







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新网络安全全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上网络安全知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip204888 (备注网络安全)

正文
---
### 键盘控制
`webdriver` 中 `Keys` 类几乎提供了键盘上的所有按键方法,我们可以使用 `send_keys + Keys` 实现输出键盘上的组合按键如 **“Ctrl + C”、“Ctrl + V”** 等。
from selenium.webdriver.common.keys import Keys
定位输入框并输入文本
driver.find_element_by_id(‘xxx’).send_keys(‘Dream丶killer’)
模拟回车键进行跳转(输入内容后)
driver.find_element_by_id(‘xxx’).send_keys(Keys.ENTER)
使用 Backspace 来删除一个字符
driver.find_element_by_id(‘xxx’).send_keys(Keys.BACK_SPACE)
Ctrl + A 全选输入框中内容
driver.find_element_by_id(‘xxx’).send_keys(Keys.CONTROL, ‘a’)
Ctrl + C 复制输入框中内容
driver.find_element_by_id(‘xxx’).send_keys(Keys.CONTROL, ‘c’)
Ctrl + V 粘贴输入框中内容
driver.find_element_by_id(‘xxx’).send_keys(Keys.CONTROL, ‘v’)
其他常见键盘操作:
| 操作 | 描述 |
| --- | --- |
| `Keys.F1` | F1键 |
| `Keys.SPACE` | 空格 |
| `Keys.TAB` | Tab键 |
| `Keys.ESCAPE` | ESC键 |
| `Keys.ALT` | Alt键 |
| `Keys.SHIFT` | Shift键 |
| `Keys.ARROW_DOWN` | 向下箭头 |
| `Keys.ARROW_LEFT` | 向左箭头 |
| `Keys.ARROW_RIGHT` | 向右箭头 |
| `Keys.ARROW_UP` | 向上箭头 |
---
### 设置元素等待
很多页面都使用 `ajax` 技术,页面的元素不是同时被加载出来的,为了防止定位这些尚在加载的元素报错,可以设置元素等来增加脚本的稳定性。`webdriver` 中的等待分为 显式等待 和 隐式等待。
#### 显式等待
显式等待:设置一个超时时间,每个一段时间就去检测一次该元素是否存在,如果存在则执行后续内容,如果超过最大时间(超时时间)则抛出超时异常(`TimeoutException`)。显示等待需要使用 `WebDriverWait`,同时配合 `until` 或 `not until` 。下面详细讲解一下。
>
> WebDriverWait(driver, timeout, poll\_frequency=0.5, ignored\_exceptions=None)
>
>
>
* `driver`:浏览器驱动
* `timeout`:超时时间,单位秒
* `poll_frequency`:每次检测的间隔时间,默认为0.5秒
* `ignored_exceptions`:指定忽略的异常,如果在调用 `until` 或 `until_not` 的过程中抛出指定忽略的异常,则不中断代码,默认忽略的只有 `NoSuchElementException` 。
>
> until(method, message=’ ‘)
> until\_not(method, message=’ ')
>
>
>
* `method`:指定预期条件的判断方法,在等待期间,每隔一段时间调用该方法,判断元素是否存在,直到元素出现。`until_not` 正好相反,当元素消失或指定条件不成立,则继续执行后续代码
* `message`: 如果超时,抛出 `TimeoutException` ,并显示 `message` 中的内容
`method` 中的预期条件判断方法是由 `expected_conditions` 提供,下面列举常用方法。
先定义一个定位器
from selenium.webdriver.common.by import By
from selenium import webdriver
driver = webdriver.Chrome()
locator = (By.ID, ‘kw’)
element = driver.find_element_by_id(‘kw’)
| 方法 | 描述 |
| --- | --- |
| title\_is(‘百度一下’) | 判断当前页面的 title 是否等于预期 |
| title\_contains(‘百度’) | 判断当前页面的 title 是否包含预期字符串 |
| presence\_of\_element\_located(locator) | 判断元素是否被加到了 dom 树里,并不代表该元素一定可见 |
| visibility\_of\_element\_located(locator) | 判断元素是否可见,可见代表元素非隐藏,并且元素的宽和高都不等于0 |
| visibility\_of(element) | 跟上一个方法作用相同,但传入参数为 element |
| text\_to\_be\_present\_in\_element(locator , ‘百度’) | 判断元素中的 text 是否包含了预期的字符串 |
| text\_to\_be\_present\_in\_element\_value(locator , ‘某值’) | 判断元素中的 value 属性是否包含了预期的字符串 |
| frame\_to\_be\_available\_and\_switch\_to\_it(locator) | 判断该 frame 是否可以 switch 进去,True 则 switch 进去,反之 False |
| invisibility\_of\_element\_located(locator) | 判断元素中是否不存在于 dom 树或不可见 |
| element\_to\_be\_clickable(locator) | 判断元素中是否可见并且是可点击的 |
| staleness\_of(element) | 等待元素从 dom 树中移除 |
| element\_to\_be\_selected(element) | 判断元素是否被选中,一般用在下拉列表 |
| element\_selection\_state\_to\_be(element, True) | 判断元素的选中状态是否符合预期,参数 element,第二个参数为 True/False |
| element\_located\_selection\_state\_to\_be(locator, True) | 跟上一个方法作用相同,但传入参数为 locator |
| alert\_is\_present() | 判断页面上是否存在 alert |
下面写一个简单的例子,这里定位一个页面不存在的元素,抛出的异常信息正是我们指定的内容。
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
element = WebDriverWait(driver, 5, 0.5).until(
EC.presence_of_element_located((By.ID, ‘kw’)),
message=‘超时啦!’)

#### 隐式等待
隐式等待也是指定一个超时时间,如果超出这个时间指定元素还没有被加载出来,就会抛出 `NoSuchElementException` 异常。
除了抛出的异常不同外,还有一点,隐式等待是全局性的,即运行过程中,如果元素可以定位到,它不会影响代码运行,但如果定位不到,则它会以轮询的方式不断地访问元素直到元素被找到,若超过指定时间,则抛出异常。
使用 `implicitly_wait()` 来实现隐式等待,使用难度相对于显式等待要简单很多。
示例:打开个人主页,设置一个隐式等待时间 5s,通过 `id` 定位一个不存在的元素,最后打印 抛出的异常 与 运行时间。
from selenium import webdriver
from time import time
driver = webdriver.Chrome()
driver.get(‘https://blog.youkuaiyun.com/qq_43965708’)
start = time()
driver.implicitly_wait(5)
try:
driver.find_element_by_id(‘kw’)
except Exception as e:
print(e)
print(f’耗时:{time()-start}')

代码运行到 `driver.find_element_by_id('kw')` 这句之后触发隐式等待,在轮询检查 5s 后仍然没有定位到元素,抛出异常。
#### 强制等待
使用 `time.sleep()` 强制等待,设置固定的休眠时间,对于代码的运行效率会有影响。以上面的例子作为参照,将 隐式等待 改为 强制等待。
from selenium import webdriver
from time import time, sleep
driver = webdriver.Chrome()
driver.get(‘https://blog.youkuaiyun.com/qq_43965708’)
start = time()
sleep(5)
try:
driver.find_element_by_id(‘kw’)
except Exception as e:
print(e)
print(f’耗时:{time()-start}')

值得一提的是,对于定位不到元素的时候,从耗时方面隐式等待和强制等待没什么区别。但如果元素经过 2s 后被加载出来,这时隐式等待就会继续执行下面的代码,但 sleep还要继续等待 3s。
---
### 定位一组元素
上篇讲述了定位一个元素的 8 种方法,定位一组元素使用的方法只需要将 `element` 改为 `elements` 即可,它的使用场景一般是为了批量操作元素。
* `find_elements_by_id()`
* `find_elements_by_name()`
* `find_elements_by_class_name()`
* `find_elements_by_tag_name()`
* `find_elements_by_xpath()`
* `find_elements_by_css_selector()`
* `find_elements_by_link_text()`
* `find_elements_by_partial_link_text()`
这里以 优快云 首页的一个 博客专家栏 为例。
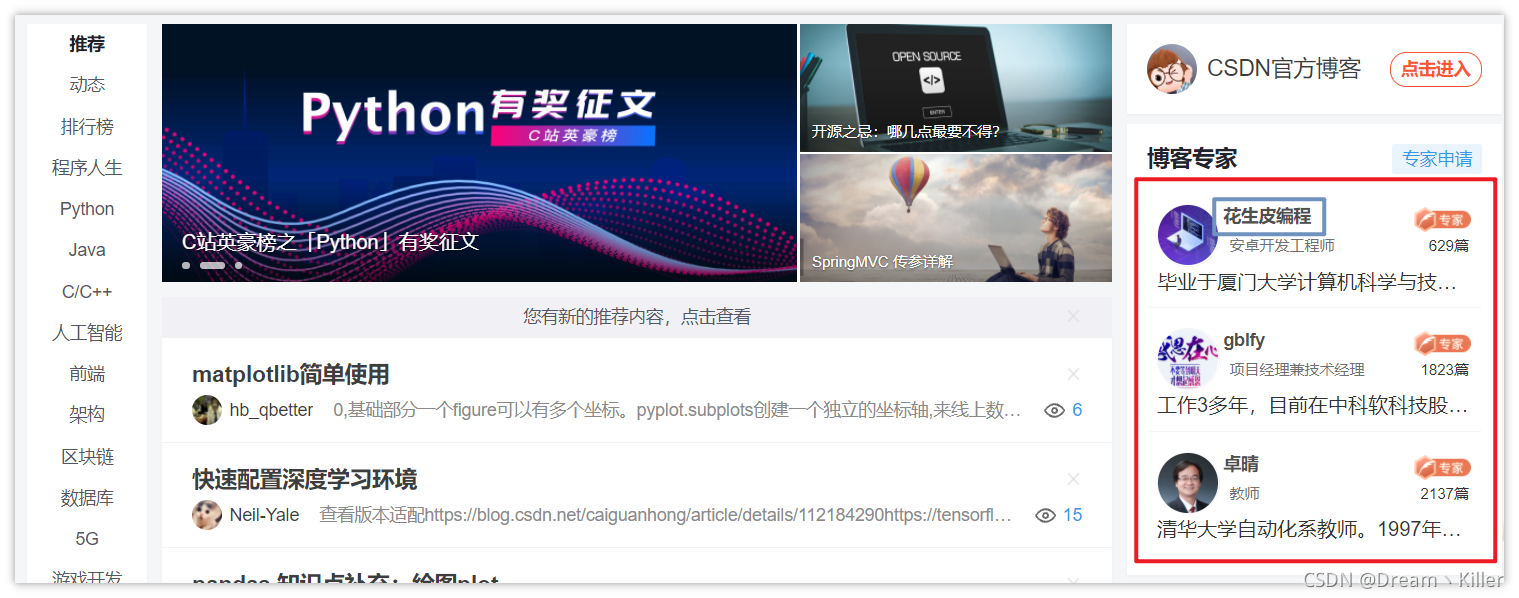
下面使用 `find_elements_by_xpath` 来定位三位专家的名称。

