Null 表示未知

2.3 训练测试数据表
label字段:
0 表示非重复购买
1 表示重复购买

3.模型导入
import gc
import pandas as pd
import numpy as np
import warnings
warnings.filterwarnings('ignore')
from sklearn.model_selection import train_test_split
from sklearn.model_selection import StratifiedKFold
import lightgbm as lgb
import xgboost as xgb
4.数据加载
%%time
user_log = pd.read_csv('./data_format1/user_log_format1.csv', dtype={'time_stamp':'str'})
user_info = pd.read_csv('./data_format1/user_info_format1.csv')
train_data = pd.read_csv('./data_format1/train_format1.csv')
test_data = pd.read_csv('./data_format1/test_format1.csv')
5.数据查看
print('---data shape---')
for data in [user_log, user_info, train_data, test_data]:
print(data.shape)
---data shape---
(54925330, 7)
(424170, 3)
(260864, 3)
(261477, 3)
print('---data info ---')
for data in [user_log, user_info, train_data, test_data]:
print(data.info())
---data info ---
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 54925330 entries, 0 to 54925329
Data columns (total 7 columns):
--- ------ -----
0 user_id int64
1 item_id int64
2 cat_id int64
3 seller_id int64
4 brand_id float64
5 time_stamp object
6 action_type int64
dtypes: float64(1), int64(5), object(1)
memory usage: 2.9+ GB
None
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 424170 entries, 0 to 424169
Data columns (total 3 columns):
--- ------ -------------- -----
0 user_id 424170 non-null int64
1 age_range 421953 non-null float64
2 gender 417734 non-null float64
dtypes: float64(2), int64(1)
memory usage: 9.7 MB
None
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 260864 entries, 0 to 260863
Data columns (total 3 columns):
--- ------ -------------- -----
0 user_id 260864 non-null int64
1 merchant_id 260864 non-null int64
2 label 260864 non-null int64
dtypes: int64(3)
memory usage: 6.0 MB
None
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 261477 entries, 0 to 261476
Data columns (total 3 columns):
--- ------ -------------- -----
0 user_id 261477 non-null int64
1 merchant_id 261477 non-null int64
2 prob 0 non-null float64
dtypes: float64(1), int64(2)
memory usage: 6.0 MB
None
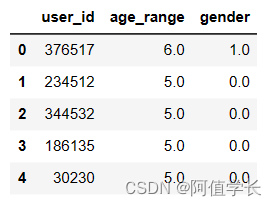
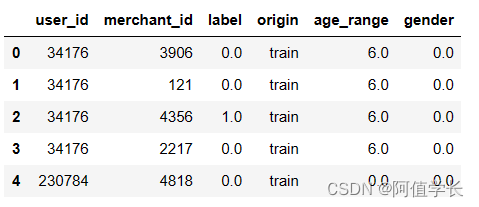
display(user_info.head())
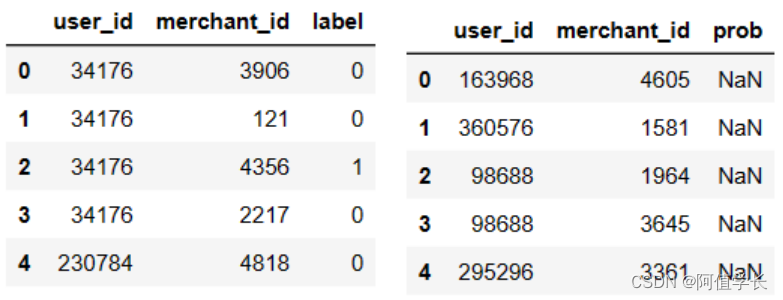
display(train_data.head(),test_data.head())
6.数据集
train_data['origin'] = 'train'
test_data['origin'] = 'test'
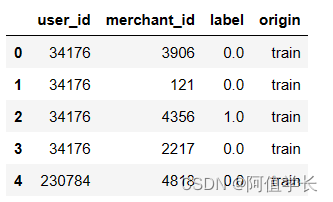
all_data = pd.concat([train_data, test_data], ignore_index=True, sort=False)
all_data.drop(['prob'], axis=1, inplace=True)
display(all_data.head(),all_data.shape)
(522341, 4)
all_data = all_data.merge(user_info, on='user_id', how='left')
display(all_data.shape,all_data.head())
(522341, 6)
user_log.rename(columns={'seller_id':'merchant_id'}, inplace=True)
del train_data,test_data,user_info
gc.collect()
48
7.数据类型转换
%%time
display(user_log.info())
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 54925330 entries, 0 to 54925329
Data columns (total 7 columns):
--- ------ -----
0 user_id int64
