







一. 什么是强化学习
强化学习 (Reinforcement Learning, RL) , 又称增强学习, 是机器学习方法的一种, 用于描述和解决智能体 (agent) 在与环境 (Environment) 的交互过程中通过学习策略以达成回报最大化或实现特定目标的问题.
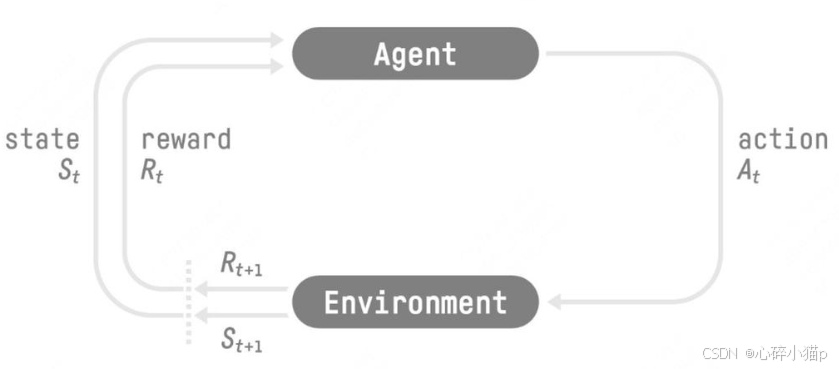
The RL Process: a loop of state, action, reward and next state
图中的标签解释:
-
状态空间S: State, 指环境种所有可能状态的集合.
-
状态空间A: Action, 指智能体所有可能动作的集合.
-
奖励R: Reward, 指智能体在环境的某个状态下所获得的奖励.
智能体 (agent) 在与环境 (Environment) 的交互过程:
-
环境处于状态 St, 智能体获得奖励Rt.
-
智能体观测到状态 St 和奖励 Rt, 然后选择动作 At.
-
奖励R: Reward, 指智能体在环境的某个状态下所获得的奖励.
这个循环不断重复, 最终目标: 找到一个策略, 这个策略根据当前观测到的环境状态和奖励反馈, 来选择最佳的动作.
上述提到的 Rt 表示环境进入 St 下的即时奖励, 但是当下的动作还会影响的未来的状态和动作, 所以也要把即时收益和未来收益融合一起, 形成表达式: Vt = Rt + γV(t + 1).
-
Vt: t 时刻的总收益 (包含了即时和未来的总收益).
-
Rt: t 时刻的即使收益.
-
V(t + 1): t + 1 时刻的总收益 (也包含了即时和未来的总收益).
-
γ: 折扣因子, 决定未来收益的占比.
二. 强化学习具体流程
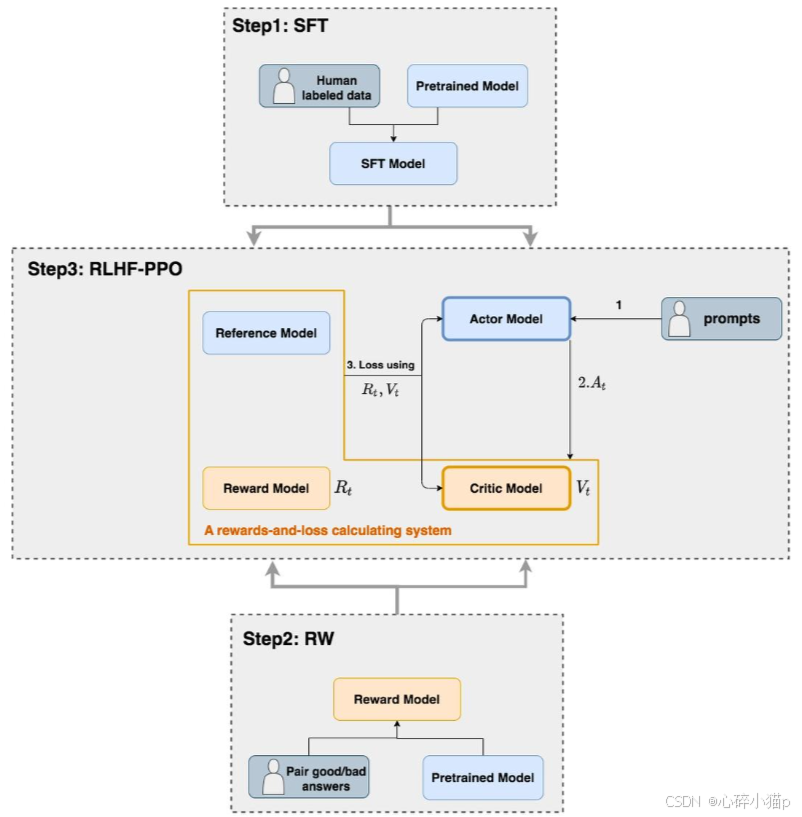
如果做强化学习, 一定要先有 SFT (监督学习微调) 模型, 再有 RM (训练奖励模型) 模型, 奖励模型的输入就是 SFT 的输出结果, 带入奖励模型种得到分数, 将刚才的两个模型进行再次的调优, 使用PPO 算法, 分数低就再次迭代更新 SFT 和 RM 模型, 使奖励最大化, 最终目的还是优化 SFT 模型.
三. RLHF-PPO 阶段的四个模型
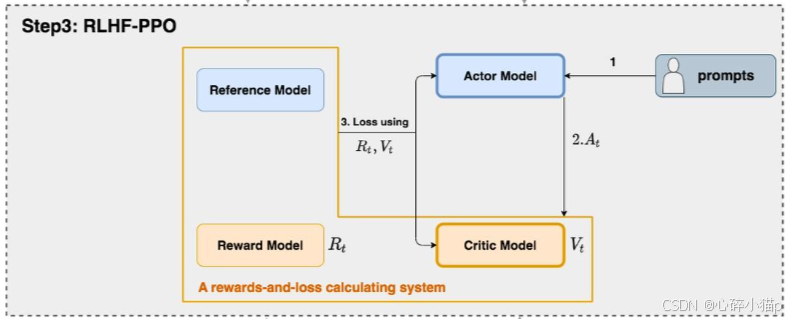
-
演员模型 (Actor Model): 目标语
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 693
693

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









