






 本文详细介绍了多任务的概念,包括并发和并行的区别,以及在Python中如何通过进程和线程实现多任务。重点讲解了进程的创建、执行、参数传递和管理,以及线程的使用、同步和全局变量共享。最后对比了进程和线程的优缺点及适用场景。
本文详细介绍了多任务的概念,包括并发和并行的区别,以及在Python中如何通过进程和线程实现多任务。重点讲解了进程的创建、执行、参数传递和管理,以及线程的使用、同步和全局变量共享。最后对比了进程和线程的优缺点及适用场景。
一、多任务概念
1.1 多任务概念
多任务是指在同一时间内执行多个任务。
1.2 多任务的两种表现形式
- 并发
- 并行
1.3 并发
在一段时间内**交替**去执行多个任务。
例子:
对于单核CPU处理多任务,操作系统轮流让各个任务交替执行,假如:软件1执行0.01秒,切换到软件2,软件2执行0.01秒,再切换到软件3,执行0.01秒…这样反复执行下去,实际上每个软件都是交替执行的.但是,由于CPU的执行速度实在是太快了,表面上我们感觉就像这些软件都在同时执行一样.这里需要注意单核cpu是并发的执行多任务的。
1.4 并行
在一段时间内真正的同时一起执行多个任务。
二、进程的介绍
2.1 程序中实现多任务的方式
在python中,想要实现多任务可以使用**进程或线程**来完成。
2.2 进程的概念
进程(Process)是资源分配的最小单位,**它是操作系统进行资源分配和调度运行的基本单位**,通俗理解:一个正在运行的程序就是一个进程.
例如:正在运行的qq,微信等他们都是进程.
2.3 多进程的作用
多进程是python程序中实现多任务的一种方式,使用多进程可以大大提高程序的执行效率。
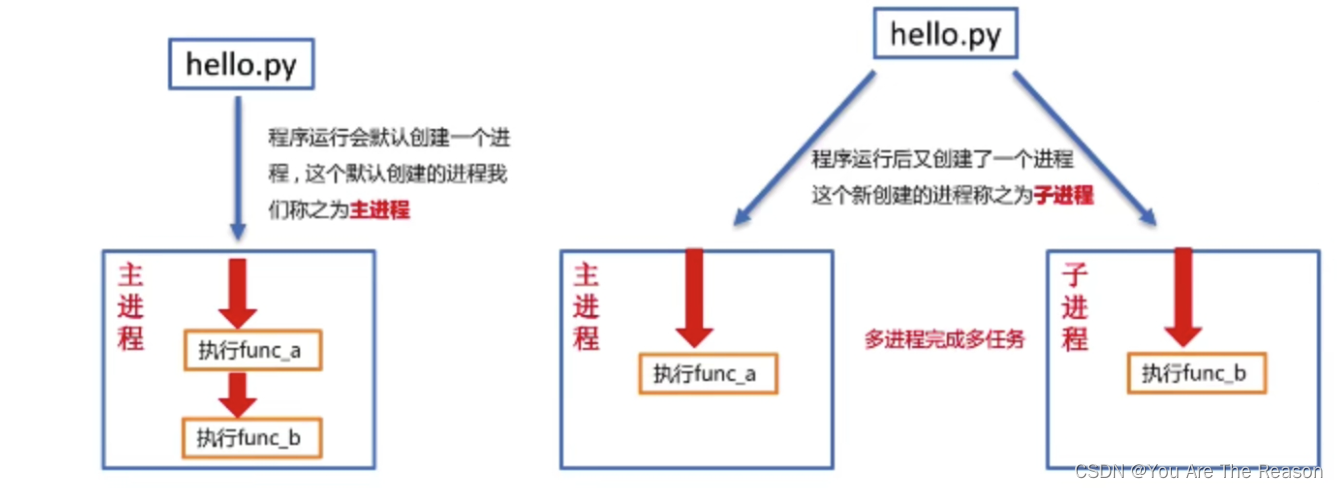
2.4 进程的创建步骤
- 导入进程包
import multiprocessing - 通过进程类创建进程对象
进程对象=multiprocessing.Process(target=函数名) - 启动进程执行任务
进程对象.start()
2.5 多进程的代码实现
import time
#导入进程包
import multiprocessing
#编写代码
def coding():
for i in range(3):
print("coding...")