1 item_id int64
2 cat_id int64
3 merchant_id int64
4 brand_id float64
5 time_stamp object
6 action_type int64
dtypes: float64(1), int64(5), object(1)
memory usage: 2.9+ GB
None
Wall time: 8.94 ms
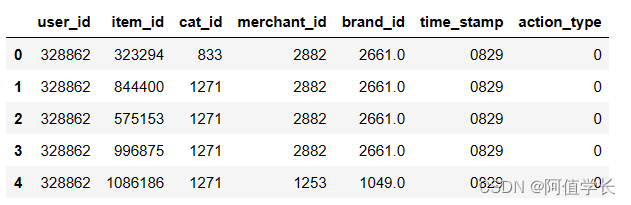
%%time
display(user_log.head())
Wall time: 7.99 ms
7.1 用户行为数据类型转换
%%time
user_log['user_id'] = user_log['user_id'].astype('int32')
user_log['merchant_id'] = user_log['merchant_id'].astype('int32')
user_log['item_id'] = user_log['item_id'].astype('int32')
user_log['cat_id'] = user_log['cat_id'].astype('int32')
user_log['brand_id'].fillna(0, inplace=True)
user_log['brand_id'] = user_log['brand_id'].astype('int32')
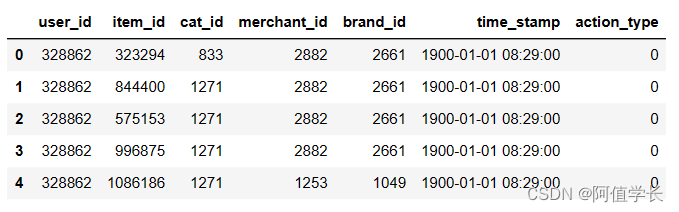
user_log['time_stamp'] = pd.to_datetime(user_log['time_stamp'], format='%H%M')
user_log['action_type'] = user_log['action_type'].astype('int32')
display(user_log.info(),user_log.head())
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 54925330 entries, 0 to 54925329
Data columns (total 7 columns):
--- ------ -----
0 user_id int32
1 item_id int32
2 cat_id int32
3 merchant_id int32
4 brand_id int32
5 time_stamp datetime64[ns]
6 action_type int32
dtypes: datetime64[ns](1), int32(6)
memory usage: 1.6 GB
None
Wall time: 8.59 s
display(all_data.isnull().sum())
user_id 0
merchant_id 0
label 261477
origin 0
age_range 2578
gender 7545
dtype: int64
7.2 all_data数据集缺失值填充
all_data['age_range'].fillna(0, inplace=True)
all_data['gender'].fillna(2, inplace=True)
all_data.isnull().sum()
user_id 0
merchant_id 0
label 261477
origin 0
age_range 0
gender 0
dtype: int64
7.3 all_data数据集类型转换
all_data.info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 522341 entries, 0 to 522340
Data columns (total 6 columns):
--- ------ -------------- -----
0 user_id 522341 non-null int64
1 merchant_id 522341 non-null int64
2 label 260864 non-null float64
3 origin 522341 non-null object
4 age_range 522341 non-null float64
5 gender 522341 non-null float64
dtypes: float64(3), int64(2), object(1)
memory usage: 27.9+ MB
all_data['age_range'] = all_data['age_range'].astype('int8')
all_data['gender'] = all_data['gender'].astype('int8')
all_data['label'] = all_data['label'].astype('str')
all_data['user_id'] = all_data['user_id'].astype('int32')
all_data['merchant_id'] = all_data['merchant_id'].astype('int32')
all_data.info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 522341 entries, 0 to 522340
Data columns (total 6 columns):
--- ------ -------------- -----
0 user_id 522341 non-null int32
1 merchant_id 522341 non-null int32
2 label 522341 non-null object
3 origin 522341 non-null object
4 age_range 522341 non-null int8
5 gender 522341 non-null int8
dtypes: int32(2), int8(2), object(2)
memory usage: 16.9+ MB
8.特征工程1-用户
%%time
groups = user_log.groupby(['user_id'])
temp = groups.size().reset_index().rename(columns={0:'u1'})
all_data = all_data.merge(temp, on='user_id', how='left')
temp = groups['item_id'].agg([('u2', 'nunique')]).reset_index()
all_data = all_data.merge(temp, on='user_id', how='left')
