






Kubernets 集群中部署 Prometheus Grafana AlertManager
部署并配置Prometheus
最近,公司因为业务需求搭建了kubernets集群,然而对于线上业务监控是必不可少的功能。下面就将详细的搭建过程整理一下,有需要的小伙伴可以参考。共同学习。
简介
Prometheus 最初是 SoundCloud 构建的开源系统监控和报警工具,是一个独立的开源项目,于2016年加入了 CNCF 基金会,作为继 Kubernetes 之后的第二个托管项目。
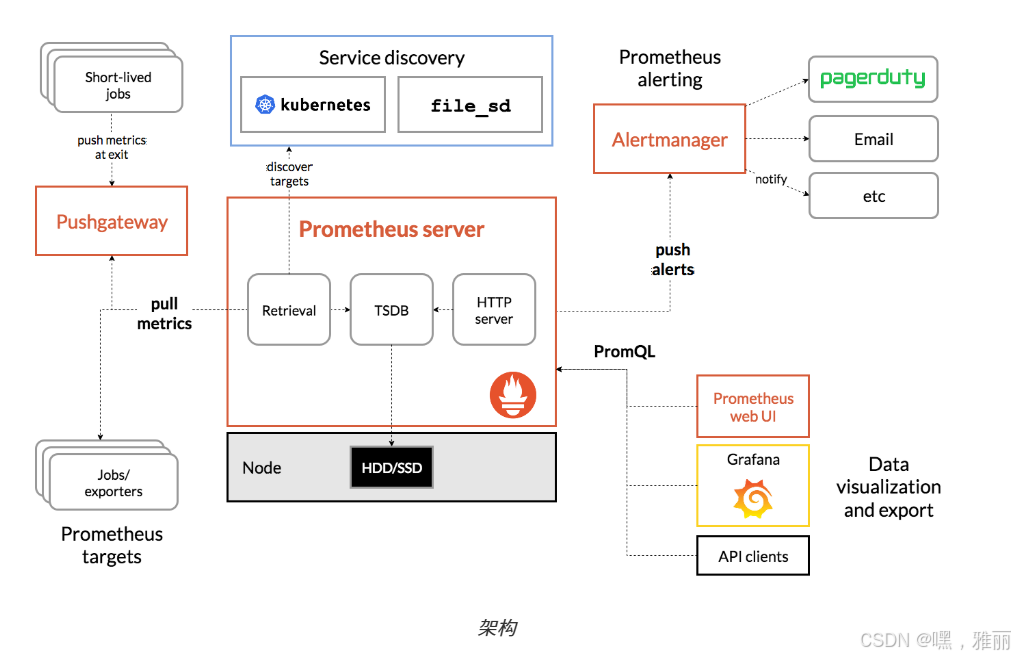
架构

资源
节点名称 | IP地址 |
| 节点名称 | IP地址 | 用途 | 备注 |
|---|---|---|---|
| k8s-master | 192.168.110.100 | 集群主节点 | |
| k8s-node1 | 192.168.110.101 | 中间件节点 | |
| k8s-node2 | 192.168.110.102 | 监控节点 |
安装
创建资源
创建命名空间
kubectl create ns kube-ops
创建配置文件
为了能够方便的管理配置文件,我们这里将 prometheus.yml 文件用 ConfigMap 的形式进行管理:(prometheus-cm.yaml)
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-config
namespace: kube-ops
data:
prometheus.yml: |
global:
scrape_interval: 15s
scrape_timeout: 15s
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
创建该资源
kubectl apply -f prometheus-cm.yaml
创建 prometheus 的 statefulset资源
vim prometheus-sts.yaml
apiVersion: apps/v1
kind: StatefulSet
metadata:
namespace: kube-ops
name: prometheus
spec:
serviceName: prometheus
replicas: 1
selector:
matchLabels:
app: prometheus
template:
metadata:
labels:
app: prometheus
spec:
nodeName: k8s-node2 # pod部署的节点
containers:
- name: prometheus
image: quay.io/prometheus/prometheus:v2.53.0
args:
- "--config.file=/etc/prometheus/prometheus.yml"
- "--storage.tsdb.path=/prometheus"
- "--storage.tsdb.retention=24h"
- "--web.enable-admin-api" # 控制对admin HTTP API的访问,其中包括删除时间序列等功能
- "--web.enable-lifecycle" # 支持热更新,直接执行localhost:9090/-/reload立即生效
ports:
- containerPort: 9090
protocol: TCP
name: http
volumeMounts:
- mountPath: "/prometheus"
subPath: prometheus
name: data
- mountPath: "/etc/prometheus"
name: config-volume
securityContext:
runAsUser: 0
volumes:
- name: data
hostPath:
type: DirectoryOrCreate
path: /data/prometheus/data #数据挂载到宿主机本地
- configMap:
name: prometheus-config
name: config-volume
创建rbac认证
这里还需要配置 rbac 认证,因为我们需要在 prometheus 中去访问 Kubernetes 的相关信息,所以我们这里管理了一个名为 prometheus 的 serviceAccount 对象:
vim prometheus-rbac.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: prometheus
namespace: kube-ops
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: prometheus
rules:
- apiGroups:
- ""
resources:
- nodes
- nodes/proxy
- nodes/stats
- nodes/log
- services
- endpoints
- pods
- configmaps
- nodes/metrics
- metrics
verbs:
- get
- list
- watch
- apiGroups:
- ""
resources:
- configmaps
- nodes/metrics
verbs:
- get
- list
- apiGroups: [""]
resources:
- pods/log
verbs: ["get"]
- apiGroups: [""]
resources:
- resourcequotas
- limitranges
verbs: ["get", "list","watch"]
- nonResourceURLs:
- /metrics
verbs:
- get
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: prometheus
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: prometheus
subjects:
- kind: ServiceAccount
name: prometheus
namespace: kube-ops
创建service
Pod 创建成功后,为了能够在外部访问到 prometheus 的 webui 服务,我们还需要创建一个 Service 对象:(prometheus-svc.yaml)
apiVersion: v1
kind: Service
metadata:
name: prometheus
namespace: kube-ops
labels:
app: prometheus
spec:
selector:
app: prometheus
type: NodePort
ports:
- name: web
port: 9090
targetPort: http
创建资源
kubectl apply -f prometheus-sts.yaml
kubectl apply -f prometheus-rbac.yaml
kubectl apply -f prometheus-svc.yaml
查看资源
$ kubectl get pod -n kube-ops
NAME READY STATUS RESTARTS AGE
prometheus-0 2/2 Running 0 134m
$ kubectl get svc -n kube-ops
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
prometheus NodePort 10.96.199.240 <none> 9090:31445/TCP 12d
查看prometheus ui页面
查看指标
scrape_duration_seconds

配置监控
监控kubernetes集群应用
使用exporter监控应用
有一些应用可能没有自带/metrics接口供 Prometheus 使用,在这种情况下,我们就需要利用 exporter 服务来为 Prometheus 提供指标数据了。比如redis是通过一个redis-exporter的服务来监控的。这里测试部署一个redis以及redis-exporter来进行监控。
vim redis-deploy.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: redis
namespace: kube-ops
spec:
selector:
matchLabels:
app: redis
template:
metadata:
annotations:
prometheus.io/scrape: "true"
prometheus.io/port: "9121"
labels:
app: redis
spec:
nodeName: k8s-node2
containers:
- name: redis
image: redis:4
resources:
requests:
cpu: 100m
memory: 100Mi
ports:
- containerPort: 6379
- name: redis-exporter
image: oliver006/redis_exporter:latest
resources:
requests:
cpu: 100m
memory: 100Mi
ports:
- containerPort: 9121
---
kind: Service
apiVersion: v1
metadata:
name: redis
namespace: kube-ops
spec:
selector:
app: redis
ports:
