






今天用一个pandas处理数据时,有一个任务要求是处理异常值,利用df.describe()函数查看数据统计量的时候发现输出的数据有的是用科学计数法带e的方式输出,显示是这样的:
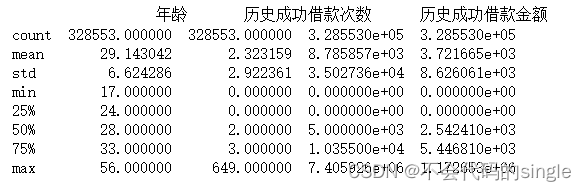
之前做的案例里面没有出现过这样的情况,又结合到老师给的文档里说(包括但不限于:数据格式、数值范围等类型异常值),但是不明白是不是数据格式这种类型异常值,但是这样输出的数据看着真的不好看,于是在网上查找了一下可以用这个:
np.set_printoptions(suppress=True)
pd.set_option('display.float_format', lambda x: '%.2f' % x) 引用到代码里面后显示:
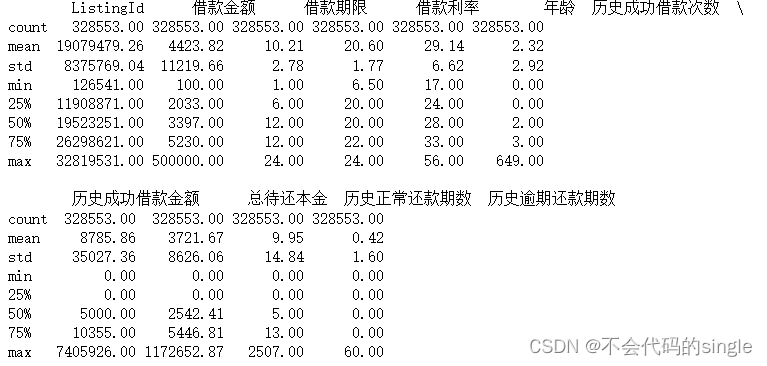 问题解决
问题解决

















 2875
2875

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









