








数据集链接:Titanic - Machine Learning from Disaster | Kaggle
Step1:导入函数库
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.ensemble import RandomForestRegressor
from sklearn import metrics
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 忽略警告
import warnings
warnings.filterwarnings("ignore")
#显示中文
plt.rcParams['font.sans-serif']=['SimHei'] #显示中文标签
plt.rcParams['axes.unicode_minus']=False #这两行需要手动设置Step2:导入数据并查看
data_train = pd.read_csv('D:/jupyter-notebook/kaggle/Titanic/train.csv')
#训练集
data_train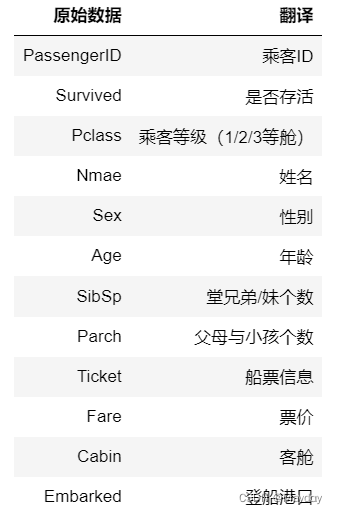
# 查看训练集大致情况,发现Age、Cabin、Embarked有缺失值
data_train.info()
# 查看训练集缺失值情况
data_train.isnull().sum()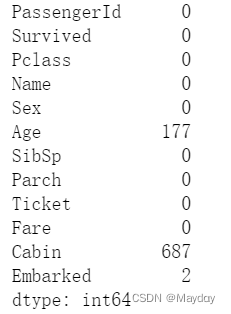
# 查看有无极端值以及数值分布情况
data_train.describe()
获救比例为38.38%,高等客舱获救的人更多,年龄小的获救更多
Step3:初步画图分析关系
1、查看survived和性别(Sex)的关系:获救的女性更多
# 有多少比例的男、女性获救
men_sur = data_train.loc[data_train.Sex == 'male']['Survived']
men_rate = men_sur.sum() / men_sur.count()
women_sur = data_train.loc[data_train.Sex == 'female']['Survived']
women_rate = women_sur.sum()/women_sur.count()
print('男性获救的比例:%.2f' % men_rate) #结果为0.19
print('女性获救的比例:%.2f' % women_rate) #结果为0.74
# 获救的男女之比
sur_sum = sum(data_train['Survived'] == 1)
print('总获救人数:%.d' % sur_sum) #结果为342
men_women_rate = men_sur.sum() / women_sur.sum()
print('获救的男女比例:%.2f' % men_women_rate) #结果为0.47# 各性别获救情况
plt.figure()
survived_m = data_train.loc[data_train.Sex == 'male']['Survived'].value_counts()
survived_w = women_sur = data_train.loc[data_train.Sex == 'female']['Survived'].value_counts()
df = pd.DataFrame({'男性':survived_m,'女性':survived_w})
df.plot(kind='bar',stacked=True)
plt.title('按性别看获救情况')
plt.xticks(rotation=0)
plt.xlabel('获救情况(获救=1,未获救=0)')
plt.ylabel('人数')
plt.show()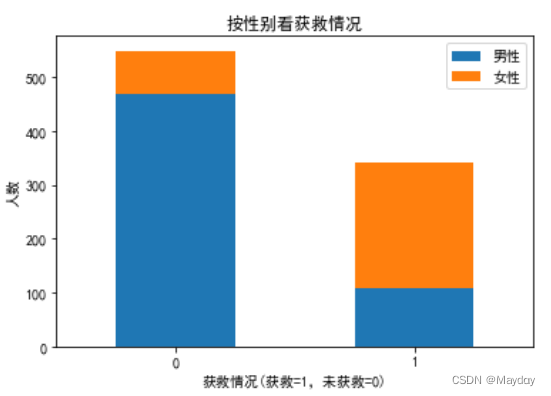
2、查看survived和客舱等级(Pclass)的关系
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