temp = groups['cat_id'].agg([('u3', 'nunique')]).reset_index()
all_data = all_data.merge(temp, on='user_id', how='left')
temp = groups['merchant_id'].agg([('u4', 'nunique')]).reset_index()
all_data = all_data.merge(temp, on='user_id', how='left')
temp = groups['brand_id'].agg([('u5', 'nunique')]).reset_index()
all_data = all_data.merge(temp, on='user_id', how='left')
temp = groups['time_stamp'].agg([('F_time', 'min'), ('B_time', 'max')]).reset_index()
temp['u6'] = (temp['B_time'] - temp['F_time']).dt.seconds/3600
all_data = all_data.merge(temp[['user_id', 'u6']], on='user_id', how='left')
temp = groups['action_type'].value_counts().unstack().reset_index().rename(
columns={0:'u7', 1:'u8', 2:'u9', 3:'u10'})
all_data = all_data.merge(temp, on='user_id', how='left')
del temp,groups
gc.collect()
Wall time: 4min 18s
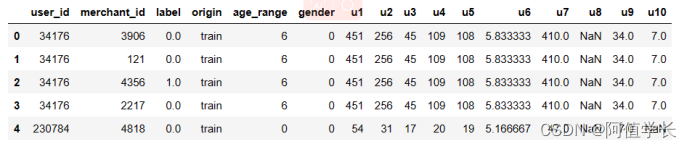
all_data.head()
9.特征工程2-店铺
%%time
groups = user_log.groupby(['merchant_id'])
temp = groups.size().reset_index().rename(columns={0:'m1'})
all_data = all_data.merge(temp, on='merchant_id', how='left')
temp = groups['user_id', 'item_id', 'cat_id', 'brand_id'].nunique().reset_index().rename(
columns={
'user_id':'m2',
'item_id':'m3',
'cat_id':'m4',
'brand_id':'m5'})
all_data = all_data.merge(temp, on='merchant_id', how='left')
temp = groups['action_type'].value_counts().unstack().reset_index().rename(
columns={0:'m6', 1:'m7', 2:'m8', 3:'m9'})
all_data = all_data.merge(temp, on='merchant_id', how='left')
del temp
gc.collect()
Wall time: 5min 21s
8798
display(all_data.tail())

10.特征工程3-用户及店铺
%%time
groups = user_log.groupby(['user_id', 'merchant_id'])
temp = groups.size().reset_index().rename(columns={0:'um1'})
all_data = all_data.merge(temp, on=['user_id', 'merchant_id'], how='left')
temp = groups['item_id', 'cat_id', 'brand_id'].nunique().reset_index().rename(
columns={
'item_id':'um2',
'cat_id':'um3',
'brand_id':'um4'})
all_data = all_data.merge(temp, on=['user_id', 'merchant_id'], how='left')
temp = groups['action_type'].value_counts().unstack().reset_index().rename(
columns={
0:'um5',
1:'um6',
2:'um7',
3:'um8'})
all_data = all_data.merge(temp, on=['user_id', 'merchant_id'], how='left')
temp = groups['time_stamp'].agg([('F_time', 'min'), ('B_time', 'max')]).reset_index()
temp['um9'] = (temp['B_time'] - temp['F_time']).dt.seconds/3600
all_data = all_data.merge(temp[['user_id','merchant_id','um9']], on=['user_id', 'merchant_id'], how='left')
del temp,groups
gc.collect()
Wall time: 4min 22s
9096
display(all_data.head())
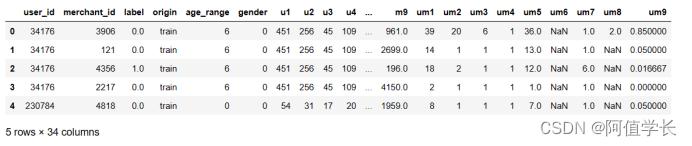
11.特征工程4-购买点击比
all_data['r1'] = all_data['u9']/all_data['u7']
all_data['r2'] = all_data['m8']/all_data['m6']
all_data['r3'] = all_data['um7']/all_data['um5']
display(all_data.head())

12.空数据填充
display(all_data.isnull().sum())
user_id 0
merchant_id 0
...
r2 0
r3 59408
dtype: int64
all_data.fillna(0, inplace=True)
all_data.isnull().sum()
user_id 0
merchant_id 0
...
r2 0
r3 0
dtype: int64
13.特征转换-年龄、性别
all_data['age_range']
0 6
1 6
2 6
..
