







目录
读取数据
支持读取的数据源
- 文件数据
- 从文件中读取数据
- kafka数据 常用
- 从kafka中读取数据
- Socket数据
- 从网络端口读取数据
- Rate数据
- 框架自己产生数据,测试性能,优化参数
文件数据处理
| option参数 | 描述说明 |
|---|---|
| maxFilesPerTrigger | 每个batch最多的文件数,默认是没有限制。比如我设置了这个值为1,那么同时增加了5个文件,这5个文件会每个文件作为一波数据,更新streaming dataframe。 |
| latestFirst | 是否先处理最新的新文件, 当有大量文件积压时有用 (默认: false) |
| fileNameOnly | 是否检查新文件只有文件名而不是完整路径(默认值:false) 将此设置为 true 时,以下文件将被视为同一个文件,因为它们的文件名“dataset.txt”相同: “file:///dataset.txt” “s3://a/数据集.txt " "s3n ://a/b/dataset.txt" "s3a://a/b/c/dataset.txt" |
读取数据
当目录下只有一个文件
1)将文件传到hdfs上
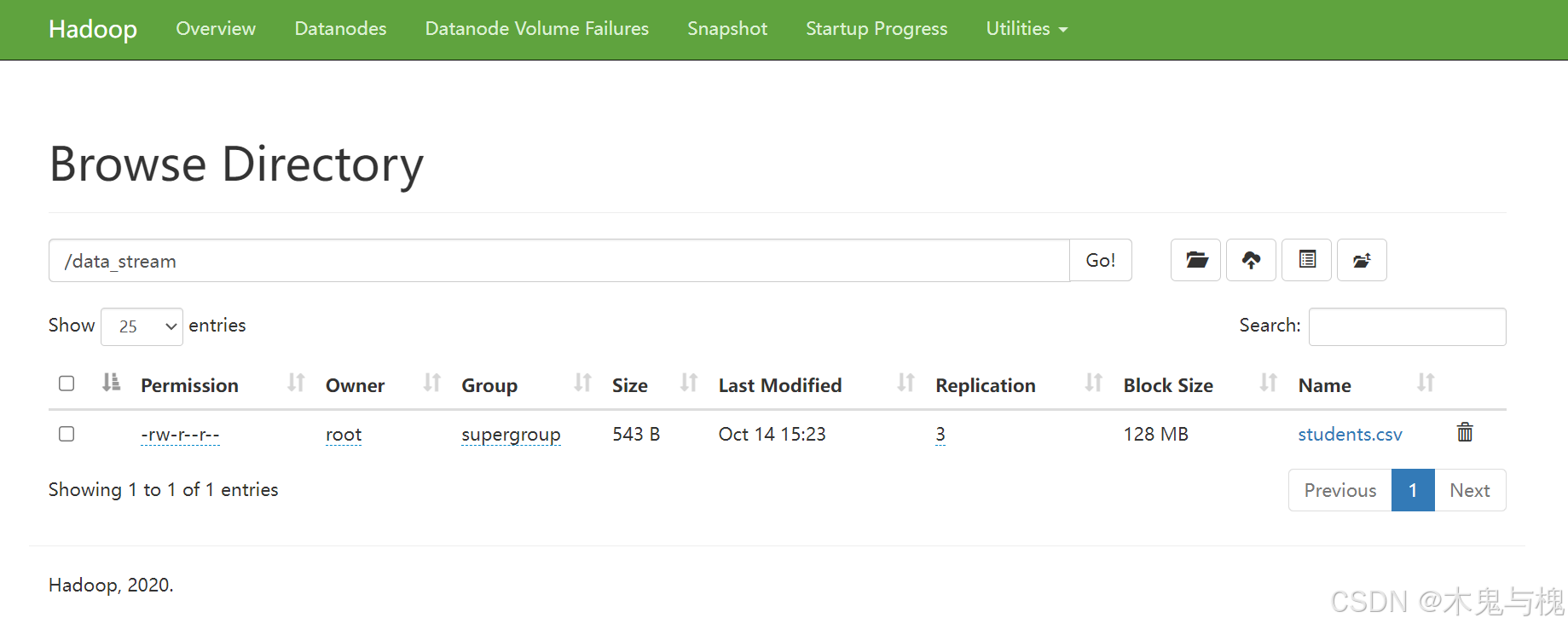
2)执行代码,读取文件
# 流式读取文件数据
from pyspark.sql import SparkSession
ss = SparkSession.builder.getOrCreate()
# 读取文件数据
# 读取hdfs上的数据文件
# 路径中写的是目录位置,不要指定写文件名
# 指定的目录中有新文件 产生就会读新文件数据,已经读取的不会在读取
df = ss.readStream.text(path = 'hdfs://node1:8020/data_stream')
# 输出
df.writeStream.start(format='console',outputMode='append').awaitTermination()
# 输出
df.writeStream.start(format='console',outputMode='append').awaitTermination()3)结果
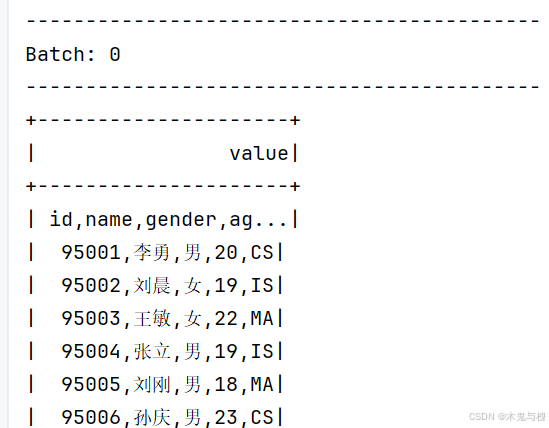
读取文件也可以有其他形式
df=ss.readStream.option('maxFilePerTrigger',1).text(path='hdfs://node1:8020/data_stream')
df =ss.readStream.load(format='csv',path='hdfs://node1:8020/data_stream',schema='id int,name string,gender string,age int,cls string')
df=ss.readStream.csv(path='hdfs://node1:8020/data_stream',header=False,sep=',',schema='id int,name string,gender string,age int,cls string')
df = ss.readStream.json(path='hdfs://node1:8020/data_stream3')注:
1、读取文件数据时,不能指定某个具体文件,而是指定文件所在的目录
2、目录下的同一个文件只会被读取一次,处理过的文件数据不会在重新处理
文件的读取方式在实际开发中用的比较少,生产一条数据,就要生成一个文件
但是,如果将多条数据收集之后同一写入文件,那就变成了和批处理方式一样的开发
实际开发中很少使用使用spark流读文件,可以使用flume工具流式读取文件,然后在通过saprk读取产生flume数据
当目录下有多个文件
上传完数据,执行代码,会一次性将数据输出,为了避免这种事情,可以使用参数‘maxFilesPerTrigger’,设置文件数
# 流式读取文件数据
from pyspark.sql import SparkSession
ss = SparkSession.builder.getOrCreate()
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