这是专家名称部分的页面代码,不知各位有没有想到如何通过 `xpath` 定位这一组专家的名称呢?
from selenium import webdriver
设置无头浏览器
option = webdriver.ChromeOptions()
option.add_argument(‘–headless’)
driver = webdriver.Chrome(options=option)
driver.get(‘https://blog.youkuaiyun.com/’)
p_list = driver.find_elements_by_xpath(“//p[@class=‘name’]”)
name = [p.text for p in p_list]
name

---
### 切换操作
#### 窗口切换
在 `selenium` 操作页面的时候,可能会因为点击某个链接而跳转到一个新的页面(打开了一个新标签页),这时候 `selenium` 实际还是处于上一个页面的,需要我们进行切换才能够定位最新页面上的元素。
窗口切换需要使用 `switch_to.windows()` 方法。
首先我们先看看下面的代码。
代码流程:先进入 【**优快云首页**】,保存当前页面的句柄,然后再点击左侧 【**优快云官方博客**】跳转进入新的标签页,再次保存页面的句柄,我们验证一下 `selenium` 会不会自动定位到新打开的窗口。
from selenium import webdriver
handles = []
driver = webdriver.Chrome()
driver.get(‘https://blog.youkuaiyun.com/’)
设置隐式等待
driver.implicitly_wait(3)
获取当前窗口的句柄
handles.append(driver.current_window_handle)
点击 python,进入分类页面
driver.find_element_by_xpath(‘//*[@id=“mainContent”]/aside/div[1]/div’).click()
获取当前窗口的句柄
handles.append(driver.current_window_handle)
print(handles)
获取当前所有窗口的句柄
print(driver.window_handles)

可以看到第一个列表 `handle` 是相同的,说明 `selenium` 实际操作的还是 优快云首页 ,并未切换到新页面。
下面使用 `switch_to.windows()` 进行切换。
from selenium import webdriver
handles = []
driver = webdriver.Chrome()
driver.get(‘https://blog.youkuaiyun.com/’)
设置隐式等待
driver.implicitly_wait(3)
获取当前窗口的句柄
handles.append(driver.current_window_handle)
点击 python,进入分类页面
driver.find_element_by_xpath(‘//*[@id=“mainContent”]/aside/div[1]/div’).click()
切换窗口
driver.switch_to.window(driver.window_handles[-1])
获取当前窗口的句柄
handles.append(driver.current_window_handle)
print(handles)
print(driver.window_handles)

上面代码在点击跳转后,使用 `switch_to` 切换窗口,**`window_handles` 返回的 `handle` 列表是按照页面出现时间进行排序的**,最新打开的页面肯定是最后一个,这样用 `driver.window_handles[-1]` + `switch_to` 即可跳转到最新打开的页面了。
那如果打开的窗口有多个,如何跳转到之前打开的窗口,如果确实有这个需求,那么打开窗口是就需要记录每一个窗口的 `key`(别名) 与 `value`(`handle`),保存到字典中,后续根据 `key` 来取 `handle` 。
#### 表单切换
很多页面也会用带 `frame/iframe` 表单嵌套,对于这种内嵌的页面 `selenium` 是无法直接定位的,需要使用 `switch_to.frame()` 方法将当前操作的对象切换成 `frame/iframe` 内嵌的页面。
`switch_to.frame()` 默认可以用的 `id` 或 `name` 属性直接定位,但如果 `iframe` 没有 `id` 或 `name` ,这时就需要使用 `xpath` 进行定位。下面先写一个包含 `iframe` 的页面做测试用。
公众号:Python新视野
优快云:Dream丶Killer
微信:python-sun
现在我们定位红框中的 优快云 按钮,可以跳转到 优快云 首页。
from selenium import webdriver
from pathlib import Path
driver = webdriver.Chrome()
读取本地html文件
driver.get(‘file:///’ + str(Path(Path.cwd(), ‘iframe测试.html’)))
1.通过id定位
driver.switch_to.frame(‘优快云_info’)
2.通过name定位
driver.switch_to.frame(‘Dream丶Killer’)
通过xpath定位
3.iframe_label = driver.find_element_by_xpath(‘/html/body/iframe’)
driver.switch_to.frame(iframe_label)
driver.find_element_by_xpath(‘//*[@id=“csdn-toolbar”]/div/div/div[1]/div/a/img’).click()
这里列举了三种定位方式,都可以定位 `iframe` 。

---
### 弹窗处理
`JavaScript` 有三种弹窗 `alert`(确认)、`confirm`(确认、取消)、`prompt`(文本框、确认、取消)。
处理方式:先定位(`switch_to.alert`自动获取当前弹窗),再使用 `text`、`accept`、`dismiss`、`send_keys` 等方法进行操作
| 方法 | 描述 |
| --- | --- |
| `text` | 获取弹窗中的文字 |
| `accept` | 接受(确认)弹窗内容 |
| `dismiss` | 解除(取消)弹窗 |
| `send_keys` | 发送文本至警告框 |
这里写一个简单的测试页面,其中包含三个按钮,分别对应三个弹窗。
<script type="text/javascript">
const dom1 = document.getElementById(“alert”)
dom1.addEventListener(‘click’, function(){
alert(“alert hello”)
})
const dom2 = document.getElementById(“confirm”)
dom2.addEventListener(‘click’, function(){
confirm(“confirm hello”)
})
const dom3 = document.getElementById(“prompt”)
dom3.addEventListener(‘click’, function(){
prompt(“prompt hello”)
})

下面使用上面的方法进行测试。为了防止弹窗操作过快,每次操作弹窗,都使用 `sleep` 强制等待一段时间。
from selenium import webdriver
from pathlib import Path
from time import sleep
driver = webdriver.Firefox()
driver.get(‘file:///’ + str(Path(Path.cwd(), ‘弹窗.html’)))
sleep(2)
点击alert按钮
driver.find_element_by_xpath(‘//*[@id=“alert”]’).click()
sleep(1)
alert = driver.switch_to.alert
打印alert弹窗的文本
print(alert.text)
确认
alert.accept()
sleep(2)
点击confirm按钮
driver.find_element_by_xpath(‘//*[@id=“confirm”]’).click()
sleep(1)
confirm = driver.switch_to.alert
print(confirm.text)
取消
confirm.dismiss()
sleep(2)
点击confirm按钮
driver.find_element_by_xpath(‘//*[@id=“prompt”]’).click()
sleep(1)
prompt = driver.switch_to.alert
print(prompt.text)
向prompt的输入框中传入文本
prompt.send_keys(“Dream丶Killer”)
sleep(2)
prompt.accept()
‘’‘输出
alert hello
confirm hello
prompt hello
‘’’

>
> 注:细心地读者应该会发现这次操作的浏览器是 `Firefox` ,为什么不用 `Chrome` 呢?原因是测试时发现执行 `prompt` 的 `send_keys` 时,不能将文本填入输入框。尝试了各种方法并查看源码后确认不是代码的问题,之后通过其他渠道得知原因可能是 `Chrome` 的版本与 `selenium` 版本的问题,但也没有很方便的解决方案,因此没有继续深究,改用 `Firefox` 可成功运行。这里记录一下我的 `Chrome` 版本,如果有大佬懂得如何在 `Chrome` 上解决这个问题,请在评论区指导一下,提前感谢!
> selenium:3.141.0
> Chrome:94.0.4606.71
> 
>
>
>
---
### 上传 & 下载文件
#### 上传文件
常见的 web 页面的上传,一般使用 `input` 标签或是插件(`JavaScript`、`Ajax`),对于 `input` 标签的上传,可以直接使用 `send_keys(路径)` 来进行上传。
先写一个测试用的页面。

下面通过 `xpath` 定位 `input` 标签,然后使用 `send_keys(str(file_path)` 上传文件。
from selenium import webdriver
from pathlib import Path
from time import sleep
driver = webdriver.Chrome()
file_path = Path(Path.cwd(), ‘上传下载.html’)
driver.get(‘file:///’ + str(file_path))
driver.find_element_by_xpath(‘//*[@name=“upload”]’).send_keys(str(file_path))