- name: redis
port: 6379
targetPort: 6379
- name: prom
port: 9121
targetPort: 9121
创建
kubectl apply -f redis-deploy.yaml
查看创建的服务
[root@k8s-master redis]# kubectl get pod -n kube-ops
NAME READY STATUS RESTARTS AGE
redis-76fb76f449-89kgs 2/2 Running 4 (4d22h ago) 9d
查看service服务
kubectl get svc -n kube-ops
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
redis ClusterIP 10.96.56.2 <none> 6379/TCP,9121/TCP 12d
测试是否可以访问
curl http://10.96.56.2:9121/metrics
# HELP go_gc_duration_seconds A summary of the pause duration of garbage collection cycles.
# TYPE go_gc_duration_seconds summary
go_gc_duration_seconds{quantile="0"} 2.4326e-05
go_gc_duration_seconds{quantile="0.25"} 3.9325e-05
go_gc_duration_seconds{quantile="0.5"} 5.2849e-05
go_gc_duration_seconds{quantile="0.75"} 8.6323e-05
go_gc_duration_seconds{quantile="1"} 0.000360808
go_gc_duration_seconds_sum 0.263977277
go_gc_duration_seconds_count 3499
配置prometheus-cm.yaml
- job_name: 'redis-exporter'
static_configs:
- targets: ['redis:9121']
这里targets的配置因为redis和prometheus在同一个namespace下面,所以直接可以配置成redis,如果不在同一个namespace下面,则配置成 redis.namespace.svc.cluster.local即服务名称.命名空间名称…svc.cluster.local

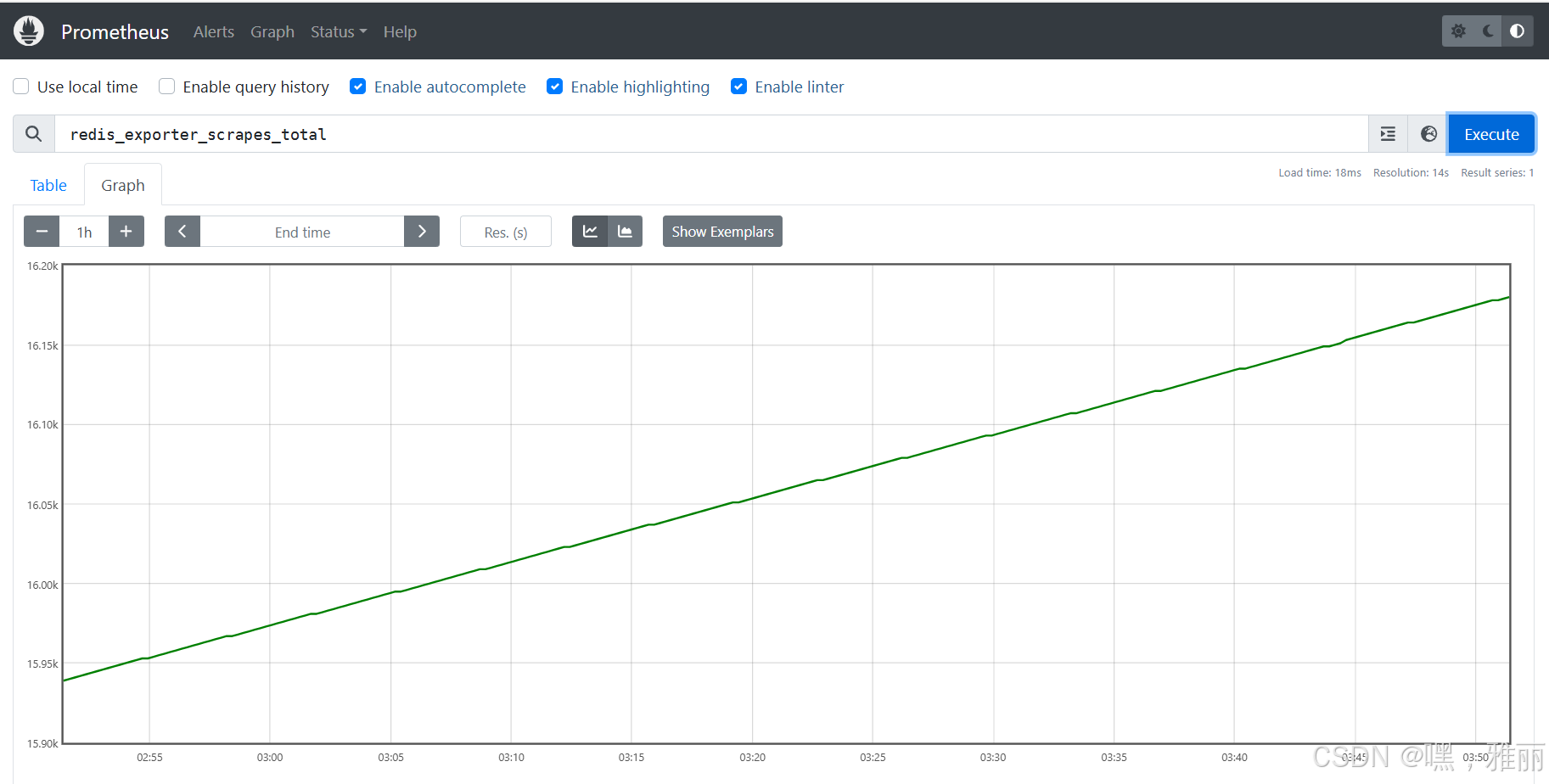
选择一个指标redis_exporter_scrapes_total,看到一个图表
监控集群节点
通过 Prometheus 来采集节点的监控指标数据,可以通过node_exporter来获取抓取用于采集服务器节点的各种运行指标。
vim node-exporter-ds.yaml
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: node-exporter
namespace: kube-ops
labels:
name: node-exporter
spec:
selector:
matchLabels:
name: node-exporter
template:
metadata:
labels:
name: node-exporter
spec:
hostPID: true
hostIPC: true
hostNetwork: true
containers:
- name: node-exporter
image: quay.io/prometheus/node-exporter:v1.8.1
ports:
- containerPort: 9100
resources:
requests:
cpu: 0.15
securityContext:
privileged: true
args:
- --path.procfs
- /host/proc
- --path.sysfs
- /host/sys
- --collector.filesystem.ignored-mount-points
- '"^/(sys|proc|dev|host|etc)($|/)"'
volumeMounts:
- name: dev
mountPath: /host/dev
- name: proc
mountPath: /host/proc
- name: sys
mountPath: /host/sys
- name: rootfs
mountPath: /rootfs
tolerations:
- key: "node-role.kubernetes.io/master"
operator: "Exists"
effect: "NoSchedule"
volumes:
- name: proc
hostPath:
path: /proc
- name: dev
hostPath:
path: /dev
- name: sys
hostPath:
path: /sys
- name: rootfs
hostPath:
path: /
创建资源
kubectl apply -f node-exporter-ds.yaml
查看资源
$ kubectl get pod -n kube-ops
NAME READY STATUS RESTARTS AGE
node-exporter-5l7z7 1/1 Running 0 10d
node-exporter-cgjt8 1/1 Running 0 10d
主节点没有监控,查看主节点信息发现主节点有污点,需要去除污点
kubectl taint nodes k8s-master node-role.kubernetes.io/control-plane:NoSchedule-
再次查看 ,主节点已经有了
$ kubectl get pod -n kube-ops
NAME READY STATUS RESTARTS AGE
node-exporter-5264z 1/1 Running 0 10d
node-exporter-5l7z7 1/1 Running 0 10d
node-exporter-cgjt8 1/1 Running 0 10d
配置监控 vim prometheus-cm.yaml
- job_name: 'kubernetes-nodes'
kubernetes_sd_configs:
- role: node
配置重启以后发现没有监控到node,查看日志发现有报错
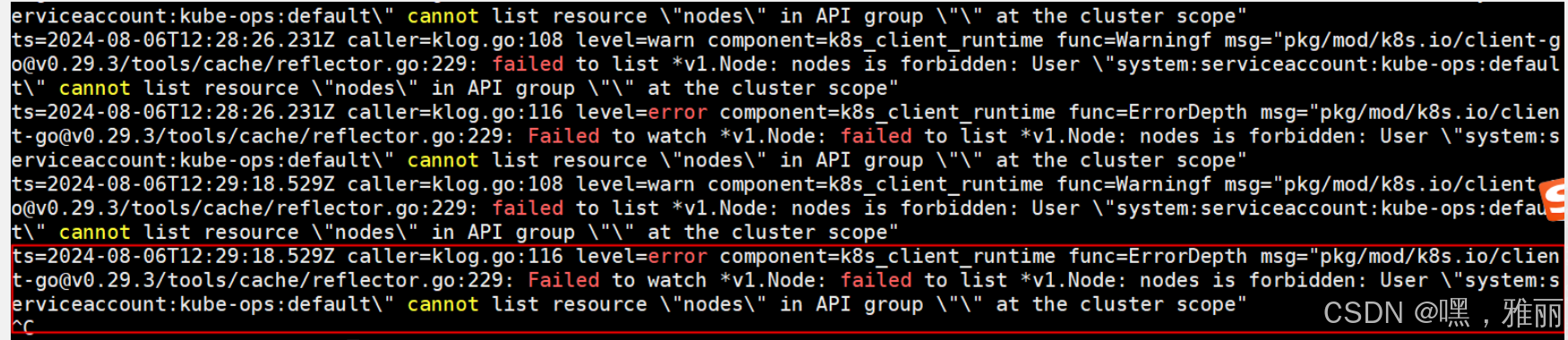
这是因为没有权限,需要创建ClusterRole和ClusterRoleBinding
vim pro-node-reader.yaml
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: prometheus-node-reader
rules:
- apiGroups: [""]
resources: ["nodes"]
verbs: ["get", "list", "watch"]
vim pro-node-reader-binding.yaml
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: prometheus-node-reader-binding