time.sleep(0.2)
#听音乐
def music():
for i in range(3):
print("music...")
time.sleep(0.2)
if __name__ == '__main__':
#通过进程类创建进程对象
#target:函数名
coding_process = multiprocessing.Process(target=coding)
music_process = multiprocessing.Process(target=music)
#启动进程
coding_process.start()
music_process.start()
2.6 进程执行带有参数的任务
-
进程执行带有参数的任务传参有两种方式:
- 元组方式传参:
元组方式传参一定要和参数的顺序保待一致。 - 字典方式传参:
字典方式传参字典中的key一定要和参数名保持一致。
- 元组方式传参:
import time
#导入线程模块
import threading
#编写代码
def coding(num):
for i in range(num):
print("coding...")
time.sleep(0.2)
#听音乐
def music(count):
for i in range(count):
print("music...")
time.sleep(0.2)
if __name__ == '__main__':
#创建子线程
coding_thread = threading.Thread(target=coding,args=(3,))
music_thread = threading.Thread(target=music,kwargs={"count":2})
#启动线程执行任务
coding_thread.start()
music_thread.start()
2.7 获取进程编号
进程编号的作用:
当程序中进程的数量越来越多,就无法区分主进程和子进程还有不同的子进程,实际上为了方便管理,每个进程都是有自己的编号的,通过获取进程编号就可以快速区分不同的进程。
获取进程编号的方法:
- 获取当前进程编号
getpid()方法 - 获取当前父进程编号
getppid()方法
#导入进程包
import multiprocessing
import os
import time
#编写代码
def coding():
#获取子进程编号
print('coding>>>%d' % os.getpid())
# 获取父进程编号
print('coding父进程>>>%d' % os.getppid())
for i in range(3):
print("coding...")
time.sleep(0.2)
#听音乐
def music():
# 获取子进程编号
print('music>>>%d' % os.getpid())
#获取父进程编号
print('music父进程>>>%d' % os.getppid())
for i in range(3):
print("music...")
time.sleep(0.2)
if __name__ == '__main__':
#获取主进程编号,子进程是由主进程创建和启动的
print("主进程>>>%d" % os.getpid())
#通过进程类创建进程对象
coding_process = multiprocessing.Process(target=coding)
music_process = multiprocessing.Process(target=music)
#启动进程
coding_process.start()
music_process.start()
执行结果:

2.8 进程间不共享全局变量
进程间不共享全局变量。创建一个子进程就是把主进程的资源进行拷贝产生了一个新的进程,这里主进程和子进程是互相独立的。
代码:
import multiprocessing
import time
'''
三个进程分别操作的都是自己进程里面的全局变量my_list,不会对其他进程里面的全局变量产生影响,
所以进程之间不共享全局变量,只不过进程之间的全局变量名字相同而已,但是操作的不是同一个进程
里面的全局变量
'''
#全局变量
my_list = []
#写入数据
def write_data():
for i in range(3):
my_list.append(i)
print("add:",i)
print("write_data:",my_list)
#读取数据
def read_data():
print("read_data:",my_list)
if __name__ == '__main__':
#创建写入数据子进程
write_process = multiprocessing.Process(target=write_data)
#创建读取数据子进程
read_process = multiprocessing.Process(target=read_data)
#启动进程执行相应任务
write_process.start()
time.sleep(0.2)
read_process.start()
执行结果:
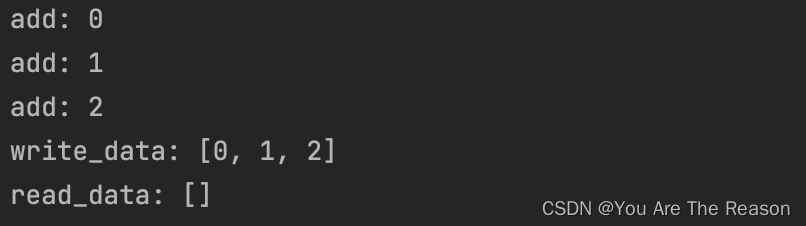
2.9 主进程和子进程的结束顺序
主进程会等待所有的子进程执行结束再结束,工作中常常通过在子进程启动之前创建守护主进程,主进程退出后子进程直接销毁,不再执行子进程中的代码或让子进程直接销毁,表示终止执行,主进程退出之前,把所有的子进程直接销毁。
- 进程对象.daemon = True
- 进程对象.terminate()
代码:
import multiprocessing
import time
def work():
for i in range(10):
print('工作中...')