#### 下载文件
##### Chrome浏览器
`Firefox` 浏览器要想实现文件下载,需要通过 `add_experimental_option` 添加 `prefs` 参数。
* `download.default_directory`:设置下载路径。
* `profile.default_content_settings.popups`:0 禁止弹出窗口。
下面测试下载搜狗图片。指定保存路径为代码所在路径。
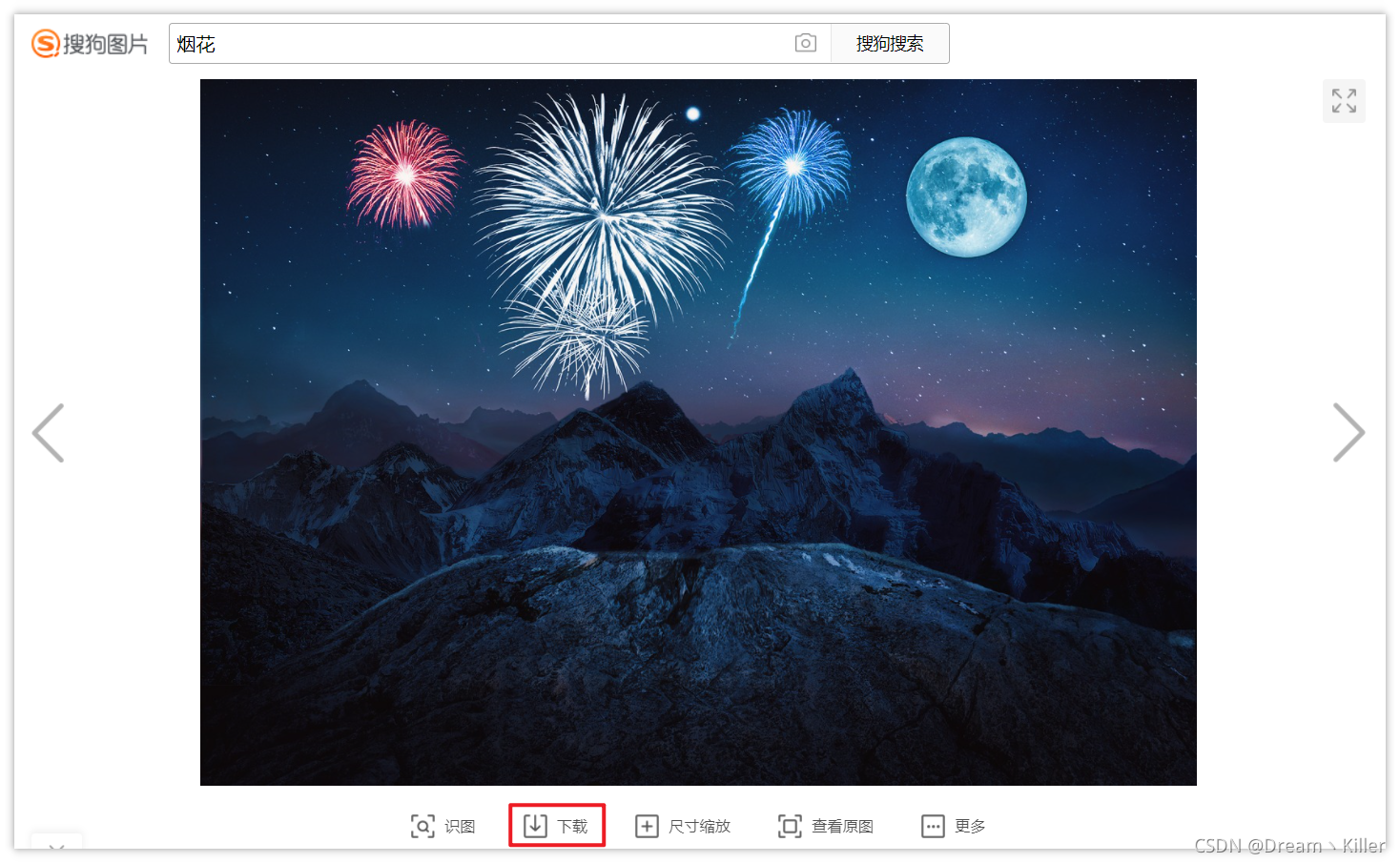
from selenium import webdriver
prefs = {‘profile.default_content_settings.popups’: 0,
‘download.default_directory’: str(Path.cwd())}
option = webdriver.ChromeOptions()
option.add_experimental_option(‘prefs’, prefs)
driver = webdriver.Chrome(options=option)
driver.get(“https://pic.sogou.com/d?query=%E7%83%9F%E8%8A%B1&did=4&category_from=copyright”)
driver.find_element_by_xpath(‘/html/body/div/div/div/div[2]/div[1]/div[2]/div[1]/div[2]/a’).click()
driver.switch_to.window(driver.window_handles[-1])
driver.find_element_by_xpath(‘./html’).send_keys(‘thisisunsafe’)
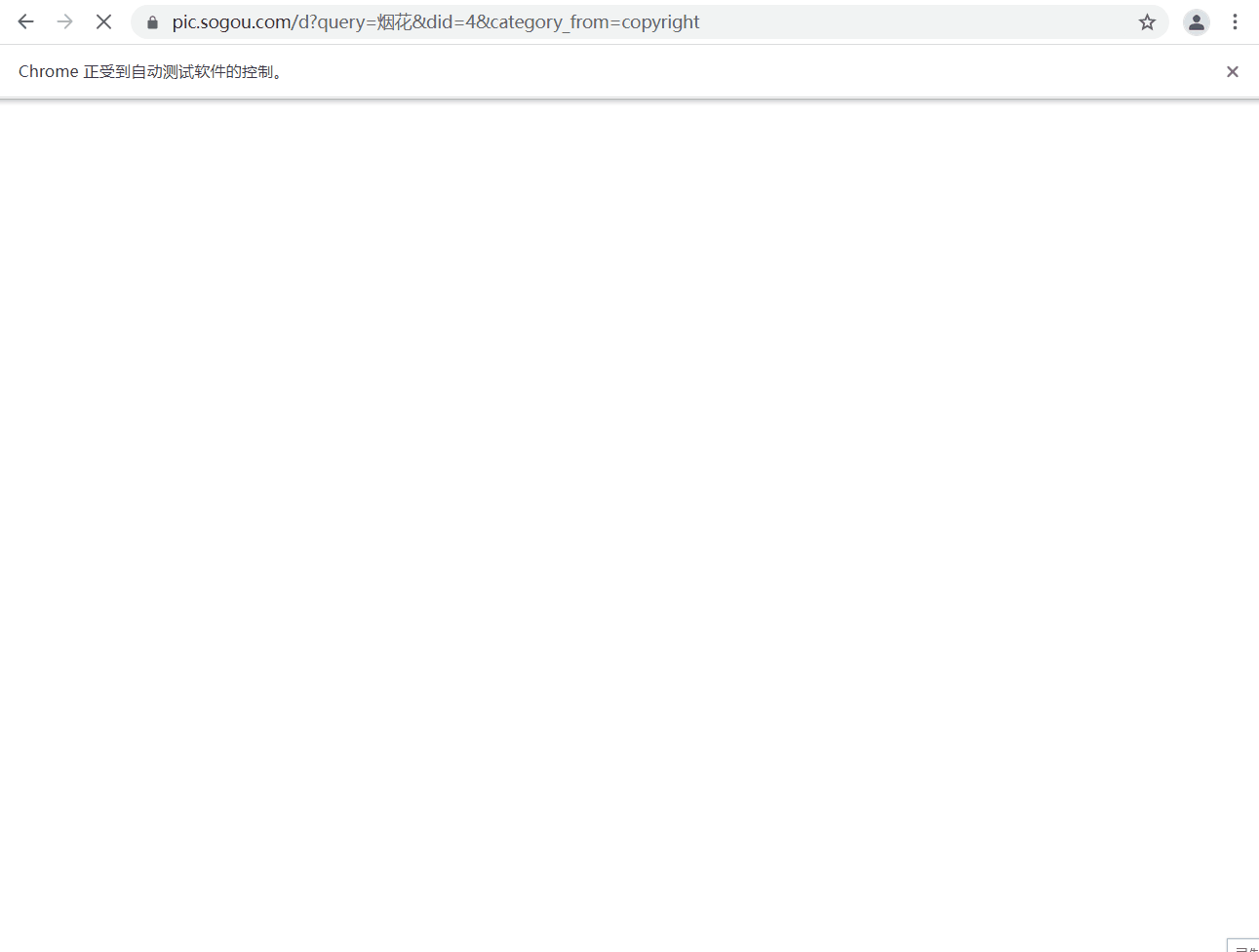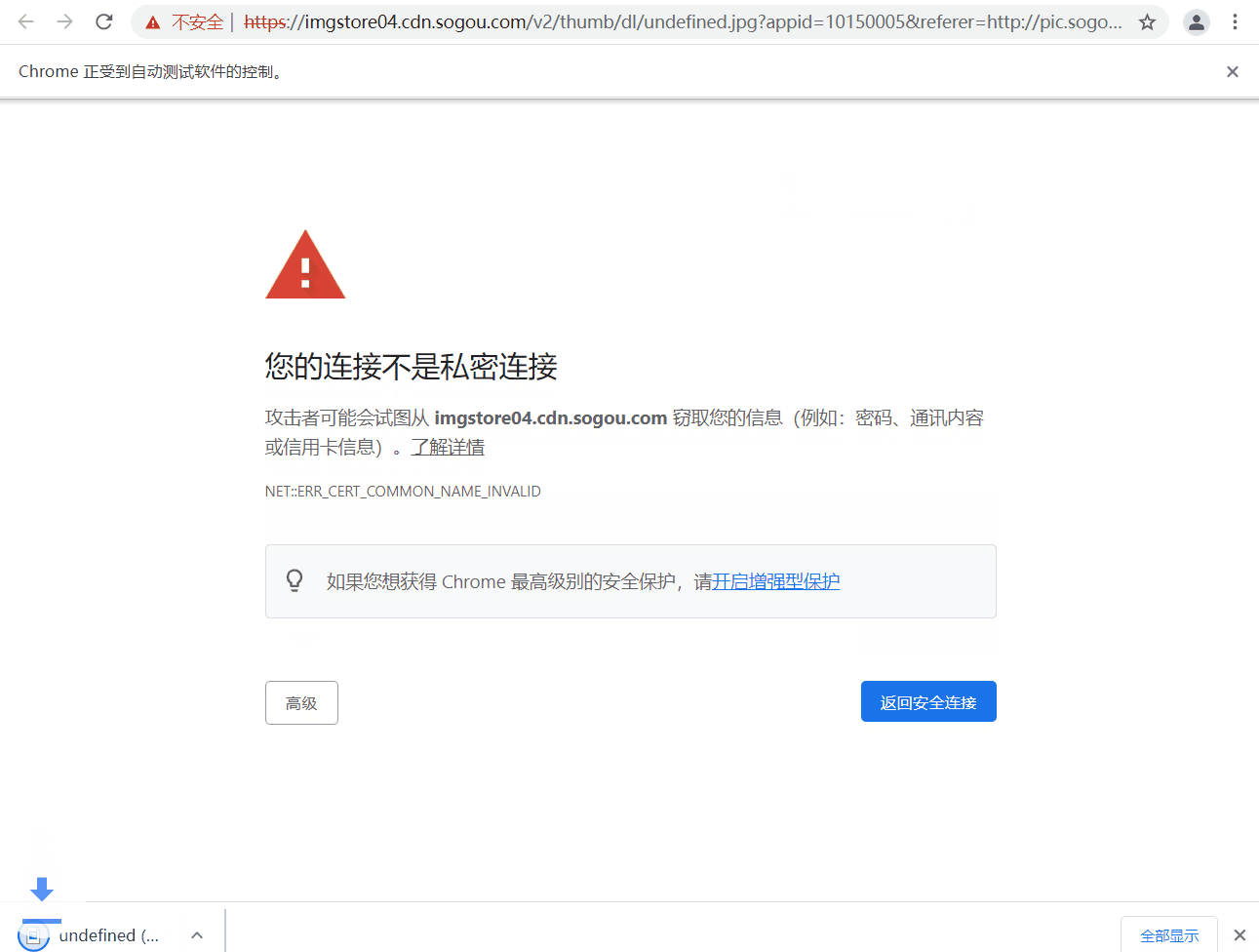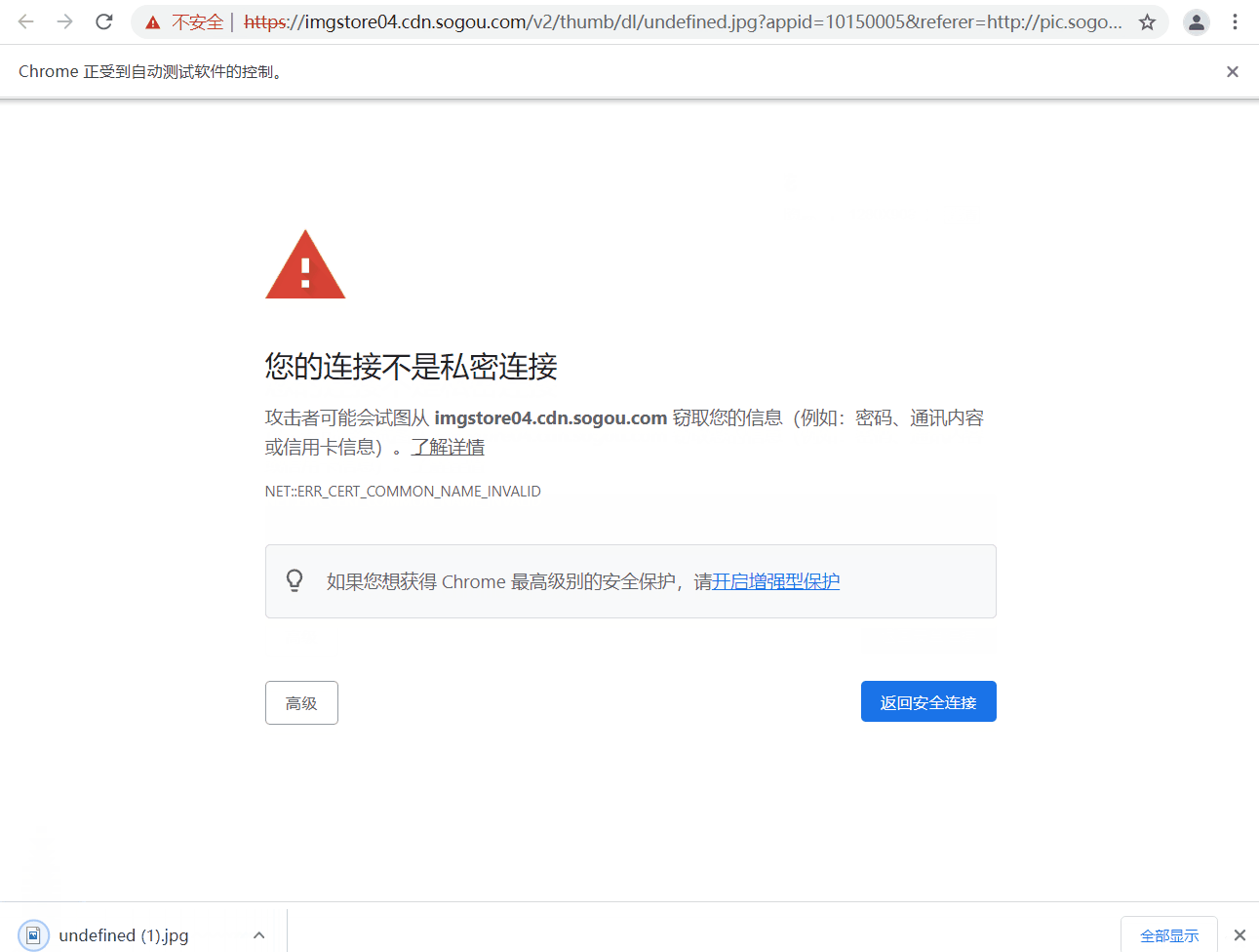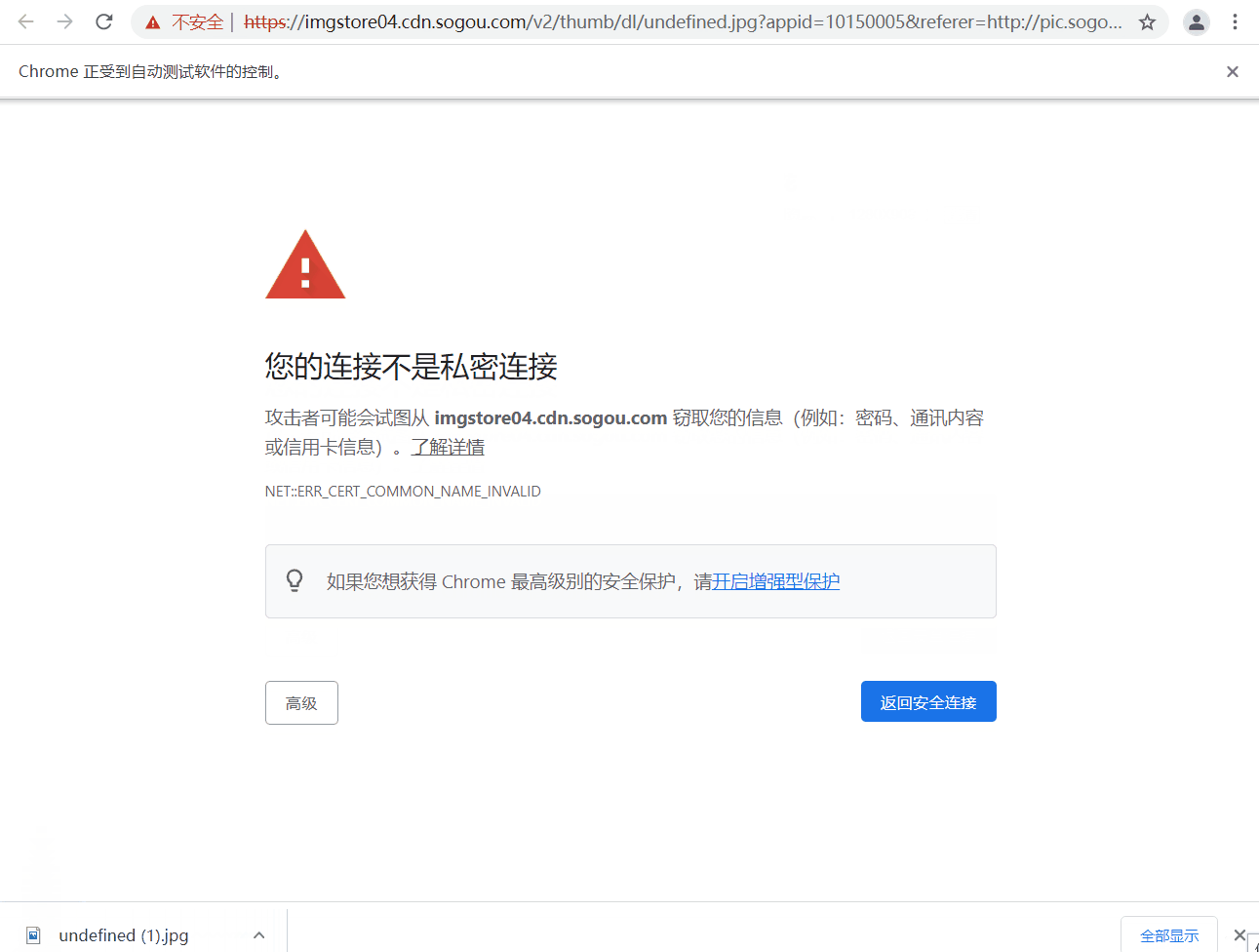
>
> 代码最后两句猜测有理解什么意思的吗~,哈哈,实际作用是当你弹出像下面的页面 “您的连接不是私密连接” 时,可以直接键盘输入 “thisisunsafe” 直接访问链接。那么这个键盘输入字符串的操作就是之间讲到的 `send_keys`,但由于该标签页是新打开的,所以要通过 `switch_to.window()` 将窗口切换到最新的标签页。
>
>
>
##### Firefox浏览器
`Firefox` 浏览器要想实现文件下载,需要通过 `set_preference` 设置 `FirefoxProfile()` 的一些属性。
* `browser.download.foladerList`:0 代表按浏览器默认下载路径;2 保存到指定的目录。
* `browser.download.dir`:指定下载目录。
* `browser.download.manager.showWhenStarting`:是否显示开始,`boolean` 类型。
* `browser.helperApps.neverAsk.saveToDisk`:对指定文件类型不再弹出框进行询问。
* **HTTP Content-type对照表**:<https://www.runoob.com/http/http-content-type.html>
from selenium import webdriver