522339 0
522340 0
Name: age_range, Length: 522341, dtype: int8
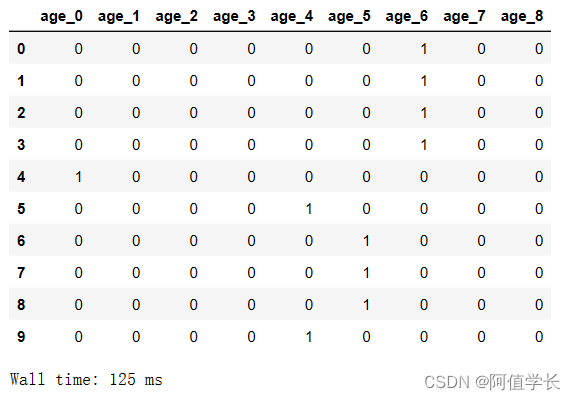
%%time
temp = pd.get_dummies(all_data['age_range'], prefix='age')
display(temp.head(10))
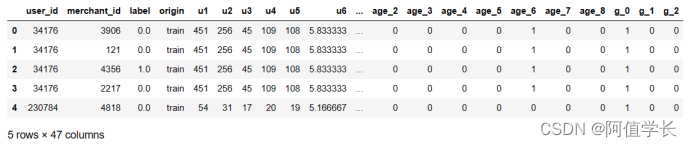
all_data = pd.concat([all_data, temp], axis=1)
temp = pd.get_dummies(all_data['gender'], prefix='g')
all_data = pd.concat([all_data, temp], axis=1)
all_data.drop(['age_range', 'gender'], axis=1, inplace=True)
del temp
gc.collect()
18438
all_data.head()
14.数据存储
%%time
train_data = all_data[all_data['origin'] == 'train'].drop(['origin'], axis=1)
test_data = all_data[all_data['origin'] == 'test'].drop(['label', 'origin'], axis=1)
train_data.to_csv('train_data.csv')
test_data.to_csv('test_data.csv')
Wall time: 9.14 s
15.LGB模型
def lgb_train(X_train, y_train, X_valid, y_valid, verbose=True):
model_lgb = lgb.LGBMClassifier(
max_depth=10,
n_estimators=5000,
min_child_weight=100,
colsample_bytree=0.7,
subsample=0.9,
learning_rate=0.1)
model_lgb.fit(
X_train,
y_train,
eval_metric='auc',
eval_set=[(X_train, y_train), (X_valid, y_valid)],
verbose=verbose,
early_stopping_rounds=10)
print(model_lgb.best_score_['valid_1']['auc'])
return model_lgb
X_train
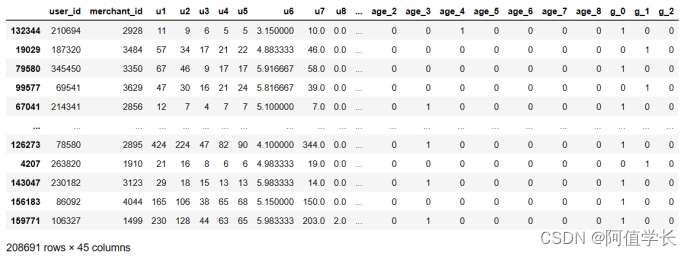
X_train.values
array([[2.10694e+05, 2.92800e+03, 1.10000e+01, ..., 1.00000e+00,
0.00000e+00, 0.00000e+00],
[1.87320e+05, 3.48400e+03, 5.70000e+01, ..., 0.00000e+00,
1.00000e+00, 0.00000e+00],
[3.45450e+05, 3.35000e+03, 6.70000e+01, ..., 1.00000e+00,
0.00000e+00, 0.00000e+00],
...,
[2.30182e+05, 3.12300e+03, 2.90000e+01, ..., 1.00000e+00,
0.00000e+00, 0.00000e+00],
[8.60920e+04, 4.04400e+03, 1.65000e+02, ..., 1.00000e+00,
0.00000e+00, 0.00000e+00],
[1.06327e+05, 1.49900e+03, 2.30000e+02, ..., 1.00000e+00,
0.00000e+00, 0.00000e+00]])
model_lgb = lgb_train(X_train.values, y_train, X_valid.values, y_valid, verbose=True)
[1] training's auc: 0.640009 training's binary_logloss: 0.228212 valid_1's auc: 0.627955 valid_1's binary_logloss: 0.229246
Training until validation scores don't improve for 10 rounds.