time.sleep(0.2)
if __name__ == '__main__':
#创建子进程
work_process = multiprocessing.Process(target=work)
#创建守护主进程,主进程退出后子进程直接销毁,不再执行子进程中的代码
#work_process.daemon = True
#启动子进程
work_process.start()
time.sleep(1)
#让子进程直接销毁,表示终止执行,主进程退出之前,把所有的子进程直接销毁
work_process.terminate()
print('主进程执行完毕')
执行结果:

三、 多线程的介绍
3.1 为什么使用多线程?
进程是分配资源的最小单位,一旦创建一个进程就会分配一定的资源,就像跟两个人聊QQ就需要打开两个QQ软件
一样是比较浪费资源的.
线程是程序执行的最小单位,实际上进程只负责分配资源,而利用这些资源执行程序的是线程,也就说进程是线程的
容器,一个进程中最少有一个线程来负责执行程序,同时线程自己不拥有系统资源,只需要一点儿在运行中必不可
少的资源,但它可与同属一个进程的其它线程共享进程所拥有的全部资源,这就像通过一个QQ软件(一个进程)打开
两个窗口(两个线程)跟两个人聊天一样,实现多任务的同时也节省了资源。
3.2 多线程的作用
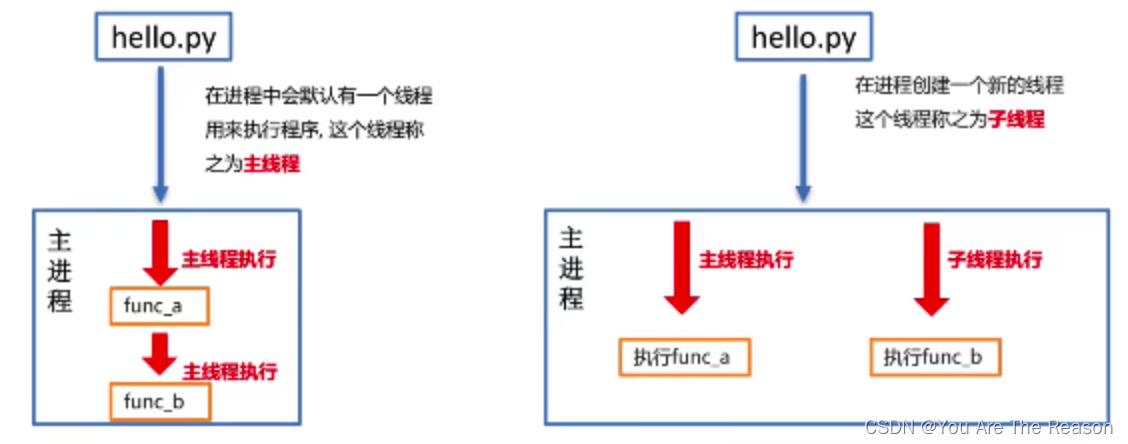
3.3 多线程完成多任务
知识要点:
- 导入线程模块
import threading - 创建子线程并指定执行的任务
sub_thread=threading.Thread(target=任务名) - 启动线程执行任务
sub_thread.start()
代码实现:
import time
#导入线程模块
import threading
#编写代码
def coding():
for i in range(3):
print("coding...")