subjects:
- kind: ServiceAccount
name: default
namespace: kube-ops
roleRef:
kind: ClusterRole
name: prometheus-node-reader
apiGroup: rbac.authorization.k8s.io
创建资源
kubectl apply -f pro-node-reader.yaml
kubectl apply -f pro-node-reader-binding.yaml
重启prometheus,再次查看发现
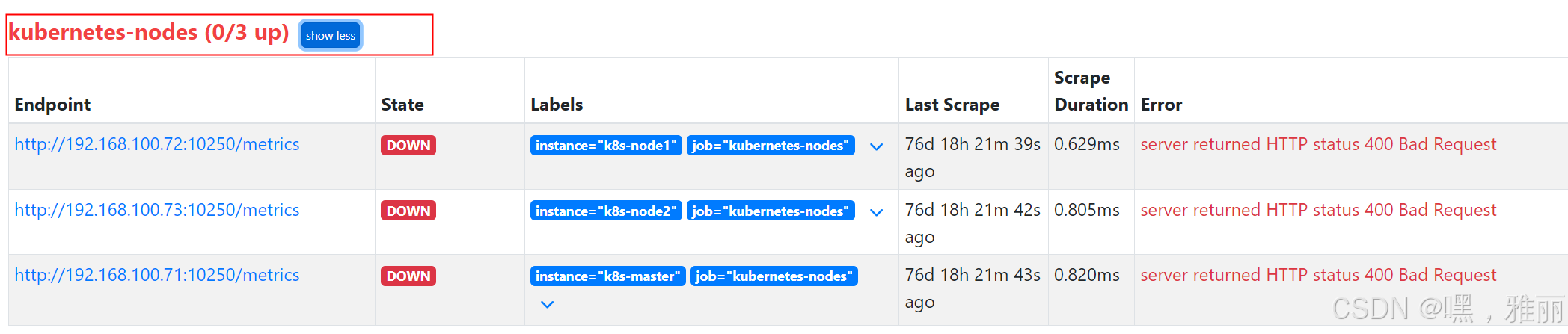
这个是因为prometheus去发现Node模式的服务的时候,访问的端口默认是10250,而现在该端口下面已经没有/metrics指标数据了,所以我们这里应该将10250替换成9100.具体配置如下:
- job_name: 'kubernetes-nodes'
kubernetes_sd_configs:
- role: node
relabel_configs:
- source_labels: [__address__]
regex: '(.*):10250'
replacement: '${1}:9100'
target_label: __address__
action: replace
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
重新更新配置并重启prometheus,再次查看监控,已经正常

监控kubernetes常用资源对象
容器监控
容器监控使用 kubelet 内置组件cAdvisor,不需要单独去安装,cAdvisor的数据路径为/api/v1/nodes//proxy/metrics,同样我们这里使用 node 的服务发现模式,因为每一个节点下面都有 kubelet,自然都有cAdvisor采集到的数据指标,配置如下:
- job_name: 'kubernetes-cadvisor'
kubernetes_sd_configs:
- role: node
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- target_label: __address__
replacement: kubernetes.default.svc:443
- source_labels: [__meta_kubernetes_node_name]
regex: (.+)
target_label: __metrics_path__
replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor
查看
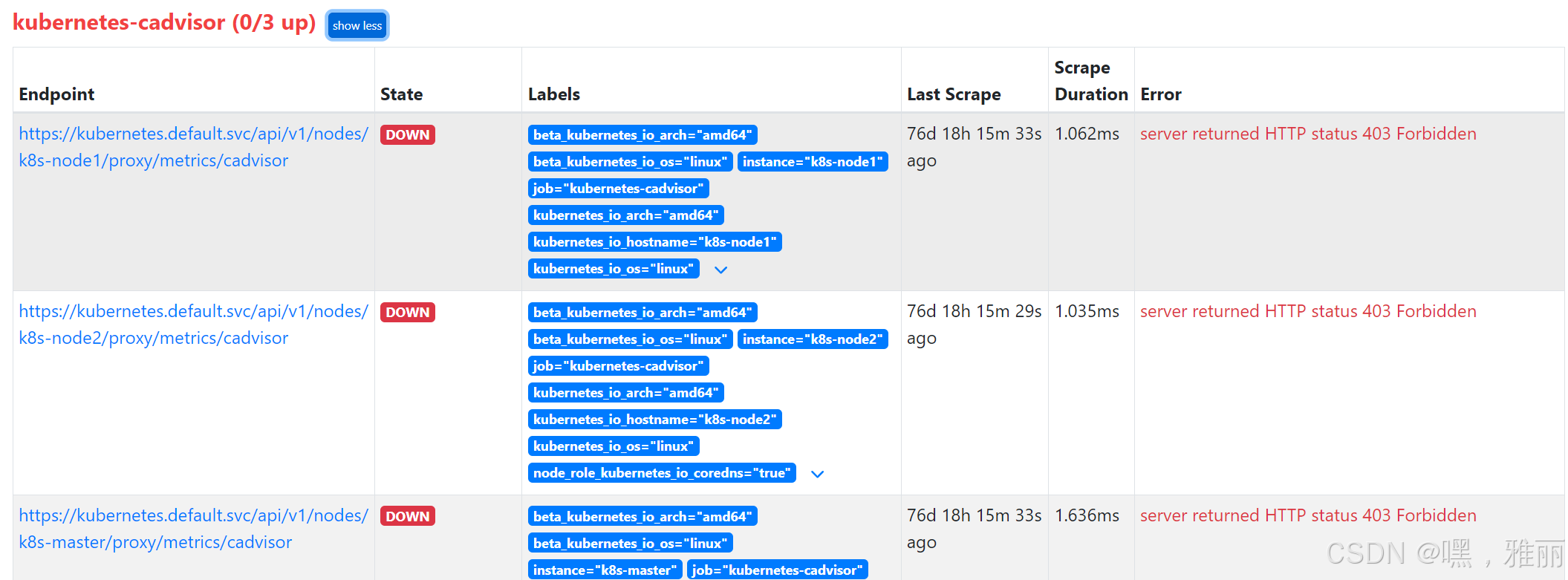
没有权限,需要创建认证
wim pro-cadvisor-reader.yaml
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: prometheus-cadvisor-reader
rules:
- apiGroups: [""]
resources:
- nodes/proxy
verbs: ["get"]
vim pro-cadvisor-reader-binding.yaml
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: prometheus-cadvisor-reader-binding
subjects:
- kind: ServiceAccount
name: default
namespace: kube-ops
roleRef:
kind: ClusterRole
name: prometheus-cadvisor-reader
apiGroup: rbac.authorization.k8s.io
kubectl apply -f pro-cadvisor-reader.yaml
kubectl apply -f pro-cadvisor-reader-binding.yaml
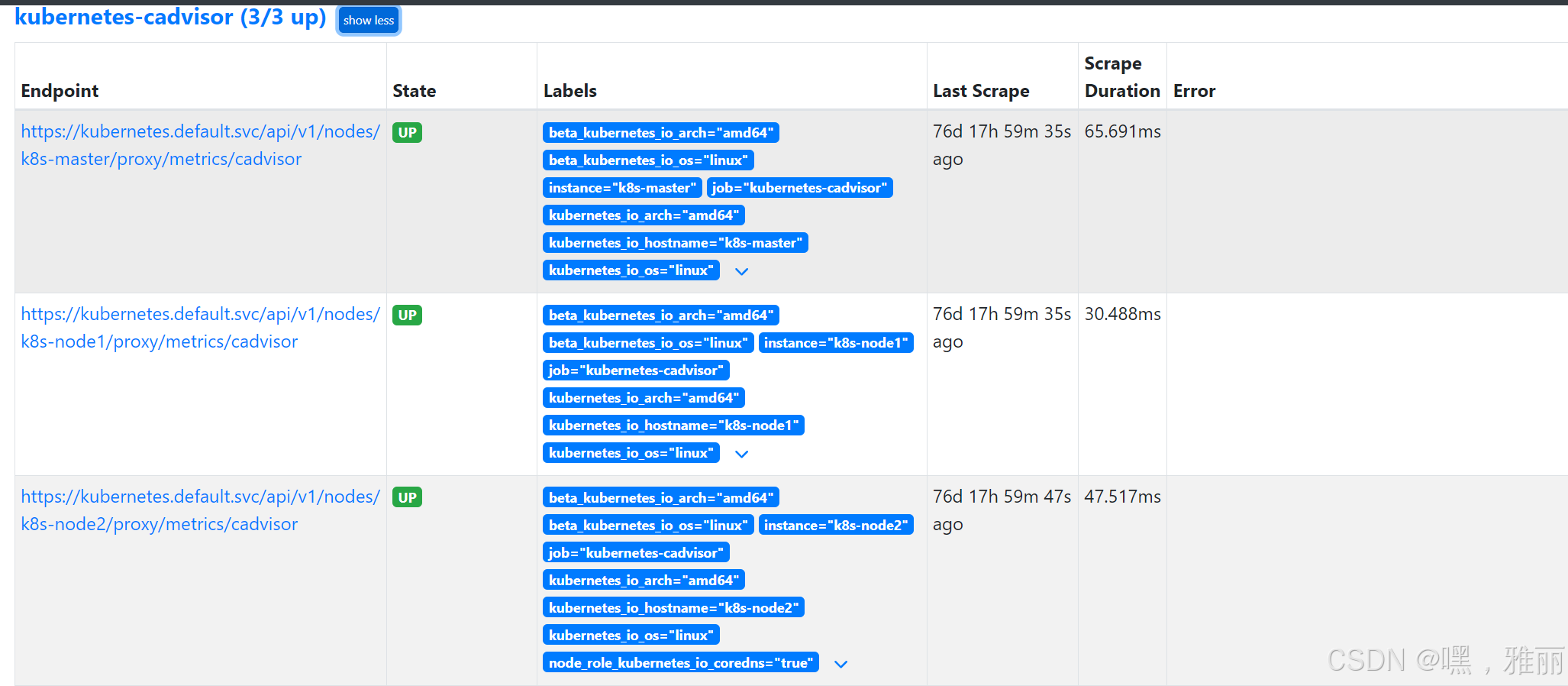
监控kubernetes-apiservers
apiserver 作为 Kubernetes 最核心的组件,当然他的监控也是非常有必要的,对于 apiserver 的监控我们可以直接通过 kubernetes 的 Service 来获取:
[root@k8s-master prometheus]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 115d
上面这个 Service 就是我们集群的 apiserver 在集群内部的 Service 地址,要自动发现 Service 类型的服务,我们就需要用到 role 为 Endpoints 的 kubernetes_sd_configs,我们可以在 ConfigMap 对象中添加上一个 Endpoints 类型的服务的监控任务:
- job_name: 'kubernetes-apiservers'
kubernetes_sd_configs:
- role: endpoints
上面这个任务是定义的一个类型为endpoints的kubernetes_sd_configs,添加到 Prometheus 的 ConfigMap 的配置文件中,然后更新配置:
$ kubectl delete -f prome-cm.yaml
$ kubectl create -f prome-cm.yaml
$ # 隔一会儿执行reload操作
$ kubectl get svc -n kube-ops
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
prometheus NodePort 10.102.74.90 <none> 9090:30358/TCP 14d
更新完成后,我们再去查看 Prometheus 的 Dashboard 的 target 页面:
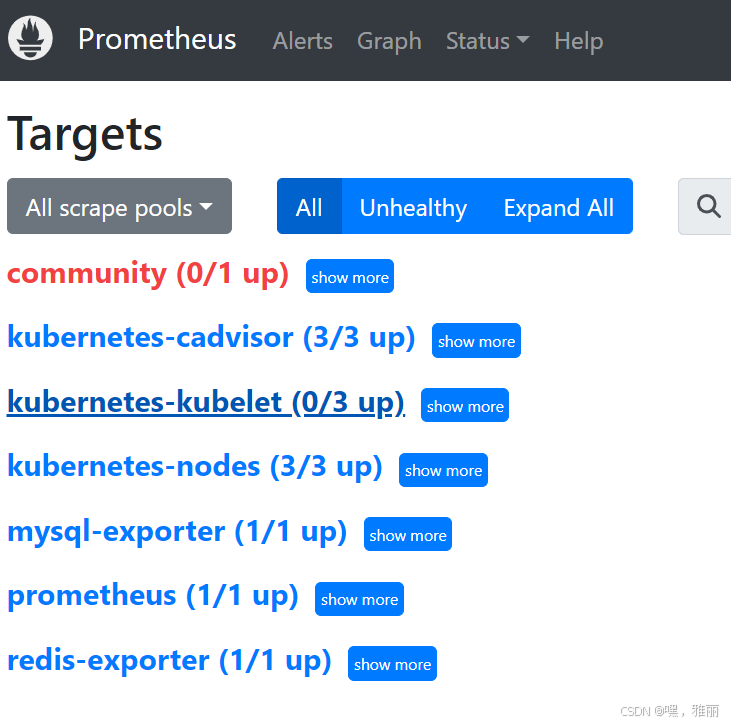
发现没有监控到,查看日志
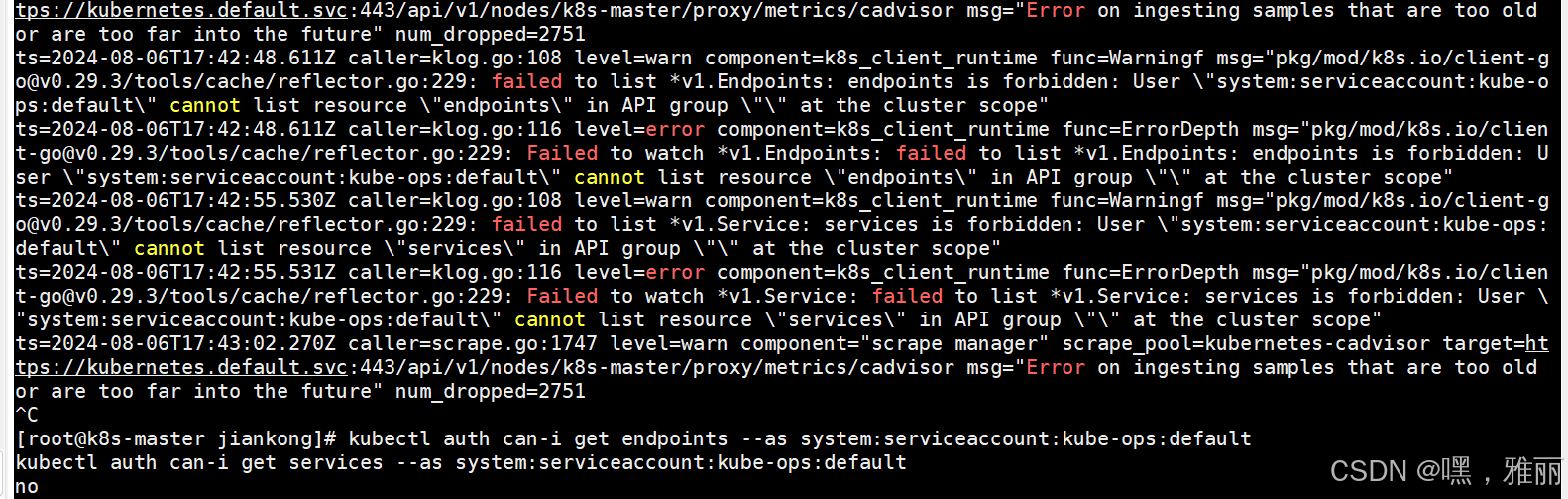
没有权限
kubectl auth can-i get endpoints --as system:serviceaccount:kube-ops:default
kubectl auth can-i get services --as system:serviceaccount:kube-ops:default
创建认证
vim pro-endpoints-services-reader.yaml
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: prometheus-endpoints-services-reader
rules:
- apiGroups: [""]
resources:
- nodes
- nodes/proxy
- nodes/stats
- nodes/log
- services
- endpoints
- pods
- configmaps
- nodes/metrics
- metrics
verbs: ["get", "list", "watch"]
