







本文参考来源:https://blog.youkuaiyun.com/2403_83044722/article/details/140859995
1、代码及结果
数据集:https://download.youkuaiyun.com/download/weixin_59243359/90061738
或者 https://aistudio.baidu.com/datasetdetail/102711
训练代码:如下
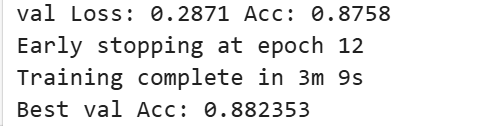
val Loss: 0.2871 Acc: 0.8758
# 验证集上的损失(loss)值是0.2871,准确率(accuracy)是0.8758
# 损失值越低,表示模型的预测误差越小;准确率越高,表示模型的预测正确率越高。
Early stopping at epoch 12
# 在训练过程中使用了早停法(Early Stopping),在第12个epoch时触发了早停。
# 早停法是一种防止过拟合的技术,当验证集上的性能(如准确率)在连续几个epoch中没有显著提升时,训练会提前终止。这里的信息表明,在第12个epoch时,模型在验证集上的性能没有进一步的提升,因此训练停止。
Training complete in 3m 9s # 整个训练过程完成,总共耗时3分钟9秒。
Best val Acc: 0.882353
# 在验证集上最高准确度是0.882353
import torch # 导入PyTorch库
import torch.nn as nn # 导入神经网络模块
import torch.optim as optim # 导入优化器模块
from torch.optim import lr_scheduler # 导入学习率调度器模块
from torch.utils.data import DataLoader # 导入数据加载器模块
from torchvision import datasets, transforms, models # 导入视觉相关的模块
import matplotlib.pyplot as plt # 导入绘图库
import time # 导入时间模块
import os # 导入操作系统接口模块
import copy # 导入复制模块
from tqdm import tqdm # 导入进度条模块
# 设备配置,自动选择使用GPU或CPU
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 数据预处理步骤
data_transforms = {
'train': transforms.Compose([
transforms.RandomResizedCrop(224), # 随机裁剪到224x224
transforms.RandomHorizontalFlip(), # 随机水平翻转
transforms.RandomRotation(15), # 随机旋转±15度
transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2), # 随机颜色抖动
transforms.ToTensor(), # 转换为Tensor
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) # 归一化
]),
'val': transforms.Compose([
transforms.Resize(256), # 缩放到256x256
transforms.CenterCrop(224), # 中心裁剪到224x224
transforms.ToTensor(), # 转换为Tensor
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) # 归一化
]),
}
# 数据集路径
data_dir = './datasets/' # 数据集存放目录
image_datasets = {x: datasets.ImageFolder(os.path.join(data_dir, x), data_transforms[x])
for x in ['train', 'val']} # 创建训练和验证数据集
dataloaders = {x: DataLoader(image_datasets[x], batch_size=16, shuffle=True, num_workers=4)
for x in ['train', 'val']} # 创建数据加载器
dataset_sizes = {x: len(image_datasets[x]) for x in ['train', 'val']} # 记录每个数据集的大小
class_names = image_datasets['train'].classes # 获取类别名称
# 定义网络结构(使用预训练的 ResNet18)
def make_net():
model = models.resnet18(pretrained=True) # 加载预训练的ResNet18模型
num_ftrs = model.fc.in_features # 获取全连接层的输入特征数
model.fc = nn.Linear(num_ftrs, len(class_names)) # 修改全连接层以匹配类别数量
return model.to(device) # 将模型移动到设备(GPU或CPU)
# 训练函数
def train_model(model, criterion, optimizer, scheduler, num_epochs=25, early_stop_patience=5):
since = time.time() # 记录开始时间
best_model_wts = copy.deepcopy(model.state_dict()) # 存储最佳模型权重
best_acc = 0.0 # 初始化最佳准确率
best_epoch = 0 # 初始化最佳epoch
train_losses, val_losses = [], [] # 存储训练和验证损失
train_accs, val_accs = [], [] # 存储训练和验证准确率
for epoch in range(num_epochs): # 遍历每个epoch
print(f'Epoch {epoch}/{num_epochs - 1}')
print('-' * 10)
for phase in ['train', 'val']: # 遍历训练和验证阶段
if phase == 'train':
model.train() # 设置模型为训练模式
else:
model.eval() # 设置模型为评估模式
running_loss = 0.0 # 初始化损失
running_corrects = 0 # 初始化正确预测数
for inputs, labels in tqdm(dataloaders[phase], desc=f'{phase} epoch {epoch}'):