import os
fp = webdriver.FirefoxProfile()
fp.set_preference(“browser.download.dir”,os.getcwd())
fp.set_preference(“browser.download.folderList”,2)
fp.set_preference(“browser.download.manager.showhenStarting”,True)
fp.set_preference(“browser.helperApps.neverAsk.saveToDisk”,“application/octet-stream”)
driver = webdriver.Firefox(firefox_profile = fp)
driver.get(“https://pic.sogou.com/d?query=%E7%83%9F%E8%8A%B1&did=4&category_from=copyright”)
driver.find_element_by_xpath(‘/html/body/div/div/div/div[2]/div[1]/div[2]/div[1]/div[2]/a’).click()
运行效果与 `Chrome` 基本一致,这里就不再展示了。
---
### cookies操作
`cookies` 是识别用户登录与否的关键,爬虫中常常使用 `selenium + requests` 实现 `cookie`持久化,即先用 `selenium` 模拟登陆获取 `cookie` ,再通过 `requests` 携带 `cookie` 进行请求。
`webdriver` 提供 `cookies` 的几种操作:读取、添加删除。
* `get_cookies`:以字典的形式返回当前会话中可见的 `cookie` 信息。
* `get_cookie(name)`:返回 `cookie` 字典中 `key == name` 的 `cookie` 信息。
* `add_cookie(cookie_dict)`:将 `cookie` 添加到当前会话中
* `delete_cookie(name)`:删除指定名称的单个 `cookie`。
* `delete_all_cookies()`:删除会话范围内的所有 `cookie`。
下面看一下简单的示例,演示了它们的用法。
from selenium import webdriver
driver = webdriver.Chrome()
driver.get(“https://blog.youkuaiyun.com/”)
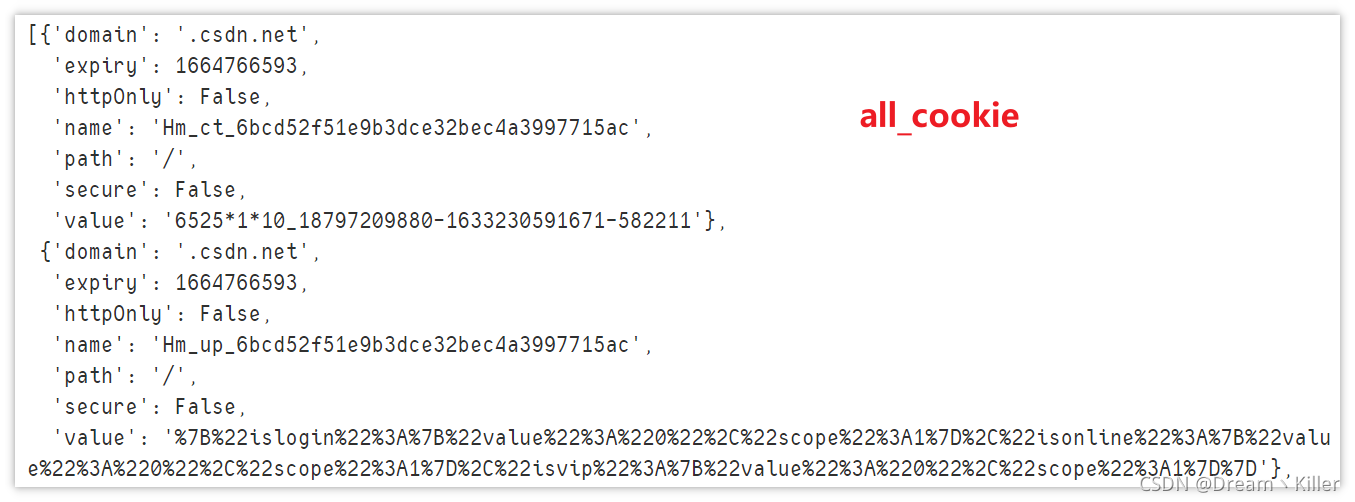
输出所有cookie信息
print(driver.get_cookies())
cookie_dict = {
‘domain’: ‘.youkuaiyun.com’,
‘expiry’: 1664765502,
‘httpOnly’: False,
‘name’: ‘test’,
‘path’: ‘/’,
‘secure’: True,
‘value’: ‘null’}
添加cookie
driver.add_cookie(cookie_dict)
显示 name = ‘test’ 的cookie信息
print(driver.get_cookie(‘test’))
删除 name = ‘test’ 的cookie信息
driver.delete_cookie(‘test’)
删除当前会话中的所有cookie
driver.delete_all_cookies()