- apiGroups:
- ''
resources:
- configmaps
- nodes/metrics
verbs:
- get
- nonResourceURLs:
- /metrics
verbs:
- get
vim pro-endpoints-services-reader-binding.yaml
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: prometheus-endpoints-services-reader-binding
subjects:
- kind: ServiceAccount
name: default
namespace: kube-ops
roleRef:
kind: ClusterRole
name: prometheus-endpoints-services-reader
apiGroup: rbac.authorization.k8s.io
创建
kubectl apply -f pro-endpoints-services-reader.yaml
kubectl apply -f pro-endpoints-services-reader-binding.yaml
再次查看

我们可以看到 kubernetes-apiservers 下面出现了很多实例,这是因为这里我们使用的是 Endpoints 类型的服务发现,所以 Prometheus 把所有的 Endpoints 服务都抓取过来了,同样的,上面我们需要的服务名为kubernetes这个 apiserver 的服务也在这个列表之中,那么我们应该怎样来过滤出这个服务来呢?还记得上节课的relabel_configs吗?没错,同样我们需要使用这个配置,只是我们这里不是使用replace这个动作了,而是keep,就是只把符合我们要求的给保留下来,哪些才是符合我们要求的呢?我们可以把鼠标放置在任意一个 target 上,可以查看到Before relabeling里面所有的元数据,比如我们要过滤的服务是 default 这个 namespace 下面,服务名为 kubernetes 的元数据,所以这里我们就可以根据对应的__meta_kubernetes_namespace和__meta_kubernetes_service_name这两个元数据来 relabel
- job_name: 'kubernetes-apiservers'
kubernetes_sd_configs:
- role: endpoints
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]
action: keep
regex: default;kubernetes;https

监控service
上面的 apiserver 实际上是一种特殊的 Service,现在我们同样来配置一个任务用来专门发现普通类型的 Service:
- job_name: 'kubernetes-service-endpoints'
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme]
action: replace
target_label: __scheme__
regex: (https?)
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port]
action: replace
target_label: __address__
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_service_name]
action: replace
target_label: kubernetes_name
注意我们这里在relabel_configs区域做了大量的配置,特别是第一个保留__meta_kubernetes_service_annotation_prometheus_io_scrape为true的才保留下来,这就是说要想自动发现集群中的 Service,就需要我们在 Service 的annotation区域添加prometheus.io/scrape=true的声明,现在我们先将上面的配置更新,查看下效果:

我们可以看到kubernetes-service-endpoints这一个任务下面只发现了一个服务,这是因为我们在relabel_configs中过滤了 annotation 有prometheus.io/scrape=true的 Service,而现在我们系统中只有这样一个服务符合要求,所以只出现了一个实例。
现在我们在之前创建的 redis 这个 Service 中添加上prometheus.io/scrape=true这个 annotation:(prome-redis-exporter.yaml)
kind: Service
apiVersion: v1
metadata:
name: redis
namespace: kube-ops
annotations:
prometheus.io/scrape: "true"
prometheus.io/port: "9121"
spec:
selector:
app: redis
ports:
- name: redis
port: 6379
targetPort: 6379
- name: prom
port: 9121
targetPort: 9121
由于 redis 服务的 metrics 接口在9121这个 redis-exporter 服务上面,所以我们还需要添加一个prometheus.io/port=9121这样的annotations,然后更新这个 Service:
$ kubectl apply -f prome-redis-exporter.yaml
deployment.extensions "redis" unchanged
service "redis" changed

这样以后我们有了新的服务,服务本身提供了/metrics接口,我们就完全不需要用静态的方式去配置了,到这里我们就可以将之前配置的 redis 的静态配置去掉了。
kube-state-metrics
上面我们配置了自动发现 Service(Pod也是一样的)的监控,但是这些监控数据都是应用内部的监控,需要应用本身提供一个/metrics接口,或者对应的 exporter 来暴露对应的指标数据,但是在 Kubernetes 集群上 Pod、DaemonSet、Deployment、Job、CronJob 等各种资源对象的状态也需要监控,这也反映了使用这些资源部署的应用的状态。但通过查看前面从集群中拉取的指标(这些指标主要来自 apiserver 和 kubelet 中集成的 cAdvisor),并没有具体的各种资源对象的状态指标。对于 Prometheus 来说,当然是需要引入新的 exporter 来暴露这些指标,Kubernetes 提供了一个kube-state-metrics就是我们需要的。
kube-state-metrics 已经给出了在 Kubernetes 部署的 manifest 定义文件,我们直接将代码 Clone 到集群中(能用 kubectl 工具操作就行):
$ git clone https://github.com/kubernetes/kube-state-metrics.git
$ cd kube-state-metrics/kubernetes
$ kubectl create -f .