[2] training's auc: 0.648943 training's binary_logloss: 0.226955 valid_1's auc: 0.636741 valid_1's binary_logloss: 0.228055
...
[113] training's auc: 0.734736 training's binary_logloss: 0.208817 valid_1's auc: 0.676738 valid_1's binary_logloss: 0.218372
[114] training's auc: 0.73495 training's binary_logloss: 0.208776 valid_1's auc: 0.676778 valid_1's binary_logloss: 0.218366
Early stopping, best iteration is:
[104] training's auc: 0.731472 training's binary_logloss: 0.209388 valid_1's auc: 0.6767 valid_1's binary_logloss: 0.218354
0.6766996167512115
%%time
prob = model_lgb.predict_proba(test_data.values)
prob
array([[0.94812479, 0.05187521],
[0.88438038, 0.11561962],
[0.94936734, 0.05063266],
...,
[0.85627925, 0.14372075],
[0.95222606, 0.04777394],
[0.92295125, 0.07704875]])
submission = pd.read_csv('./data_format1/test_format1.csv')
submission['prob'] = pd.Series(prob[:,1])
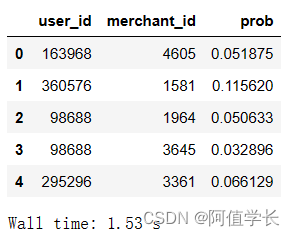
display(submission.head())
submission.to_csv('submission_lgb.csv', index=False)
del submission
gc.collect()
22630
16.XGB模型
def xgb_train(X_train, y_train, X_valid, y_valid, verbose=True):
model_xgb = xgb.XGBClassifier(
max_depth=10,
n_estimators=5000,
min_child_weight=300,
colsample_bytree=0.7,
subsample=0.9,
learing_rate=0.1)
model_xgb.fit(
X_train,
y_train,
eval_metric='auc',
eval_set=[(X_train, y_train), (X_valid, y_valid)],
verbose=verbose,
early_stopping_rounds=10)
print(model_xgb.best_score)
return model_xgb
model_xgb = xgb_train(X_train, y_train, X_valid, y_valid, verbose=False)
0.673734
%%time
prob = model_xgb.predict_proba(test_data)
submission = pd.read_csv('./data_format1/test_format1.csv')
submission['prob'] = pd.Series(prob[:,1])
submission.to_csv('submission_xgb.csv', index=False)
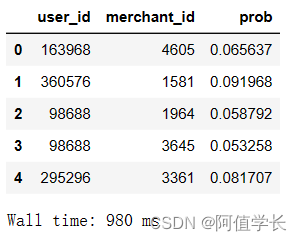
display(submission.head())
del submission
gc.collect()
509
17.交叉验证多轮建模
def get_train_test_datas(train_df,label_df):
skv = StratifiedKFold(n_splits=10, shuffle=True)
trainX = []
trainY = []
testX = []
testY = []
for train_index, test_index in skv.split(X=train_df, y=label_df):
train_x, train_y, test_x, test_y = train_df.iloc[train_index, :], label_df.iloc[train_index], \
train_df.iloc[test_index, :], label_df.iloc[test_index]
trainX.append(train_x)
trainY.append(train_y)
testX.append(test_x)
testY.append(test_y)
return trainX, testX, trainY, testY
%%time
train_X, train_y = train_data.drop(['label'], axis=1), train_data['label']
X_train, X_valid, y_train, y_valid = get_train_test_datas(train_X, train_y)
print('----训练数据,长度',len(X_train))
print('----验证数据,长度',len(X_valid))
pred_lgbms = []
for i in range(10):
print('\n============================LGB training use Data {}/10============================\n'.format(i+1))
model_lgb = lgb.LGBMClassifier(
max_depth=10,
n_estimators=1000,
min_child_weight=100,
colsample_bytree=0.7,
subsample=0.9,
learning_rate=0.05)
model_lgb.fit(
X_train[i].values,
y_train[i],
eval_metric='auc',
eval_set=[(X_train[i].values, y_train[i]), (X_valid[i].values, y_valid[i])],
verbose=False,
early_stopping_rounds=10)
print(model_lgb.best_score_['valid_1']['auc'])
pred = model_lgb.predict_proba(test_data.values)
pred = pd.DataFrame(pred[:,1])
pred_lgbms.append(pred)
pred_lgbms = pd.concat(pred_lgbms, axis=1)
submission = pd.read_csv('./data_format1/test_format1.csv')
submission['prob'] = pred_lgbms.mean(axis=1)
submission.to_csv('submission_KFold_lgb.csv', index=False)
----训练数据,长度 10
----验证数据,长度 10
============================LGB training use Data 1/10============================
0.6764325578514025
...