---
### 调用JavaScript
`webdriver` 对于滚动条的处理需要用到 `JavaScript` ,同时也可以向 `textarea` 文本框中输入文本( `webdriver` 只能定位,不能输入文本),`webdriver` 中使用execute\_script方法实现 `JavaScript` 的执行。
#### 滑动滚动条
##### 通过 x ,y 坐标滑动
对于这种通过坐标滑动的方法,我们需要知道做表的起始位置在页面左上角(0,0),下面看一下示例,滑动 优快云 首页。
from selenium import webdriver
from time import sleep
driver = webdriver.Chrome()
driver.get(“https://blog.youkuaiyun.com/”)
sleep(1)
js = “window.scrollTo(0,500);”
driver.execute_script(js)
#### 通过参照标签滑动
这种方式需要先找一个参照标签,然后将滚动条滑动至该标签的位置。下面还是用 优快云 首页做示例,我们用循环来实现重复滑动。该 `li` 标签实际是一种**懒加载**,当用户滑动至最后标签时,才会加载后面的数据。
from selenium import webdriver
from time import sleep
driver = webdriver.Chrome()
driver.get(“https://blog.youkuaiyun.com/”)
sleep(1)
driver.implicitly_wait(3)
for i in range(31, 102, 10):
sleep(1)
target = driver.find_element_by_xpath(f’//*[@id=“feedlist_id”]/li[{i}]')
driver.execute_script(“arguments[0].scrollIntoView();”, target)
---
### 其他操作
#### 关闭所有页面
使用 `quit()` 方法可以关闭所有窗口并退出驱动程序。
driver.quit()
#### 关闭当前页面
使用 `close()` 方法可以关闭当前页面,使用时要注意 “当前页面” 这四个字,当你关闭新打开的页面时,需要切换窗口才能操作新窗口并将它关闭。,下面看一个简单的例子,这里不切换窗口,看一下是否能够关闭新打开的页面。
from selenium import webdriver
from time import sleep
driver = webdriver.Chrome()
driver.get(‘https://blog.youkuaiyun.com/’)
driver.implicitly_wait(3)
点击进入新页面
driver.find_element_by_xpath(‘//*[@id=“mainContent”]/aside/div[1]/div’).click()
切换窗口
driver.switch_to.window(driver.window_handles[-1])
sleep(3)
driver.close()
可以看到,在不切换窗口时,`driver` 对象还是操作最开始的页面。
#### 对当前页面进行截图
`wendriver` 中使用 `get_screenshot_as_file()` 对 “当前页面” 进行截图,这里和上面的 `close()` 方法一样,对于新窗口的操作,一定要切换窗口,不然截的还是原页面的图。对页面截图这一功能,主要用在我们测试时记录报错页面的,我们可以将 `try except` 结合 `get_screenshot_as_file()` 一起使用来实现这一效果。
try:
driver.find_element_by_xpath(‘//*[@id=“mainContent”]/aside/div[1]/div’).click()
except:
driver.get_screenshot_as_file(r’C:\Users\pc\Desktop\screenshot.png’)
#### 常用方法总结
获取当前页面url
driver.current_url
获取当前html源码
driver.page_source
获取当前页面标题
driver.title
获取浏览器名称(chrome)
driver.name
对页面进行截图,返回二进制数据
driver.get_screenshot_as_png()
设置浏览器尺寸
driver.get_window_size()
获取浏览器尺寸,位置
driver.get_window_rect()
获取浏览器位置(左上角)
driver.get_window_position()
设置浏览器尺寸
driver.set_window_size(width=1000, height=600)
设置浏览器位置(左上角)
driver.set_window_position(x=500, y=600)
设置浏览器的尺寸,位置
driver.set_window_rect(x=200, y=400, width=1000, height=600)
---
### selenium进阶
#### selenium隐藏指纹特征
`selenium` 对于部分网站来说十分强大,但它也不是万能的,实际上,`selenium` 启动的浏览器,有几十个特征可以被网站检测到,轻松的识别出你是爬虫。
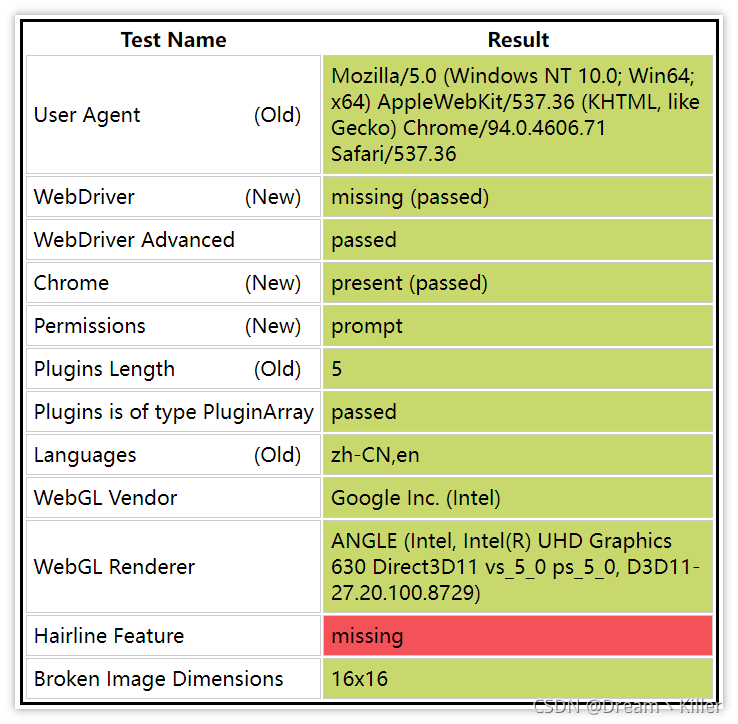
不相信?接着往下看,首先你手动打开浏览器输入<https://bot.sannysoft.com/>,在网络无异常的情况下,显示应该如下:
下面通过 `selenium` 来打开浏览器。
from selenium import webdriver
driver = webdriver.Chrome()
driver.get(‘https://bot.sannysoft.com/’)
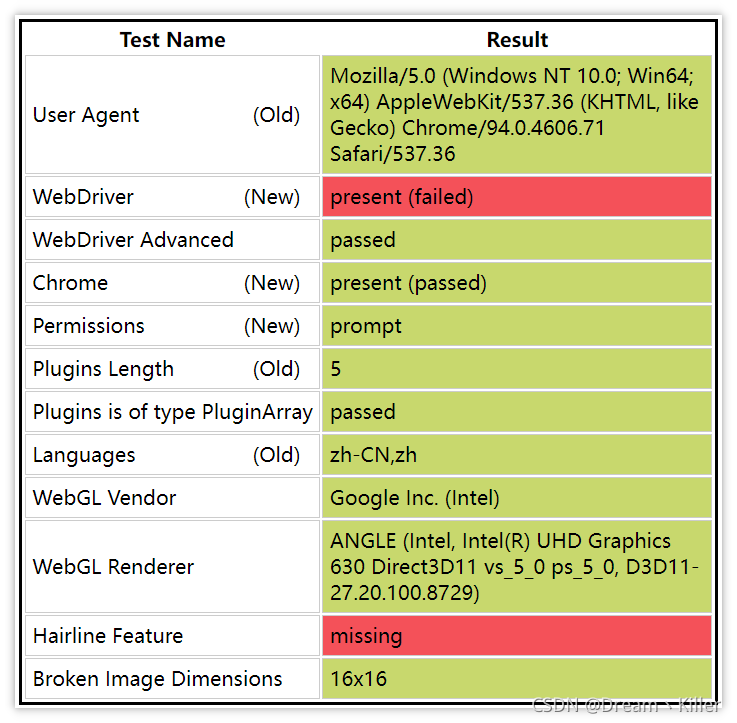
通过 `webdriver:present` 可以看到浏览器已经识别出了你是爬虫,我们再试一下无头浏览器。
from selenium import webdriver
设置无头浏览器
option = webdriver.ChromeOptions()
option.add_argument(‘–headless’)
driver = webdriver.Chrome()
driver.get(‘https://bot.sannysoft.com/’)
对当前页面进行截图
driver.save_screenshot(‘page.png’)