time.sleep(0.2)
#听音乐
def music():
for i in range(3):
print("music...")
time.sleep(0.2)
if __name__ == '__main__':
#创建子线程
coding_thread = threading.Thread(target=coding)
music_thread = threading.Thread(target=music)
#启动线程执行任务
coding_thread.start()
music_thread.start()
执行结果:

3.4 线程执行带有参数的任务
知识要点:
线程执行带有参数的任务传参有两种方式:
元组方式传参:元组方式传参一定要和参数的顺序保持一到收。字典方式传参:字典方式传参字典中的key一定要和参数名保持一致。
import time
#导入线程模块
import threading
#编写代码
def coding(num):
for i in range(num):
print("coding...")
time.sleep(0.2)
#听音乐
def music(count):
for i in range(count):
print("music...")
time.sleep(0.2)
if __name__ == '__main__':
#创建子线程
coding_thread = threading.Thread(target=coding,args=(3,))
music_thread = threading.Thread(target=music,kwargs={"count":2})
#启动线程执行任务
coding_thread.start()
music_thread.start()
3.5 主线程和子线程的结束顺序
主线程会等所有的子线程执行结束后主线程再结束。设置守护主线程的目的是主线程退出子线程销毁,不让主线程再等待子线程去执行。
设置守护主线程有两种方式:
- threading.Thread(target=函数名, daemon=True)
- 线程对象setDaemon(True)
import threading
import time
def work():
for i in range(10):
print('工作中...')
time.sleep(0.2)
if __name__ == '__main__':
#创建子线程
#方式一:参数方式设置守护主线程
work_thread = threading.Thread(target=work,daemon=True)
#work_thread = threading.Thread(target=work)
#创建守护主线程,主线程退出后子线程直接销毁,不再执行子线程中的代码
#方式二:
#work_thread.setDaemon(True)
#启动子线程
work_thread.start()
time.sleep(1)
print('主进程执行完毕')