clusterrolebinding.rbac.authorization.k8s.io "kube-state-metrics" created
clusterrole.rbac.authorization.k8s.io "kube-state-metrics" created
deployment.apps "kube-state-metrics" created
rolebinding.rbac.authorization.k8s.io "kube-state-metrics" created
role.rbac.authorization.k8s.io "kube-state-metrics-resizer" created
serviceaccount "kube-state-metrics" created
service "kube-state-metrics" created
将 kube-state-metrics 部署到 Kubernetes 上之后,就会发现 Kubernetes 集群中的 Prometheus 会在kubernetes-service-endpoints 这个 job 下自动服务发现 kube-state-metrics,并开始拉取 metrics,这是因为部署 kube-state-metrics 的 manifest 定义文件 kube-state-metrics-service.yaml 对 Service 的定义包含prometheus.io/scrape: 'true’这样的一个annotation,因此 kube-state-metrics 的 endpoint 可以被 Prometheus 自动服务发现。
配置应用监控
需要安装blackbox-exporter 去监控应用返回的状态
创建配置文件
vim blackbox-configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: blackbox-exporter
namespace: kube-ops
labels:
app: blackbox-exporter
data:
blackbox.yml: |-
modules:
http_2xx:
prober: http
http:
valid_status_codes: [200,204]
no_follow_redirects: false
preferred_ip_protocol: ip4
ip_protocol_fallback: false
httpNoRedirect4ssl:
prober: http
http:
valid_status_codes: [200,204,301,302,303]
no_follow_redirects: true
preferred_ip_protocol: ip4
ip_protocol_fallback: false
http200igssl:
prober: http
http:
valid_status_codes:
- 200
tls_config:
insecure_skip_verify: true
http_4xx:
prober: http
http:
valid_status_codes: [401,403,404]
preferred_ip_protocol: ip4
ip_protocol_fallback: false
http_5xx:
prober: http
http:
valid_status_codes: [500,502]
preferred_ip_protocol: ip4
ip_protocol_fallback: false
http_post_2xx:
prober: http
http:
method: POST
icmp:
prober: icmp
tcp_connect:
prober: tcp
ssh_banner:
prober: tcp
tcp:
query_response:
- expect: "^SSH-2.0-"
- send: "SSH-2.0-blackbox-ssh-check"
创建blackbox 的deploy
vim blackbox-deploy.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: blackbox-exporter
namespace: kube-ops
spec:
replicas: 1
selector:
matchLabels:
app: blackbox-exporter
template:
metadata:
labels:
app: blackbox-exporter
spec:
containers:
- name: blackbox-exporter
image: quay.io/prometheus/blackbox-exporter:v0.25.0
imagePullPolicy: IfNotPresent
ports:
- containerPort: 9115
readinessProbe:
tcpSocket:
port: 9115
initialDelaySeconds: 10
timeoutSeconds: 5