inputs = inputs.to(device) # 将数据移动到设备
labels = labels.to(device) # 将标签移动到设备
optimizer.zero_grad() # 清零梯度
with torch.set_grad_enabled(phase == 'train'): # 只在训练阶段计算梯度
outputs = model(inputs) # 前向传播
_, preds = torch.max(outputs, 1) # 获取预测结果
loss = criterion(outputs, labels) # 计算损失
if phase == 'train': # 只在训练阶段进行反向传播和优化
loss.backward()
optimizer.step()
running_loss += loss.item() * inputs.size(0) # 累积损失
running_corrects += torch.sum(preds == labels.data) # 累积正确预测数
epoch_loss = running_loss / dataset_sizes[phase] # 计算平均损失
epoch_acc = running_corrects.double() / dataset_sizes[phase] # 计算准确率
if phase == 'train': # 更新训练损失和准确率
train_losses.append(epoch_loss)
train_accs.append(epoch_acc.item())
scheduler.step() # 更新学习率
else: # 更新验证损失和准确率
val_losses.append(epoch_loss)
val_accs.append(epoch_acc.item())
print(f'{phase} Loss: {epoch_loss:.4f} Acc: {epoch_acc:.4f}') # 打印损失和准确率
# 保存最佳模型权重
if phase == 'val' and epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = copy.deepcopy(model.state_dict()) # 深拷贝模型权重
best_epoch = epoch # 更新最佳epoch
# 提前停止机制
if epoch - best_epoch >= early_stop_patience: # 如果连续多个epoch没有提升,则提前停止
print(f"Early stopping at epoch {epoch}")
break
print()
time_elapsed = time.time() - since # 计算训练时间
print(f'Training complete in {time_elapsed // 60:.0f}m {time_elapsed % 60:.0f}s') # 打印训练时间
print(f'Best val Acc: {best_acc:4f}') # 打印最佳验证准确率
model.load_state_dict(best_model_wts) # 加载最佳模型权重
plot_loss_accuracy(train_losses, val_losses, train_accs, val_accs) # 绘制损失和准确率曲线
return model # 返回训练好的模型
# 绘制损失和准确率曲线
def plot_loss_accuracy(train_losses, val_losses, train_accs, val_accs):
epochs = range(len(train_losses)) # 获取epoch范围
plt.figure(figsize=(12, 6)) # 设置绘图大小
plt.subplot(2, 1, 1) # 设置子图位置
plt.plot(epochs, train_losses, label='Training Loss') # 绘制训练损失
plt.plot(epochs, val_losses, label='Validation Loss') # 绘制验证损失
plt.title('Loss Over Time') # 设置标题
plt.xlabel('Epoch') # 设置x轴标签
plt.ylabel('Loss') # 设置y轴标签
plt.legend() # 显示图例
plt.subplot(2, 1, 2) # 设置子图位置
plt.plot(epochs, train_accs, label='Training Accuracy') # 绘制训练准确率
plt.plot(epochs, val_accs, label='Validation Accuracy') # 绘制验证准确率
plt.title('Accuracy Over Time') # 设置标题
plt.xlabel('Epoch') # 设置x轴标签
plt.ylabel('Accuracy') # 设置y轴标签
plt.legend() # 显示图例
plt.tight_layout() # 自动调整子图布局
plt.savefig('loss_accuracy_curve.png') # 保存图像
plt.close() # 关闭绘图窗口
# 主程序
if __name__ == "__main__":
model = make_net() # 创建模型
criterion = nn.CrossEntropyLoss() # 定义损失函数
optimizer = optim.AdamW(model.parameters(), lr=0.001, weight_decay=1e-4) # 定义优化器
scheduler = lr_scheduler.CosineAnnealingLR(optimizer, T_max=10, eta_min=1e-5) # 定义学习率调度器
model = train_model(model, criterion, optimizer, scheduler, num_epochs=25) # 训练模型
训练流程如下:

2、模型改进点
-
网络结构优化:引入更深层次的卷积层和批归一化(Batch Normalization)。
-
数据增强改进:增加随机旋转、亮度调整等。
-
优化器改进:更换为 AdamW,并添加学习率预热和余弦退火。
-
训练过程可视化:绘制损失和准确率曲线。
-
早停机制:避免不必要的训练。
-
使用预训练模型 (ResNet18):提高小数据集上的性能。
3、运行环境:
-
Python 版本:建议 3.8 以上。
-
PyTorch 版本:1.9.0 及以上。
-
GPU:如果有 CUDA 可用,代码将自动使用 GPU 训练。


















 682
682

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