执行结果:

3.6 线程间的执行顺序
线程之间的执行是无序的,是由CPU调度决定某个线程先执行的。
代码:
import threading
import time
"""
线程之间的执行是无序的,是由CPU调度决定某个线程先执行的
"""
#获取进程的信息函数
def get_info():
time.sleep(0.5)
#获取进程信息
current_thread = threading.current_thread()
print(current_thread)
if __name__ == '__main__':
#创建子线程
for i in range(10):
sub_thread = threading.Thread(target=get_info)
#启动线程
sub_thread.start()
执行结果:
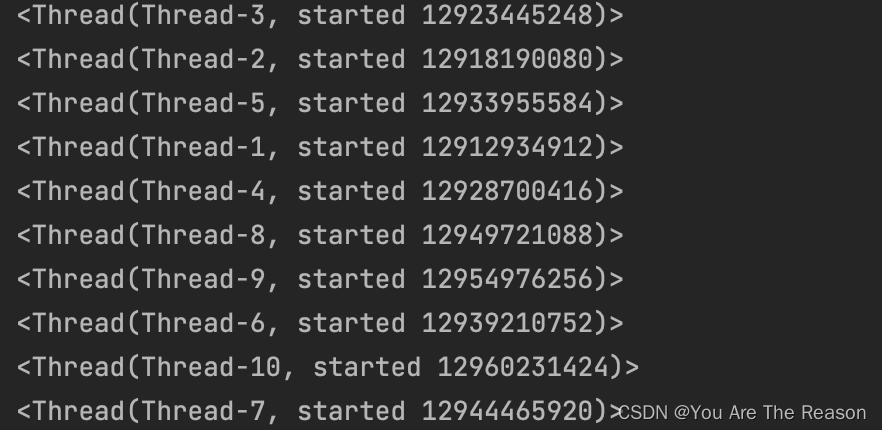
3.7 线程间共享全局变量
多个线程都是在同一个进程中,多个线程使用的资源都是同一个进程中的资源,因此多线程间是共享全局变量的。
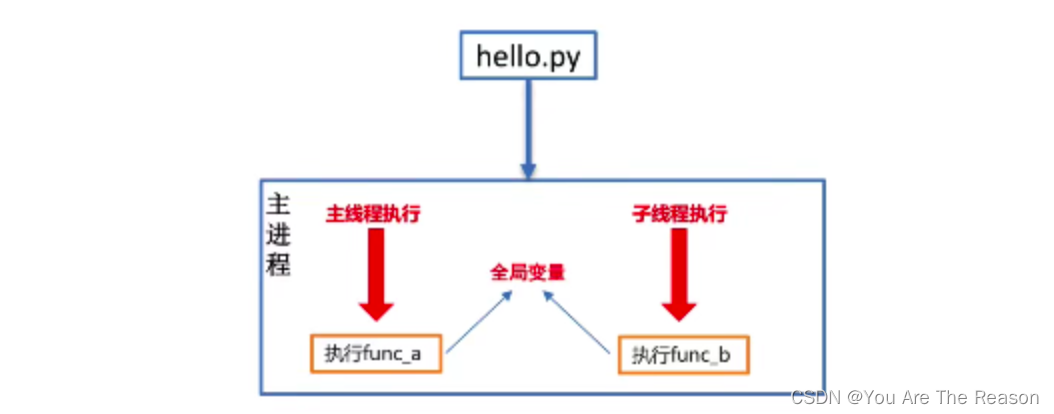
代码:
import threading
import time
#全局变量
my_list = []
#写入数据
def write_data():
for i in range(3):
my_list.append(i)
print("add:",i)
print("write_data:",my_list)
#读取数据
def read_data():
print("read_data:",my_list)
if __name__ == '__main__':
#创建写入数据子线程
write_thread = threading.Thread(target=write_data)
#创建读取数据子线程
read_thread = threading.Thread(target=read_data)
#启动线程执行相应任务
write_thread.start()
time.sleep(0.2)
read_thread.start()
执行结果:
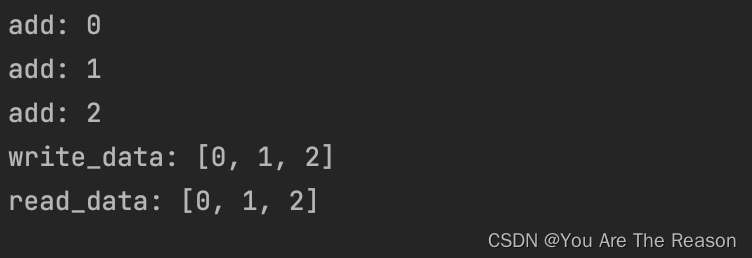
3.8 多线程之间使用全局变量容易出错
多线程同时操作全局变量可能会导致数据出现错误问题,可以使用线程同步方式来解决这个问题(互斥锁)。
代码:
import threading
g_num = 0
def sum1():
for i in range(10000000):
global g_num
g_num += 1
print('g_num1',g_num)
def sum2():
for i in range(10000000):
global g_num
g_num += 1
print('g_num2',g_num)
if __name__ == '__main__':
sub_thread1 = threading.Thread(target=sum1)