resources:
requests:
memory: 50Mi
cpu: 100m
limits:
memory: 60Mi
cpu: 200m
volumeMounts:
- name: config
mountPath: /etc/blackbox_exporter
args:
- '--config.file=/etc/blackbox_exporter/blackbox.yml'
- '--web.listen-address=:9115'
volumes:
- name: config
configMap:
name: blackbox-exporter
vim blackbox-svc.yaml
apiVersion: v1
kind: Service
metadata:
labels:
name: blackbox-exporter
name: blackbox-exporter
namespace: kube-ops
spec:
ports:
- name: blackbox-exporter
protocol: TCP
port: 9115
targetPort: 9115
selector:
app: blackbox-exporter
创建
kubectl apply -f blackbox-configmap.yaml
kubectl apply -f blackbox-deploy.yaml
kubectl apply -f blackbox-svc.yaml
查看

配置prometheus.yaml
- job_name: 'blackbox_http_2xx' # 配置get请求检测
scrape_interval: 30s
metrics_path: /probe
params:
module: [http_2xx]
static_configs:
- targets: ['https://www.test.com/zhgd_api/worksite/']
labels:
instance: user_status
group: '测试项目后端监控地址'
relabel_configs:
- source_labels: [__address__]
target_label: __param_target
- source_labels: [__param_target]
target_label: instance
- target_label: __address__
replacement: blackbox-exporter:9115 # blackbox-exporter 服务所在的机器和端口
部署grafana
grafana 是一个可视化面板,有着非常漂亮的图表和布局展示,功能齐全的度量仪表盘和图形编辑器,支持 Graphite、zabbix、InfluxDB、Prometheus、OpenTSDB、Elasticsearch 等作为数据源,比 Prometheus 自带的图表展示功能强大太多,更加灵活,有丰富的插件,功能更加强大,接下来我们就来直接安装。
vim grafana-deploy.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: grafana
namespace: kube-ops
labels:
app: grafana
spec:
revisionHistoryLimit: 10
selector:
matchLabels:
app: grafana
template:
metadata:
labels:
app: grafana
spec:
nodeName: k8s-node2
containers:
- name: grafana
image: grafana/grafana:11.1.0
imagePullPolicy: IfNotPresent
ports:
- containerPort: 3000
name: grafana
env:
- name: GF_SECURITY_ADMIN_USER
value: admin
- name: GF_SECURITY_ADMIN_PASSWORD
value: admin321
readinessProbe:
failureThreshold: 10
httpGet:
path: /api/health
port: 3000
scheme: HTTP
initialDelaySeconds: 60
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 30
livenessProbe:
failureThreshold: 3
httpGet:
path: /api/health
port: 3000
scheme: HTTP
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 1
resources:
limits:
cpu: 100m
memory: 256Mi
requests:
cpu: 100m
memory: 256Mi
volumeMounts:
- mountPath: /var/lib/grafana
name: storage
- name: localtime
