






 在面临网站反爬机制时,使用模拟浏览器发送请求是常见策略。要获取User-Agent,可以利用浏览器的开发者工具。例如,在Edge浏览器中,打开F12,进入网络标签,刷新页面,找到第一个文件并双击,底部显示的User-Agent即是所需。不同浏览器的开发者工具虽布局略有差异,但基本都提供查看User-Agent的功能。
在面临网站反爬机制时,使用模拟浏览器发送请求是常见策略。要获取User-Agent,可以利用浏览器的开发者工具。例如,在Edge浏览器中,打开F12,进入网络标签,刷新页面,找到第一个文件并双击,底部显示的User-Agent即是所需。不同浏览器的开发者工具虽布局略有差异,但基本都提供查看User-Agent的功能。
在爬虫中有些网站会有反爬机制,简单来说就是网站看穿你就是个计算机,所以不论网站是否有反爬机制,在爬虫前使用模拟浏览器总是没错的,可是怎么获得heads中的user-agent呢?
在一个网页中,使用开发者工具,f12,然后找到网络,刷新一下,
会有一个文件,是第一个文件,双击,会出现这样的东西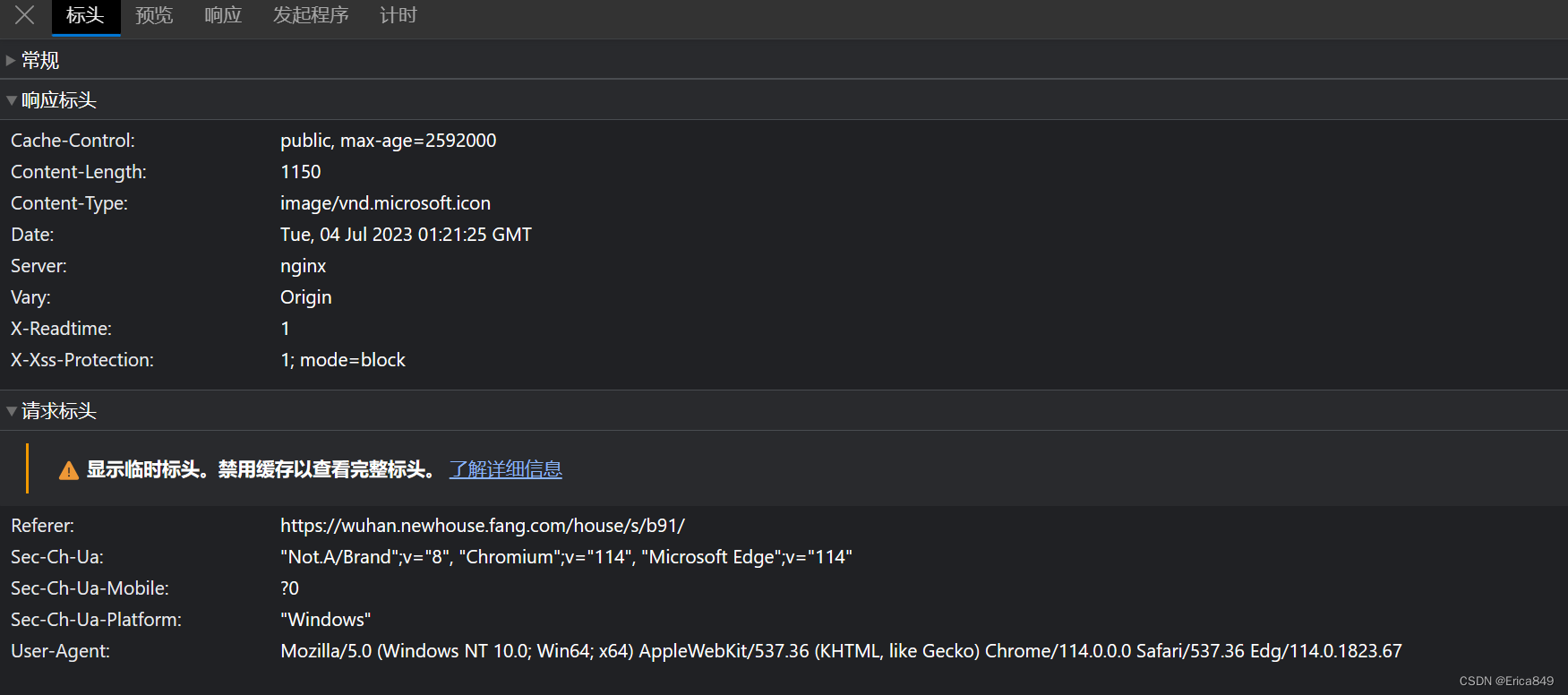
其中最下面那个user-agent就是我们的爬虫头了。每个浏览器的开发者工具结构不一样,这里以edge浏览器为例,不同浏览器大同小异,都有这个。
在爬虫中有些网站会有反爬机制,简单来说就是网站看穿你就是个计算机,所以不论网站是否有反爬机制,在爬虫前使用模拟浏览器总是没错的,可是怎么获得heads中的user-agent呢?
在一个网页中,使用开发者工具,f12,然后找到网络,刷新一下,
会有一个文件,是第一个文件,双击,会出现这样的东西
其中最下面那个user-agent就是我们的爬虫头了。每个浏览器的开发者工具结构不一样,这里以edge浏览器为例,不同浏览器大同小异,都有这个。
 1041
2709
2万+
479
1041
2709
2万+
479

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言



