sub_thread2 = threading.Thread(target=sum2)
sub_thread1.start()
sub_thread2.start()
执行结果:
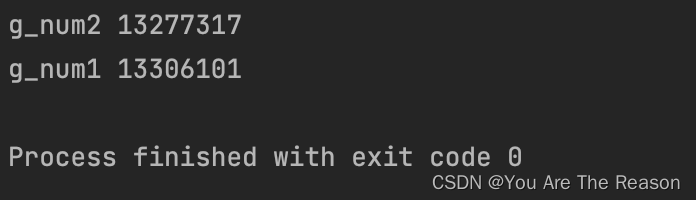
因为当两个或多个线程同时访问和修改同一个全局变量,就可能出现一个线程的修改结果被另一个线程覆盖的情况,这种情况被称为竞态条件。比如,如果两个线程同时对一个全局变量执行加1操作,理论上变量应该增加2,但实际上可能只增加了1。
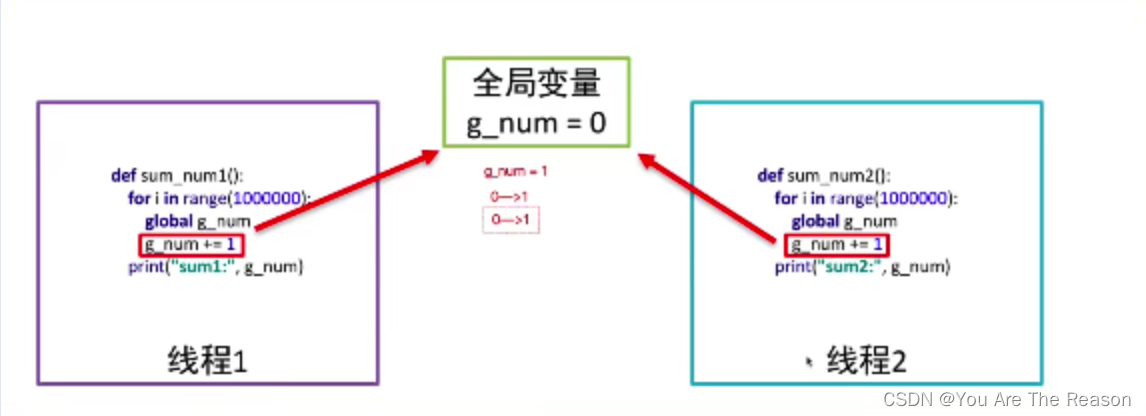
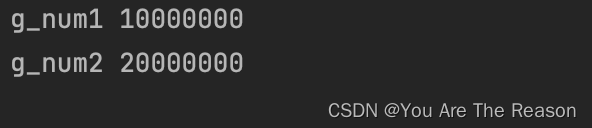
3.9 线程同步方式
互斥锁:对共享数据进行锁定,保证同一时刻只要一个线程去操作。
知识点:
- 互斥锁的创建
mutex = threading.Lock() - 上锁
mutex.acquire() - 解锁
mutex.release()
代码:
import threading
g_num = 0
def sum1():
#上锁
mutex.acquire()
for i in range(10000000):
global g_num
g_num += 1
#解锁
mutex.release()
print('g_num1',g_num)
def sum2():
# 上锁
mutex.acquire()
for i in range(10000000):
global g_num
g_num += 1
# 解锁
mutex.release()
print('g_num2',g_num)
if __name__ == '__main__':
#创建锁
mutex = threading.Lock()
#创建子线程
sub_thread1 = threading.Thread(target=sum1)
sub_thread2 = threading.Thread(target=sum2)
sub_thread1.start()
sub_thread2.start()
执行结果:
四、 进程和线程的对比
-
关系对比
- 线程是依附在进程里面的,没有进程就没有线程
- 一个进程默认提供一条线程,进程可以创建多个线程

-
区别对比
- 进程之间不共享全局变量
- 线程之间共享全局变量,但是要注意资源竞争问题,解决办法:互斥锁或线程同步
- 创建进程的资源开销要比创建线程的资源开销大
- 进程是操作系统资源分配的基本单位,线程是CPU调度的基本单位
- 线程不能独立执行,必须依存在进程中
-
优缺点对比
- 进程优缺点
- 优点:可以用多核
- 缺点:开销大
- 进程优缺点
- 优点:资源开销小
- 缺点:不能使用多核
- 进程优缺点

















 681
681

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