mountPath: /etc/localtime
readOnly: true
securityContext:
fsGroup: 472
runAsUser: 472
volumes:
- name: storage
hostPath:
type: DirectoryOrCreate
path: /data/grafana/data
- name: localtime
hostPath:
path: /etc/localtime
创建
kubectl apply -f grafana-deploy.yaml
查看状态
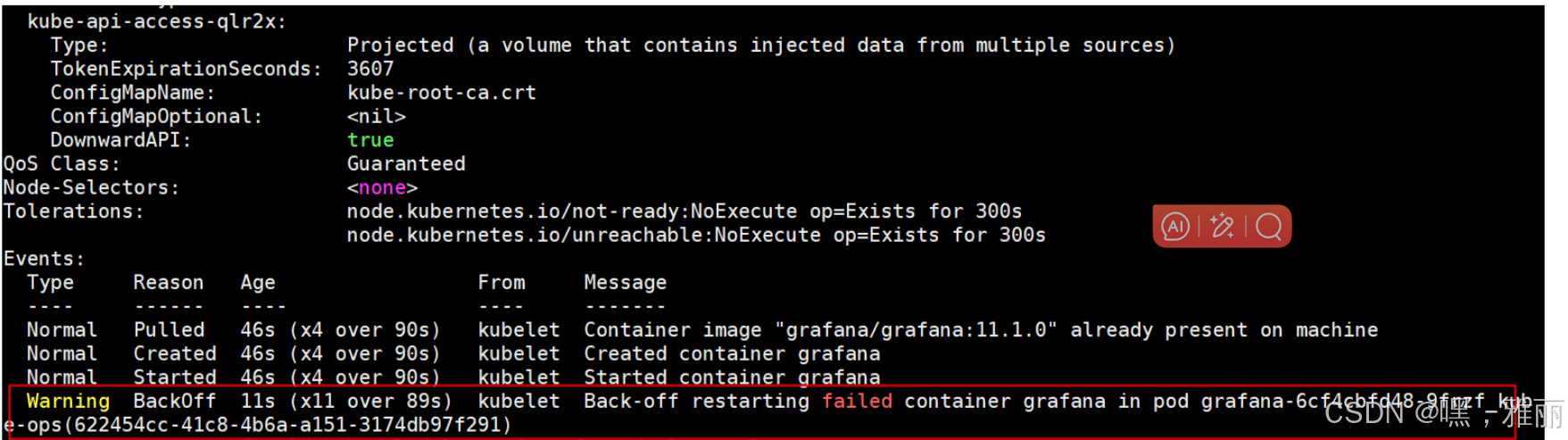
挂载目录没有权限,添加权限

启动正常
我们需要对外暴露 grafana 这个服务,所以我们需要一个对应的 Service 对象,当然用 NodePort 或者再建立一个 ingress 对象都是可行的:(grafana-svc.yaml)
vim grafana-svc.yaml
apiVersion: v1
kind: Service
metadata:
name: grafana
namespace: kube-ops
labels:
app: grafana
spec:
type: NodePort
ports:
- port: 3000
selector:
app: grafana
查看grafana控制台
由于上面我们配置了管理员的,所以第一次打开的时候会跳转到登录界面,然后就可以用上面我们配置的两个环境变量的值来进行登录了,登录完成后就可以进入到下面 Grafana 的首页:
输入用户名密码:admin/admin123
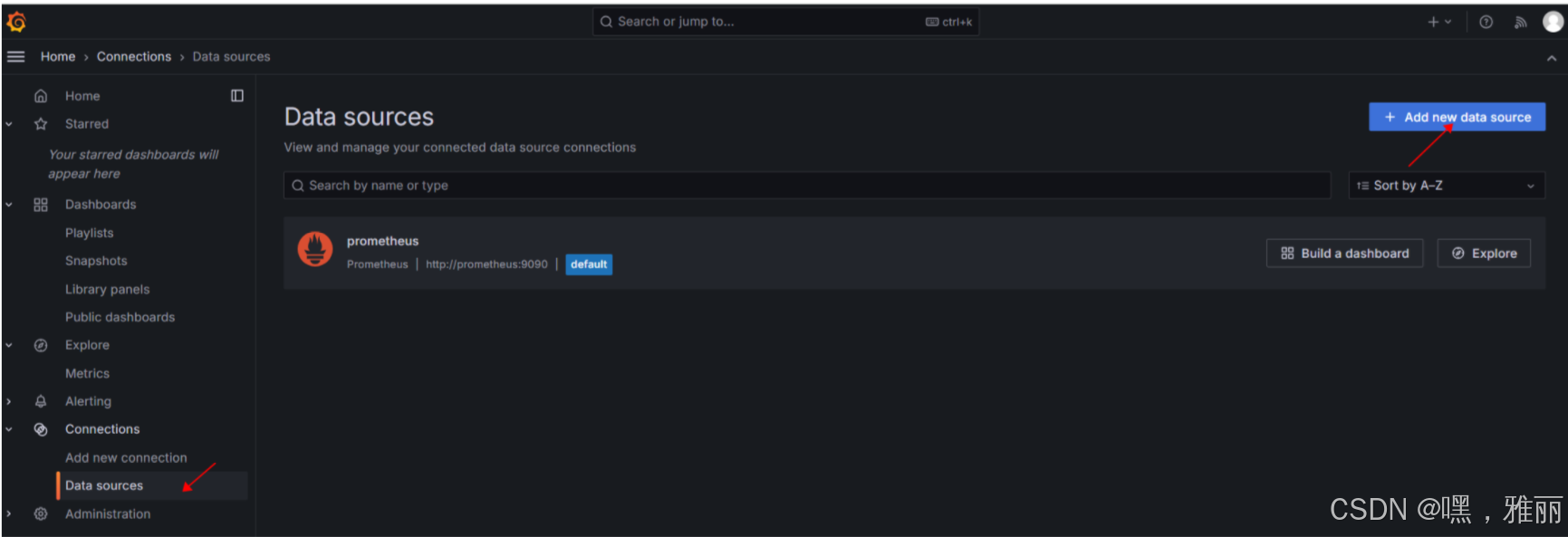
配置数据源
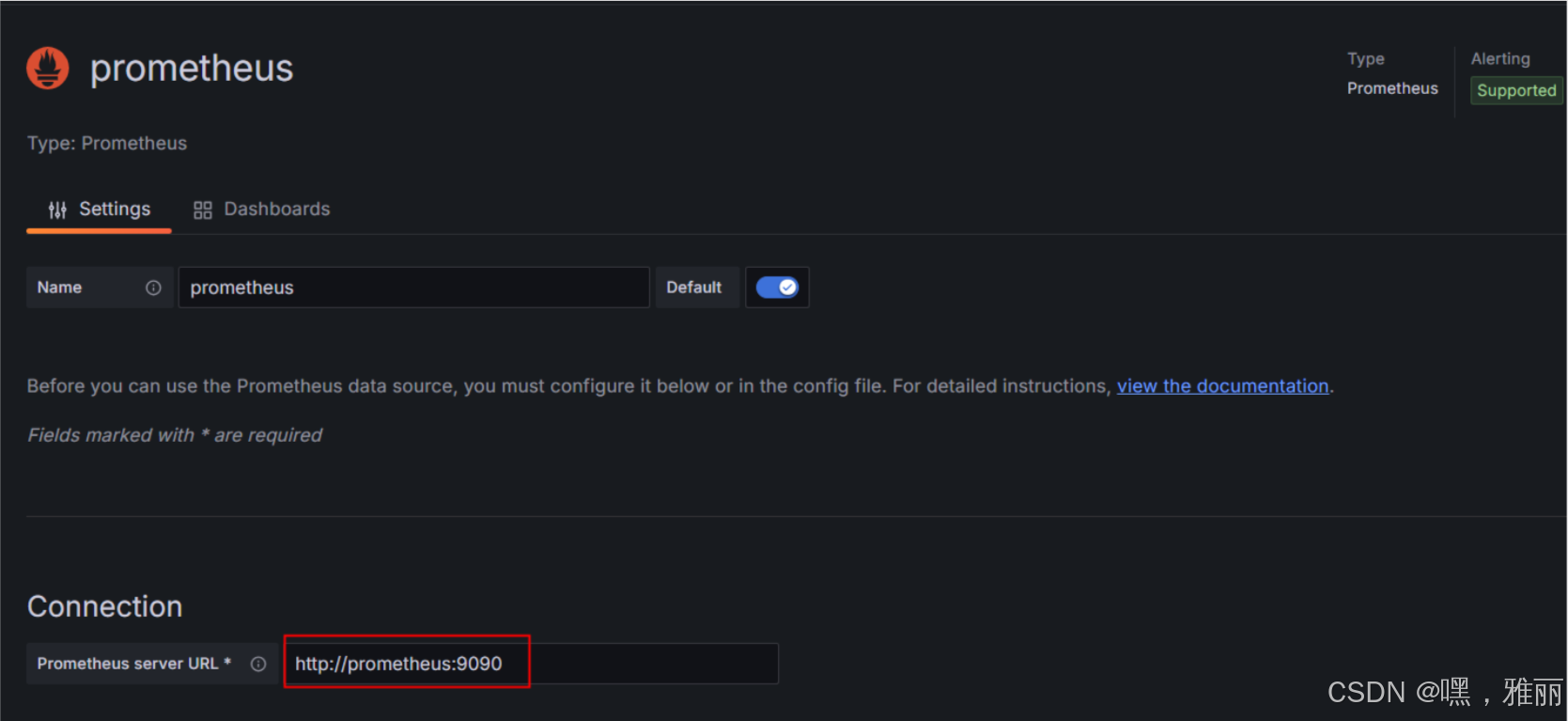
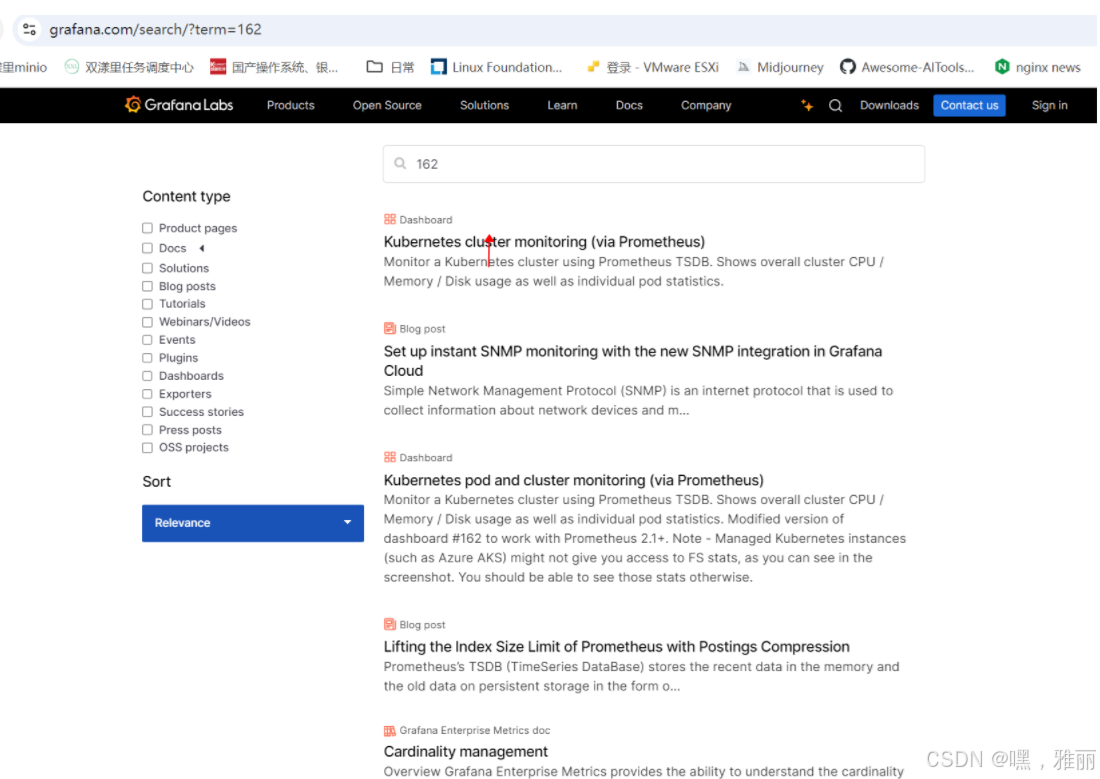
添加 Dashboard ,下载监控模板
https://grafana.com/grafana/dashboards/
搜索162号
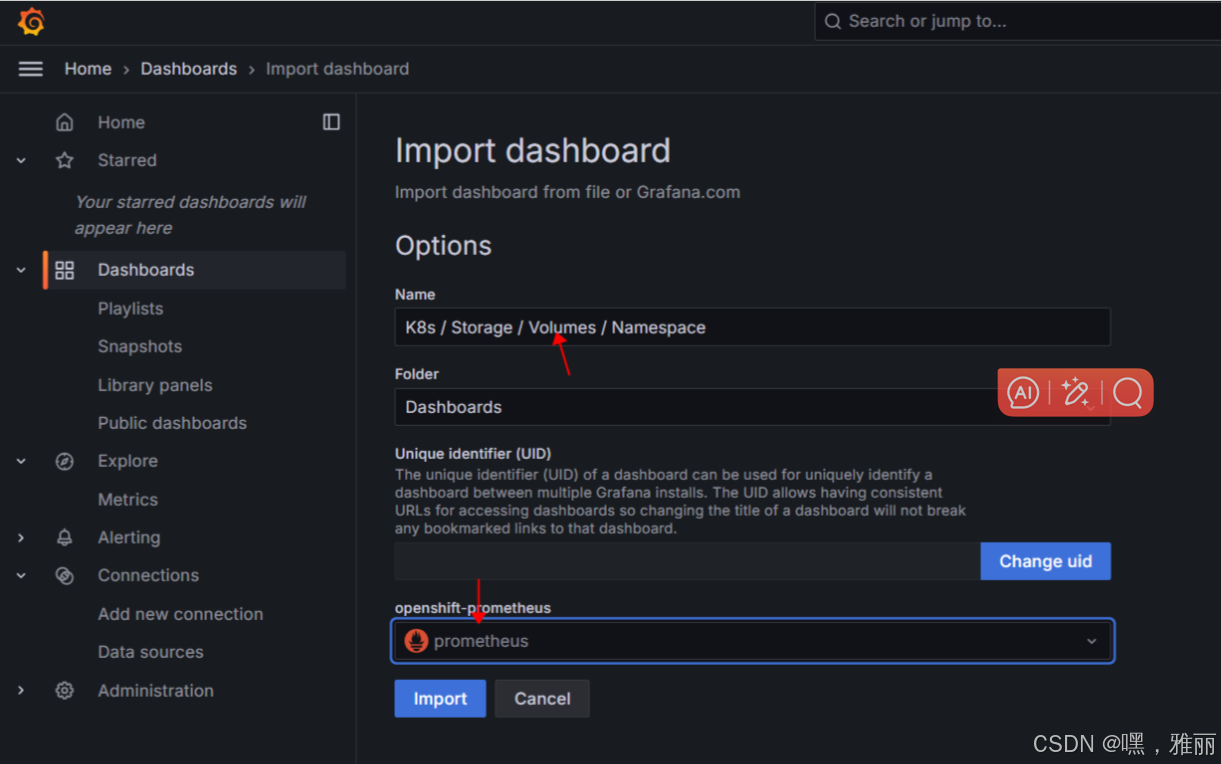
导入模板
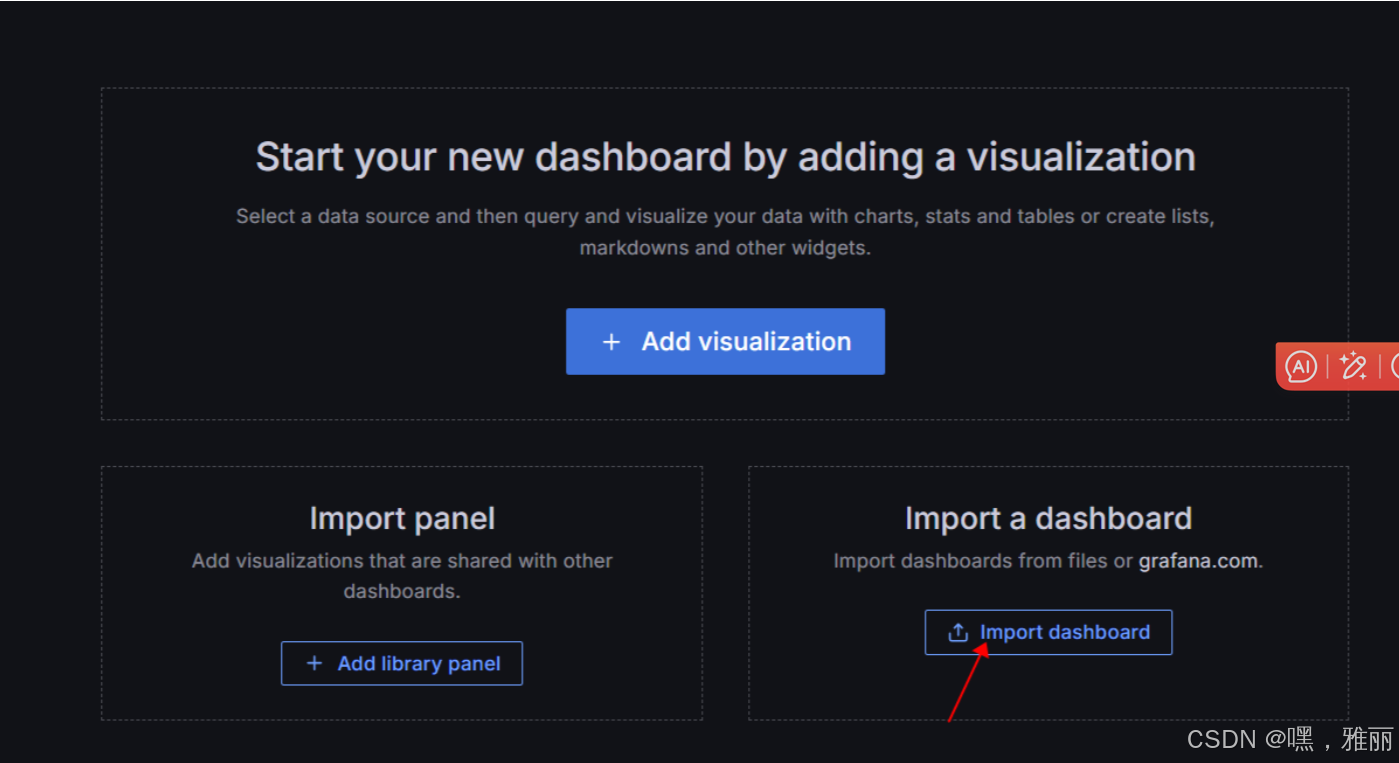
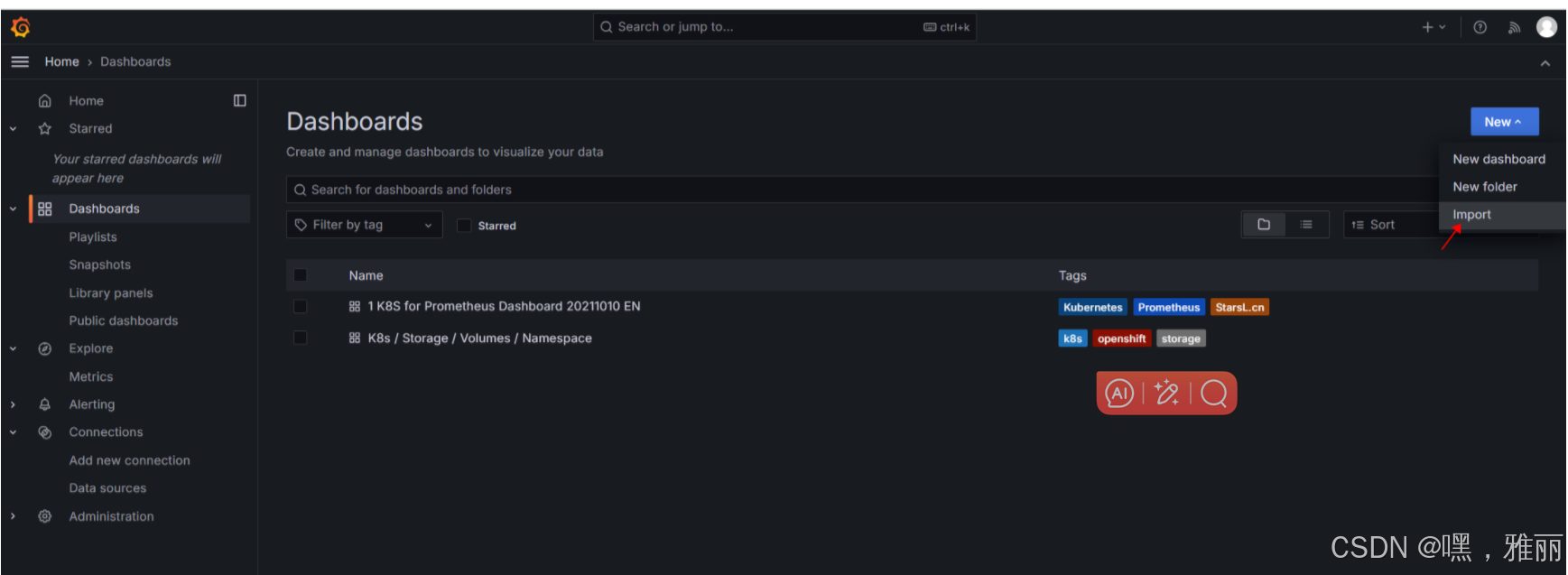
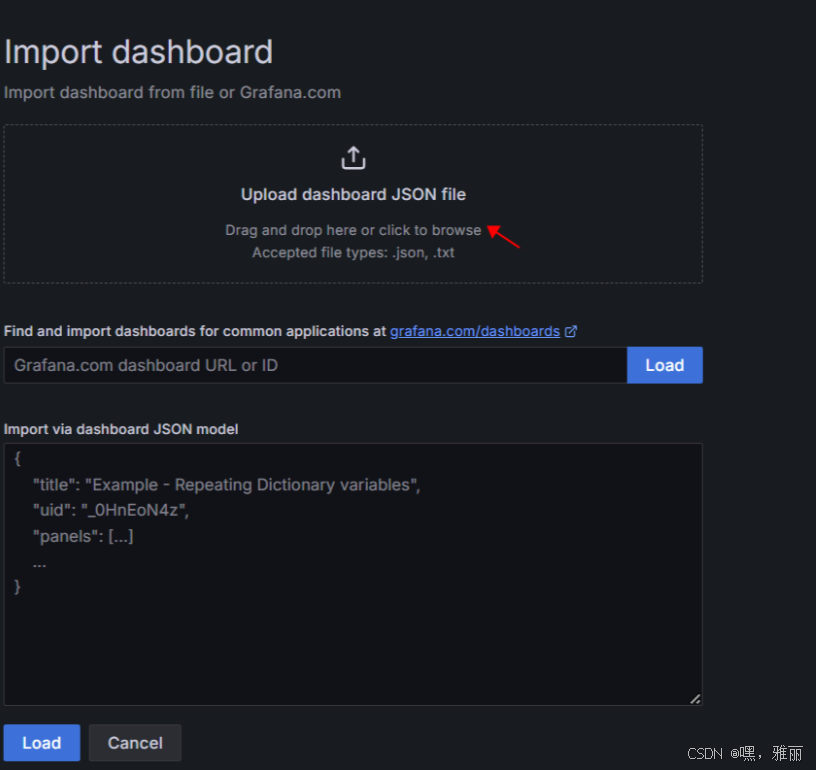
选择下载好的模板
我们可以看到 dashboard 页面上出现了很多漂亮的图表,但是看上去数据不正常,这是因为这个 dashboard 里面需要的数据指标名称和我们 Prometheus 里面采集到的数据指标不一致造成的,比如,第一个Cluster memory usage(集群内存使用情况),我们可以点击标题 -> Edit,进入编辑这个图表的编辑页面:

编辑
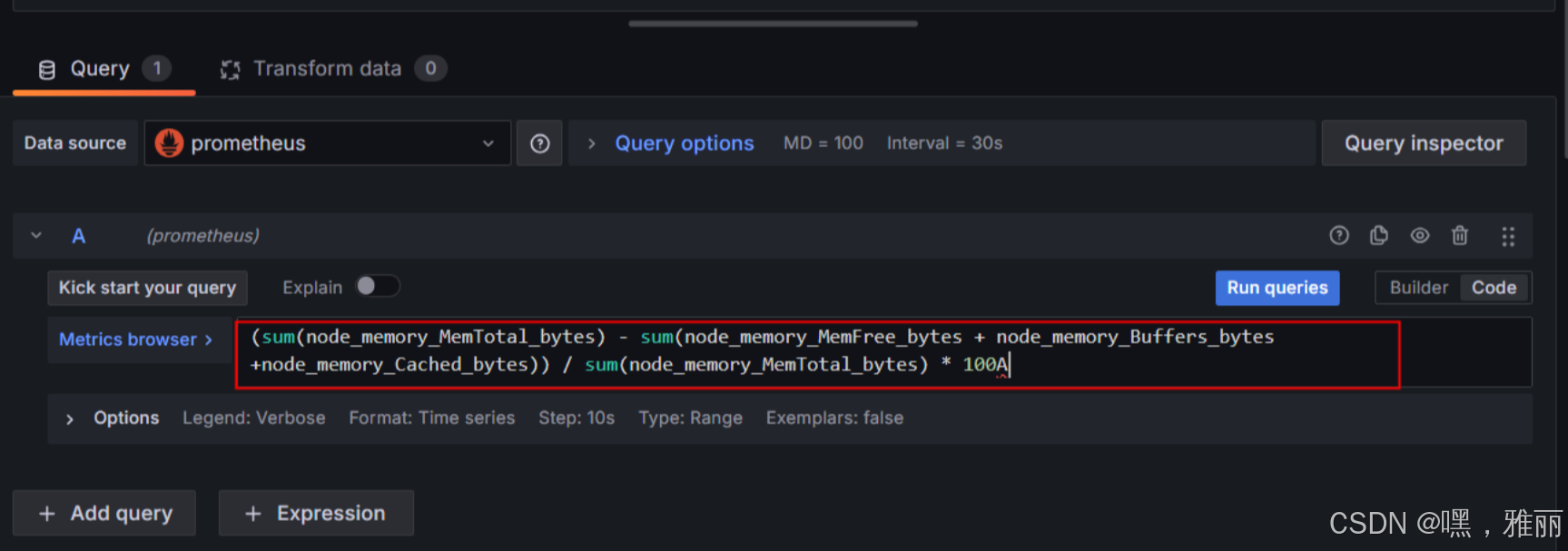
复制其中的语句到prometheus的graph发现没有数据,这是因为语句不一致,需要更改语句
(sum(node_memory_MemTotal_bytes) - sum(node_memory_MemFree_bytes + node_memory_Buffers_bytes+node_memory_Cached_bytes)) / sum(node_memory_MemTotal_bytes) * 100
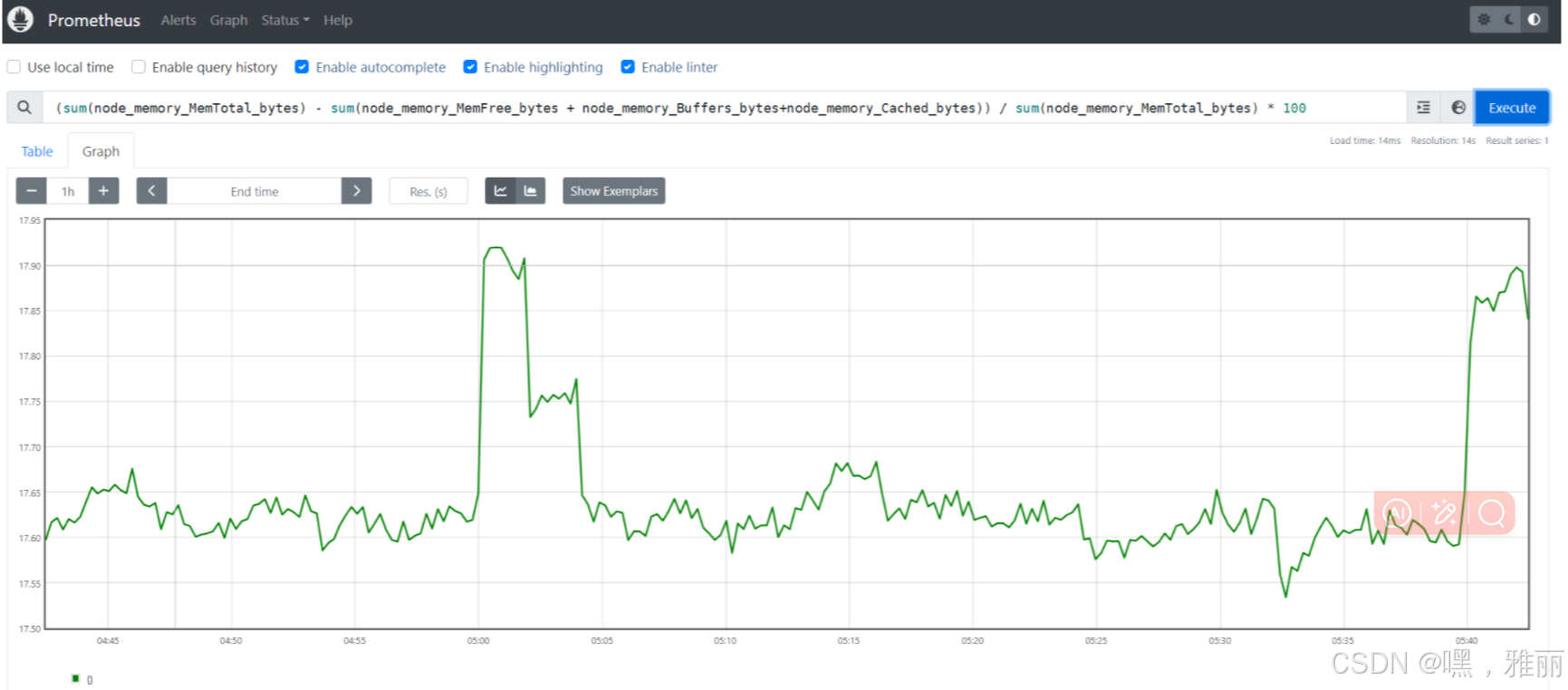
图表可以正常显示
部署alermanage
Prometheus 包含一个报警模块,就是我们的 AlertManager,Alertmanager 主要用于接收 Prometheus 发送的告警信息,它支持丰富的告警通知渠道,而且很容易做到告警信息进行去重,降噪,分组等,是一款前卫的告警通知系统。
指定配置文件,同样的,我们这里使用一个 ConfigMap 资源对象
vim alertmanager-conf.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: alert-config
namespace: kube-ops
data:
config.yml: |-
global:
# 在没有报警的情况下声明为已解决的时间
resolve_timeout: 5m
# 配置邮件发送信息
smtp_smarthost: 'smtp.qq.com:465'
smtp_from: '2*****@qq.com'
smtp_auth_username: '2*****@qq.com'
smtp_auth_password: 'jysthtmfdfdsfsf' #秘钥
smtp_hello: 'qq.com'
smtp_require_tls: false
# 所有报警信息进入后的根路由,用来设置报警的分发策略
route:
# 这里的标签列表是接收到报警信息后的重新分组标签,例如,接收到的报警信息里面有许多具有 cluster=A 和 alertname=LatncyHigh 这样的标签的报警信息将会批量被聚合到一个分组里面
group_by: ['alertname', 'cluster']