没错,就是这么真实,对于常规网站可能没什么反爬,但真正想要抓你还是一抓一个准的。
说了这么多,是不是 `selenium` 真的不行?别着急,实际还是解决方法的。关键点在于如何在浏览器检测之前将这些特征进行隐藏,事实上,前人已经为我们铺好了路,解决这个问题的关键,实际就是一个 `stealth.min.js` 文件,这个文件是给 `puppeteer` 用的,在 `Python` 中使用的话需要单独执行这个文件,该文件获取方式需要安装 `node.js` ,如果已安装的读者可以直接运行如下命令即可在当前目录生成该文件。
npx extract-stealth-evasions
这里我已经成功获取了 `stealth.min.js` 文件。
链接:<https://pan.baidu.com/s/1O6co1Exa8eks6QmKAst91g>
**提取码:关注文末小卡片回复“隐藏指纹特征”获取**
下面我们在网站检测之前先执行该js文件隐藏特征,同样使用无头浏览器,看是否有效。
import time
from selenium.webdriver import Chrome
option = webdriver.ChromeOptions()
option.add_argument(“–headless”)
无头浏览器需要添加user-agent来隐藏特征
option.add_argument(‘user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36’)
driver = Chrome(options=option)
driver.implicitly_wait(5)
with open(‘stealth.min.js’) as f:
js = f.read()
driver.execute_cdp_cmd(“Page.addScriptToEvaluateOnNewDocument”, {
“source”: js
})
driver.get(‘https://bot.sannysoft.com/’)
driver.save_screenshot(‘hidden_features.png’)
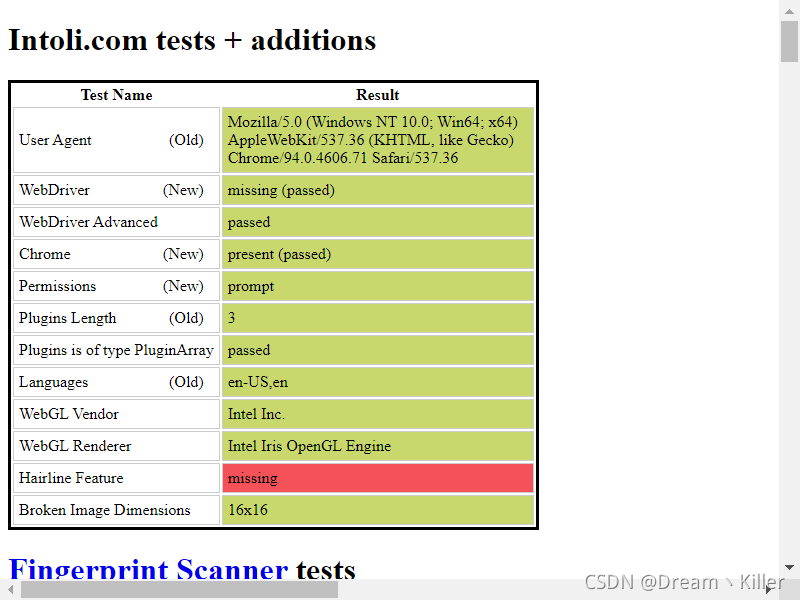
通过 `stealth.min.js` 的隐藏,可以看到这次使用无头浏览器特征基本都以隐藏,已经十分接近人工打开浏览器了。
---
### 实战:selenium模拟登录B站
#### 登录验证码处理
`selenium` 中的难点验证码破解在上文中并没有提及,因为确实没有很好的方式,一般都需要通过第三方平台实现破解,本案例中使用的是[超级鹰]( )平台(收费,大概1元30次,测试用冲个1元就足够)。下面实战开始!
#### 分析登录界面结构
B站登录界面如下。
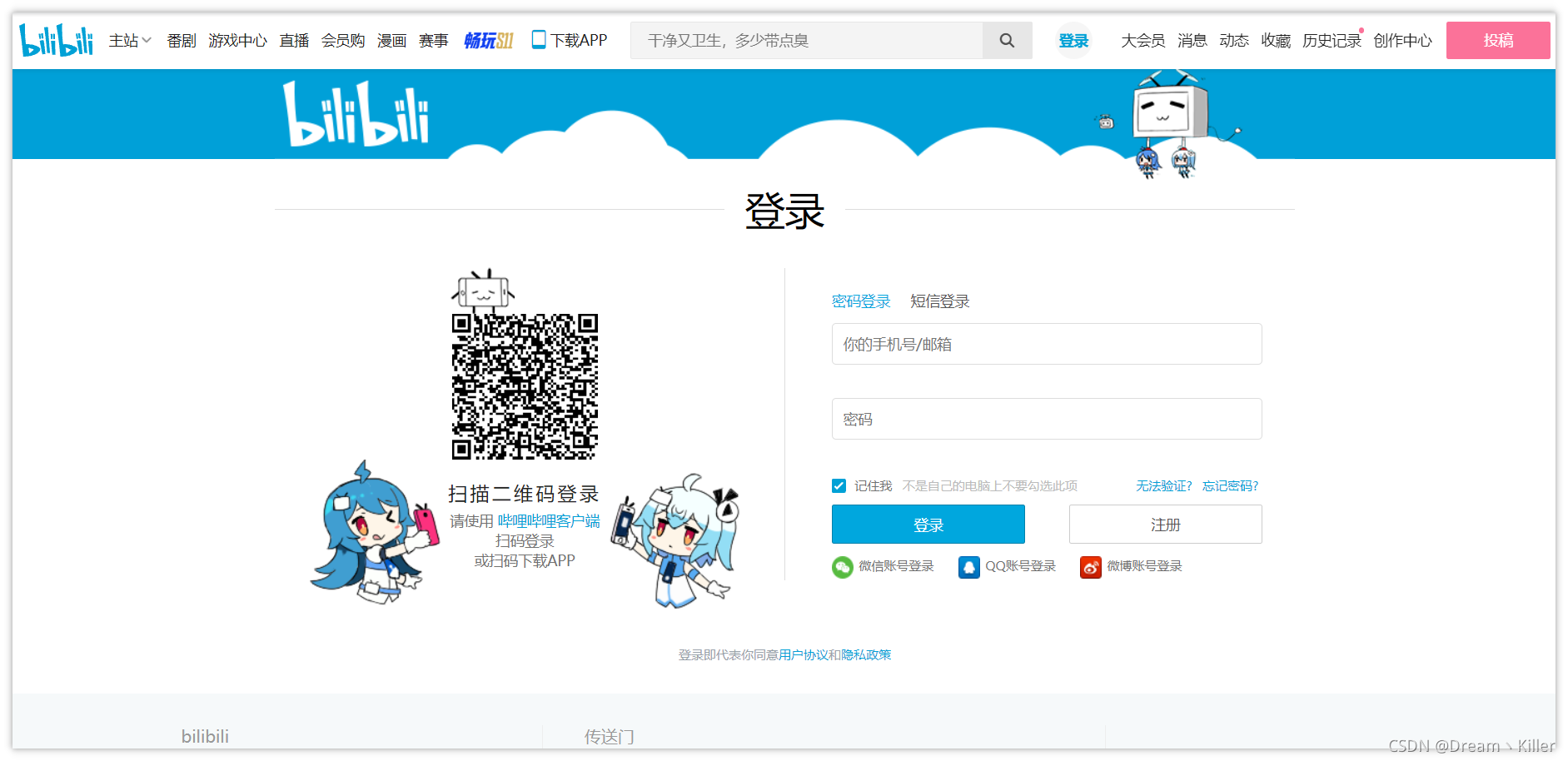
首先明确我们的目标,打开登陆界面,定位用户名和密码对应的标签,输入相关数据后,点击登录,此时页面会弹出文字验证码。
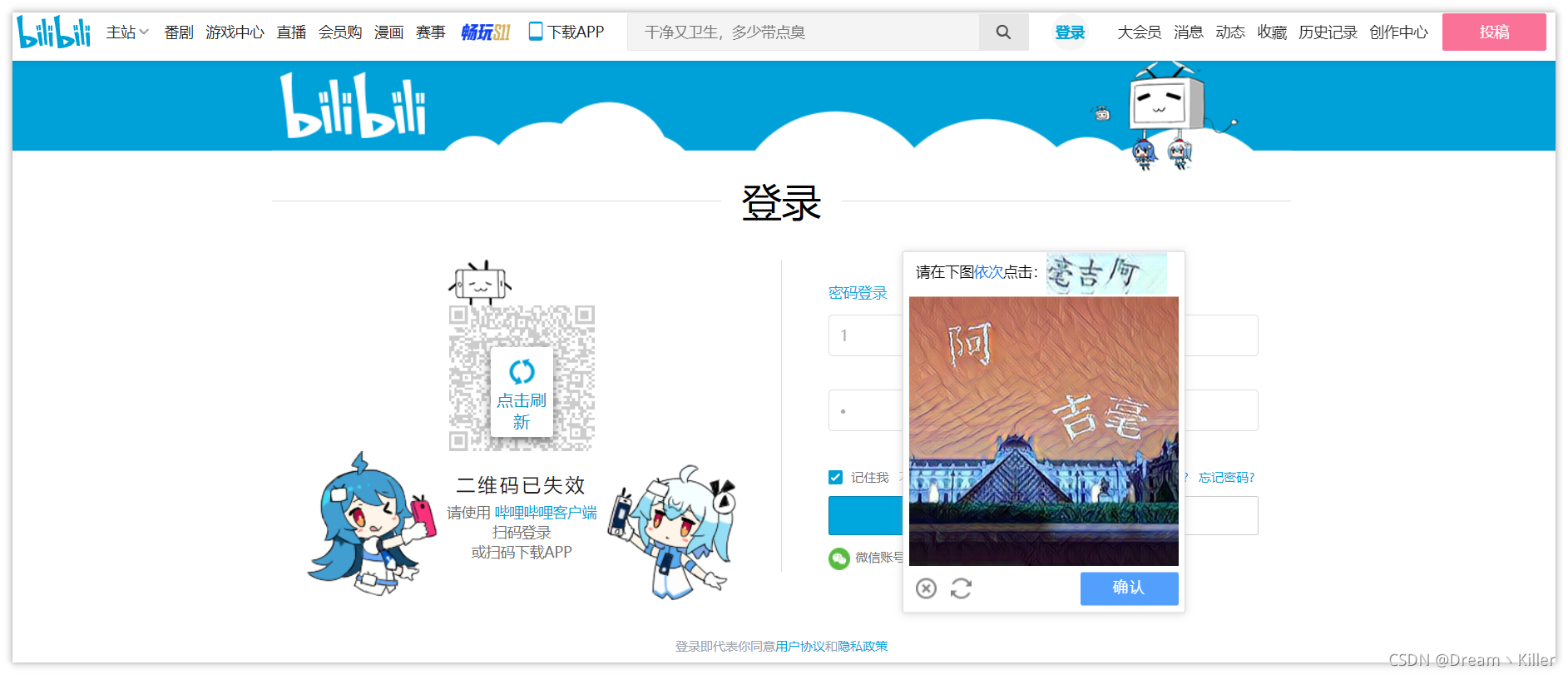
下文会用两种方法进行验证码图片的获取,并提交给超级鹰进行识别,接收到汉字的坐标后,处理坐标数据,然后用动作链点击对应坐标操作,完成登录。
下面使用 `selenium` 打开登录页面。
driver.get(‘https://passport.bilibili.com/login’)
定位用户名,密码输入框
username = driver.find_element_by_id(‘login-username’)
password = driver.find_element_by_id(‘login-passwd’)
将自己的用户名密码替换xxxxxx
username.send_keys(‘xxxxxx’)
password.send_keys(‘xxxxxx’)
定位登录按钮并点击
driver.find_element_by_xpath(‘//*[@id=“geetest-wrap”]/div/div[5]/a[1]’).click()
#### 获取页面当前验证码图片
##### 方法一、页面截图,将验证码区域进行裁剪保存
使用此方法时,注意我们截取验证码图片时需要**截取完整**,不要只截图片部分,上面文字也需要。完整验证码截图如下:
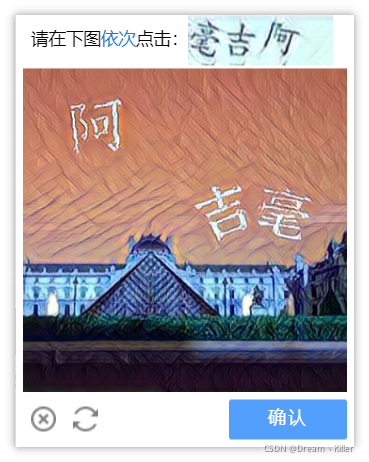