============================LGB training use Data 9/10============================
0.6850513956313553
============================LGB training use Data 10/10============================
0.6863430735031704
Wall time: 1min 17s
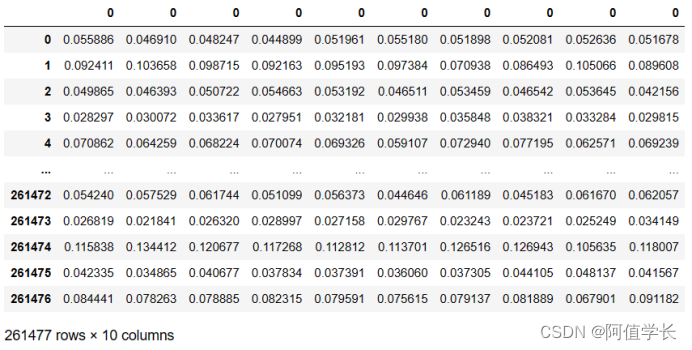
pred_lgbms
def get_train_test_datas(train_df,label_df):
skv = StratifiedKFold(n_splits=20, shuffle=True)
trainX = []
trainY = []
testX = []
testY = []
for train_index, test_index in skv.split(X=train_df, y=label_df):
train_x, train_y, test_x, test_y = train_df.iloc[train_index, :], label_df.iloc[train_index], \
train_df.iloc[test_index, :], label_df.iloc[test_index]
trainX.append(train_x)
trainY.append(train_y)
testX.append(test_x)
testY.append(test_y)
return trainX, testX, trainY, testY
%%time
train_X, train_y = train_data.drop(['label'], axis=1), train_data['label']
X_train, X_valid, y_train, y_valid = get_train_test_datas(train_X, train_y)
print('------数据长度',len(X_train),len(y_train))
pred_xgbs = []
for i in range(20):
print('\n============================XGB training use Data {}/20============================\n'.format(i+1))
model_xgb = xgb.XGBClassifier(
max_depth=10,
n_estimators=5000,
min_child_weight=200,
colsample_bytree=0.7,
subsample=0.9,
learning_rate = 0.1)
model_xgb.fit(
X_train[i],
y_train[i],
eval_metric='auc',
eval_set=[(X_train[i], y_train[i]), (X_valid[i], y_valid[i])],
verbose=False,
early_stopping_rounds=10 )
print(model_xgb.best_score)
pred = model_xgb.predict_proba(test_data)
pred = pd.DataFrame(pred[:,1])
pred_xgbs.append(pred)
pred_xgbs = pd.concat(pred_xgbs, axis=1)
submission = pd.read_csv('./data_format1/test_format1.csv')
submission['prob'] = pred_xgbs.mean(axis=1)
submission.to_csv('submission_KFold_xgb.csv', index=False)
------数据长度 20 20
============================XGB training use Data 1/20============================
0.710332
...
============================XGB training use Data 19/20============================
0.674658
============================XGB training use Data 20/20============================
0.694476
Wall time: 8min 39s

























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