# 当一个新的报警分组被创建后,需要等待至少group_wait时间来初始化通知,这种方式可以确保您能有足够的时间为同一分组来获取多个警报,然后一起触发这个报警信息。
group_wait: 30s
# 当第一个报警发送后,等待'group_interval'时间来发送新的一组报警信息。
group_interval: 5m
# 如果一个报警信息已经发送成功了,等待'repeat_interval'时间来重新发送他们
repeat_interval: 5m
# 默认的receiver:如果一个报警没有被一个route匹配,则发送给默认的接收器
receiver: default
# 上面所有的属性都由所有子路由继承,并且可以在每个子路由上进行覆盖。
#routes:
#- receiver: email
# group_wait: 10s
# match:
# team: node
receivers:
- name: 'default'
email_configs:
- to: '2332*****@qq.com'
send_resolved: true
- name: 'email'
email_configs:
- to: '2*****@qq.com'
send_resolved: true
配置 AlertManager 的容器,我们可以直接在之前的 Prometheus 的 Pod 中添加这个容器,对应的 YAML 资源声明如下:
vim alertmanager-sts.yaml
apiVersion: apps/v1
kind: StatefulSet
metadata:
namespace: kube-ops
name: alertmanager
spec:
serviceName: alertmanager
replicas: 1
selector:
matchLabels:
app: alertmanager
template:
metadata:
labels:
app: alertmanager
spec:
nodeName: k8s-node1
containers:
- name: alertmanager
image: quay.io/prometheus/alertmanager:v0.27.0
imagePullPolicy: IfNotPresent
args:
- "--config.file=/etc/alertmanager/config.yml"
ports:
- containerPort: 9093
name: http
volumeMounts:
- mountPath: "/etc/alertmanager"
name: alertcfg
resources:
requests:
cpu: 100m
memory: 256Mi
volumes:
- name: alertcfg
configMap:
name: alert-config
创建
kubectl apply -f alertmanager-conf.yaml
kubectl apply -f alertmanager-sts.yaml
vim alertmanager-svc.yaml
apiVersion: v1
kind: Service
metadata:
name: alermanager
namespace: kube-ops
labels:
app: alermanager
spec:
selector:
app: alermanager
type: NodePort
ports:
- name: web
port: 9093
targetPort: http
配置prometheus
alerting:
alertmanagers:
- static_configs:
- targets: ["alermanager:9093"]
rule_files:
- /etc/prometheus/rules.yml
配置告警规则
rules.yml: |
groups:
- name: test-rule
rules:
- alert: NodeMemoryUsage
expr: (node_memory_MemTotal_bytes - (node_memory_MemFree_bytes + node_memory_Buffers_bytes + node_memory_Cached_bytes)) / node_memory_MemTotal_bytes * 100 > 15
for: 2m
labels:
team: node
annotations:
summary: "{{$labels.instance}}: High Memory usage detected"
description: "{{$labels.instance}}: Memory usage is above 20% (current value is: {{ $value }}"
查看告警
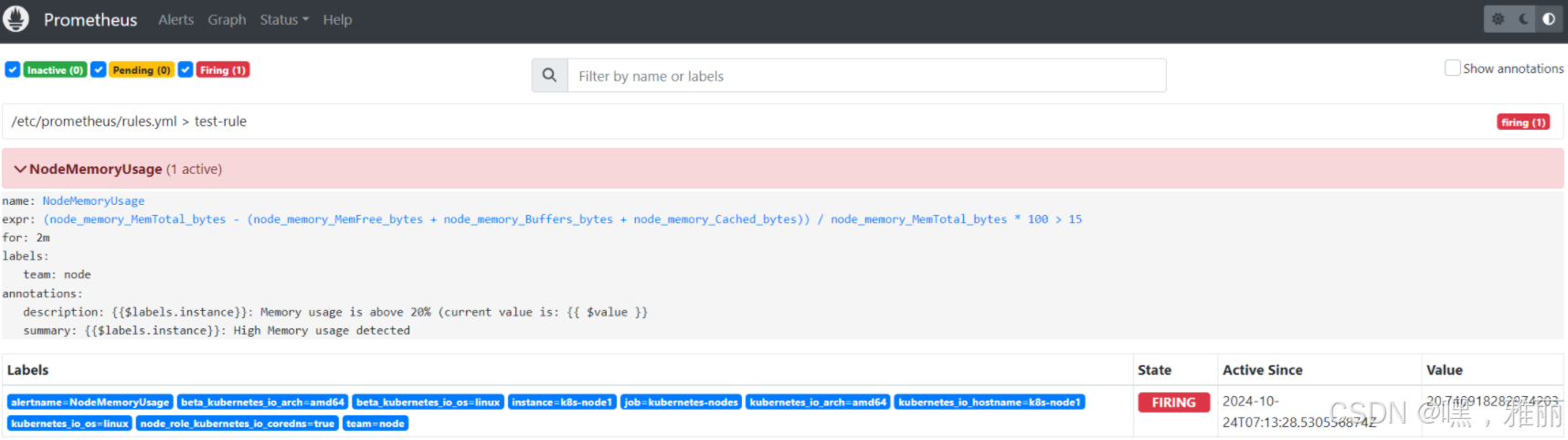
未完,待更新

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