首先将点击登录后的页面进行**截图**,然后**定位**到验证码的位置,通过**location()**方法获取验证码左上角的坐标,** size()** 获取验证码的宽和高,左上角坐标加上宽和高就是验证码右下角的坐标。获取坐标后就可以用\*\*crop()\*\*方法来进行裁剪,然后将裁剪到的验证码图片保存。
此时虽然获取了验证码图片,但是还不能直接提交给超级鹰。
因为超级鹰识别的验证码图片的**宽和高有限制**,最好不超过 `460px,310px`。
但是截取到的验证码图片宽高为 `338px,432px`,这时就要先将图片缩小一倍再提交即可,等到收到坐标数据再将**坐标乘2**。
def save_img():
# 对当前页面进行截图保存
driver.save_screenshot(‘page.png’)
# 定位验证码图片的位置
code_img_ele = driver.find_element_by_xpath(‘/html/body/div[2]/div[2]/div[6]/div/div’)
# 获取验证码左上角的坐标x,y
location = code_img_ele.location
# 获取验证码图片对应的长和宽
size = code_img_ele.size
# 左上角和右下角的坐标
rangle = (
int(location['x'] \* 1.25), int(location['y'] \* 1.25), int((location['x'] + size['width']) \* 1.25),
int((location['y'] + size['height']) \* 1.25)
)
i = Image.open('./page.png')
code_img_name = './code.png'
# crop根据rangle元组内的坐标进行裁剪
frame = i.crop(rangle)
frame.save(code_img_name)
return code_img_ele
def narrow_img():
# 缩小图片
code = Image.open(‘./code.png’)
small_img = code.resize((169, 216))
small_img.save(‘./small_img.png’)
print(code.size, small_img.size)
##### 方法二、通过网页获取图片地址,并保存
这种方法比上一种更加方便,分析网页源码获取图片地址,对该地址发送请求,接收返回的二进制文件,进行保存。首先打开网页源码找到图片地址。
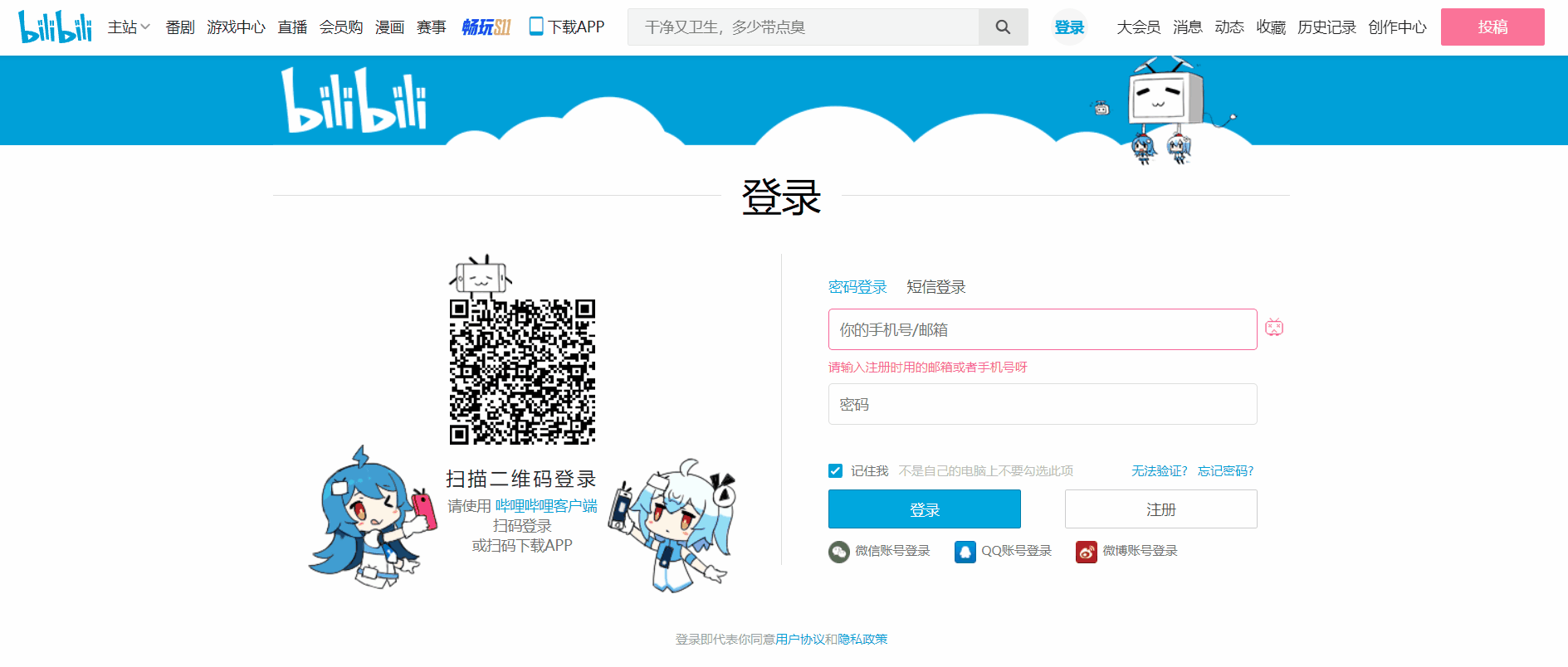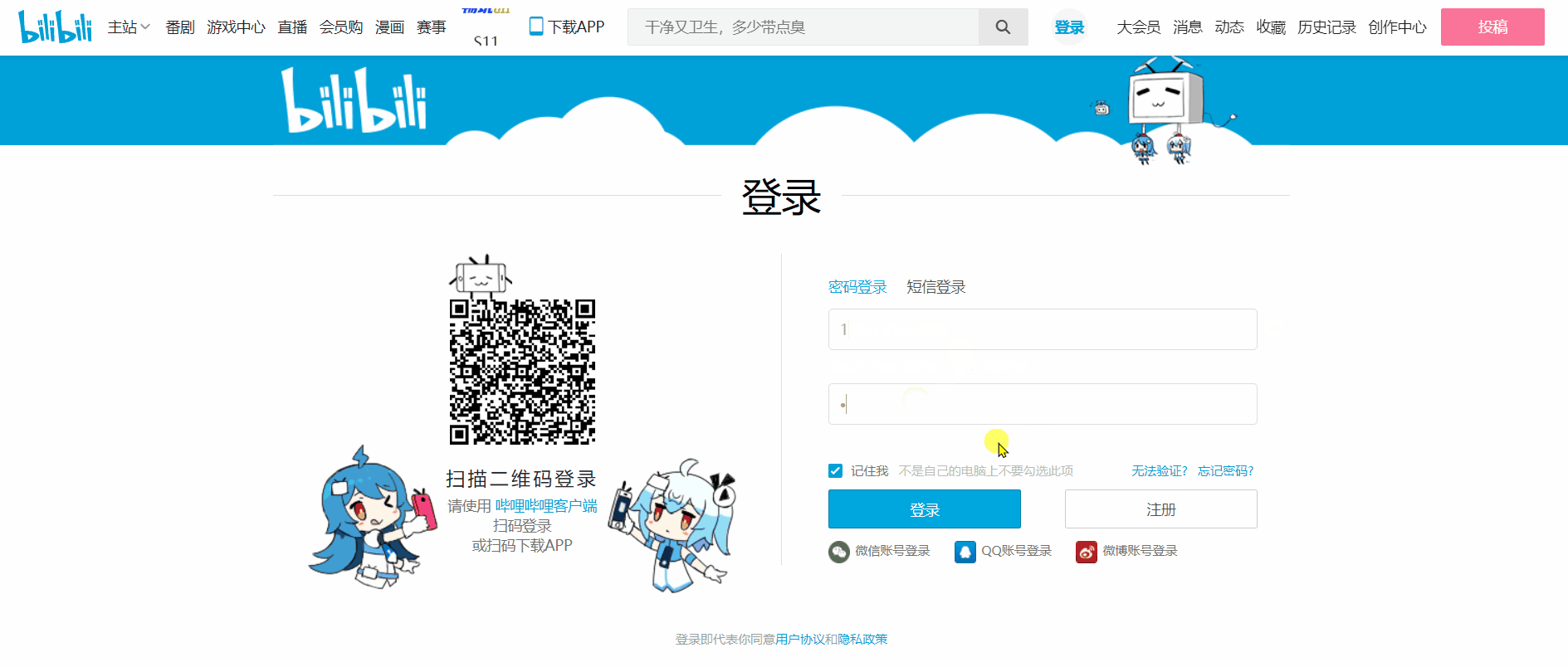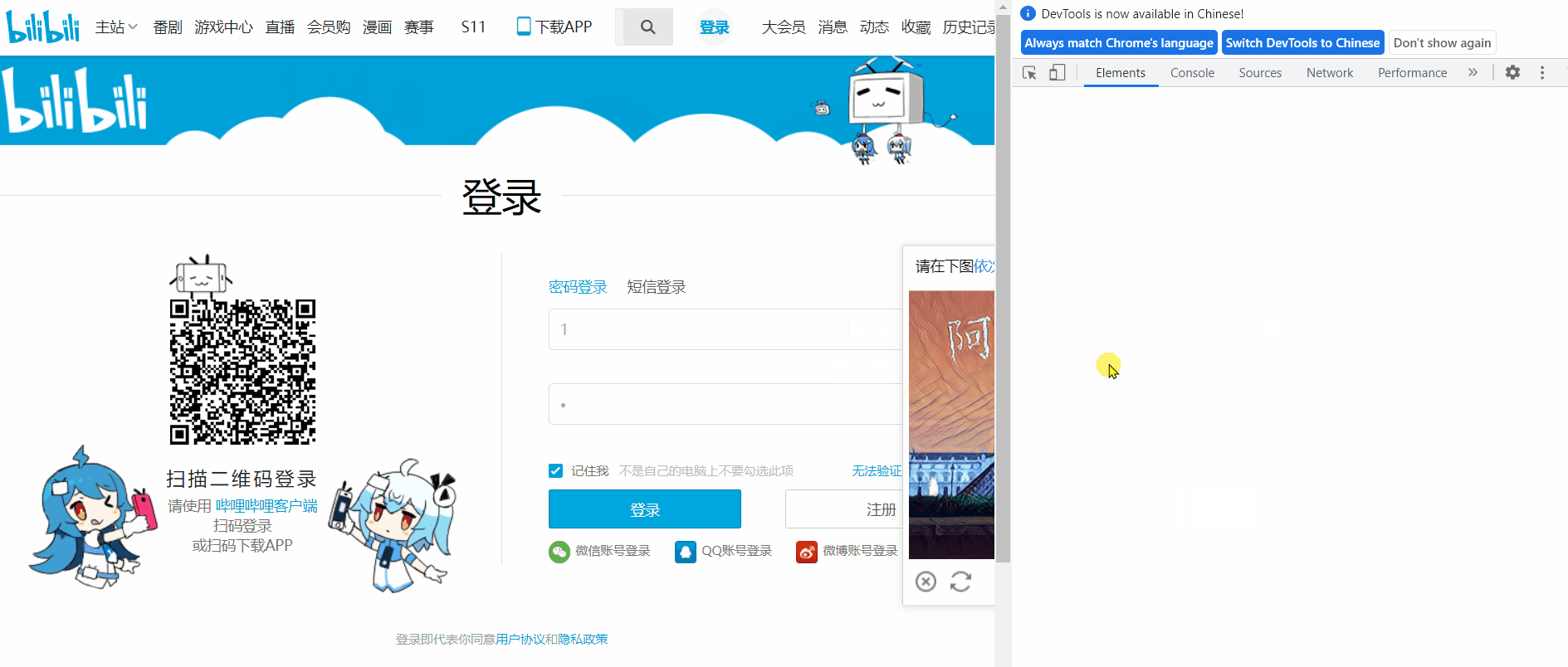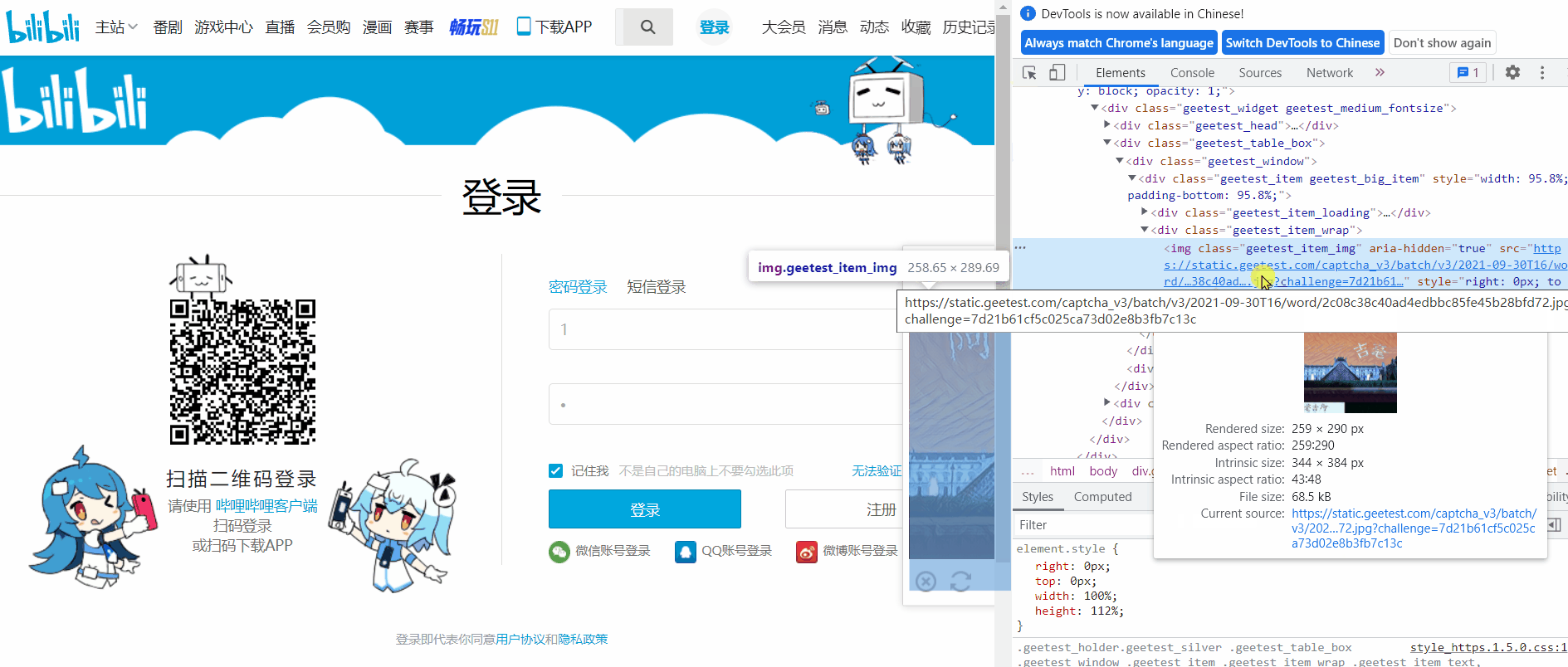
图片地址是 `img` 标签的 `src` 属性值,通过 `xpath` 得到地址,直接对此 `url` 发送请求,接收数据并保存即可。
注意:由于获取的图片的高度仍然大于超级鹰标准格式,所以也需要将图片缩小。
获取img标签的src属性值
img_url = driver.find_element_by_xpath(‘/html/body/div[2]/div[2]/div[6]/div/div/div[2]/div[1]/div/div[2]/img’).get_attribute(‘src’)
headers = {
‘Users-Agent’: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36’
}
获取图片二进制数据
img_data = requests.get(url=img_url, headers=headers).content
with open(‘./node1.png’, ‘wb’)as fp:
fp.write(img_data)
i = Image.open(‘./node1.png’)
将图片缩小并保存,设置宽为172,高为192
small_img = i.resize((172, 192))
small_img.save(‘./small_img1.png’)
#### 使用超级鹰识别验证码
这部分没什么说的,直接调用就行。
将验证码提交给超级鹰进行识别
chaojiying = Chaojiying_Client(‘用户名’, ‘密码’, ‘96001’) # 用户中心>>软件ID 生成一个替换 96001
im = open(‘small_img.png’, ‘rb’).read() # 本地图片文件路径 来替换 a.jpg 有时WIN系统须要//
9004是验证码类型
print(chaojiying.PostPic(im, 9004)[‘pic_str’])
result = chaojiying.PostPic(im, 9004)[‘pic_str’]
#### 提取坐标数据,动作链点击
超级鹰识别返回的数据格式是:`123,12 | 234,21` 。我们可以将数据以 `' | '` 进行分割,保存到列表中,再以逗号分割将 `x,y` 的坐标保存,得到 `[ [123,12],[234,21] ]` 这一格式,然后遍历这一列表,使用动作链对每一个列表元素对应的 `x,y` 指定的位置进行点击操作,最后定位并点击确认,登录成功。
all_list = [] # 要存储即将被点击的点的坐标 [[x1,y1],[x2,y2]]
if ‘|’ in result:
写在最后
在结束之际,我想重申的是,学习并非如攀登险峻高峰,而是如滴水穿石般的持久累积。尤其当我们步入工作岗位之后,持之以恒的学习变得愈发不易,如同在茫茫大海中独自划舟,稍有松懈便可能被巨浪吞噬。然而,对于我们程序员而言,学习是生存之本,是我们在激烈市场竞争中立于不败之地的关键。一旦停止学习,我们便如同逆水行舟,不进则退,终将被时代的洪流所淘汰。因此,不断汲取新知识,不仅是对自己的提升,更是对自己的一份珍贵投资。让我们不断磨砺自己,与时代共同进步,书写属于我们的辉煌篇章。
需要完整版PDF学习资源私我
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip204888 (备注网络安全)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
esize((172, 192))
small_img.save(‘./small_img1.png’)
#### 使用超级鹰识别验证码
这部分没什么说的,直接调用就行。
将验证码提交给超级鹰进行识别
chaojiying = Chaojiying_Client(‘用户名’, ‘密码’, ‘96001’) # 用户中心>>软件ID 生成一个替换 96001
im = open(‘small_img.png’, ‘rb’).read() # 本地图片文件路径 来替换 a.jpg 有时WIN系统须要//
9004是验证码类型
print(chaojiying.PostPic(im, 9004)[‘pic_str’])
result = chaojiying.PostPic(im, 9004)[‘pic_str’]
#### 提取坐标数据,动作链点击
超级鹰识别返回的数据格式是:`123,12 | 234,21` 。我们可以将数据以 `' | '` 进行分割,保存到列表中,再以逗号分割将 `x,y` 的坐标保存,得到 `[ [123,12],[234,21] ]` 这一格式,然后遍历这一列表,使用动作链对每一个列表元素对应的 `x,y` 指定的位置进行点击操作,最后定位并点击确认,登录成功。
all_list = [] # 要存储即将被点击的点的坐标 [[x1,y1],[x2,y2]]
if ‘|’ in result:
写在最后
在结束之际,我想重申的是,学习并非如攀登险峻高峰,而是如滴水穿石般的持久累积。尤其当我们步入工作岗位之后,持之以恒的学习变得愈发不易,如同在茫茫大海中独自划舟,稍有松懈便可能被巨浪吞噬。然而,对于我们程序员而言,学习是生存之本,是我们在激烈市场竞争中立于不败之地的关键。一旦停止学习,我们便如同逆水行舟,不进则退,终将被时代的洪流所淘汰。因此,不断汲取新知识,不仅是对自己的提升,更是对自己的一份珍贵投资。让我们不断磨砺自己,与时代共同进步,书写属于我们的辉煌篇章。
需要完整版PDF学习资源私我
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip204888 (备注网络安全)
[外链图片转存中…(img-jfiWF6YB-1713401890951)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!

















 28万+
28万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









