









这门课程得主要目的是通过真实的数据,以实战的方式了解数据分析的流程和熟悉数据分析python的基本操作。知道了课程的目的之后,我们接下来我们要正式的开始数据分析的实战教学,完成kaggle上泰坦尼克的任务,实战数据分析全流程。
这里有两份资料需要大家准备:
z图书《Python for Data Analysis》第六章和 baidu.com &
google.com(善用搜索引擎)
本次学习由开源学习组织Datawhale发起
Task4、数据可视化
数据可视化
了解matplotlib
matplotlib 是一个 Python 的 2D绘图库,它以各种硬拷贝格式和跨平台的交互式环境生成出版质量级别的图形。在数据分析的数据可视化过程中,我们能用其来将我们的数据绘制成表格,并且通过不同的画图方式突出我们需要的数据呈现的特征,从而提取到我们想要的信息。
# 加载所需的库
# 如果出现 ModuleNotFoundError: No module named 'xxxx'
# 你只需要在终端/cmd下 pip install xxxx 即可
%matplotlib inline
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
【思考】最基本的可视化图案有哪些?分别适用于那些场景?(比如折线图适合可视化某个属性值随时间变化的走势)
回答:比如最常见的折线图、散点图、柱状图、条形图等,折线图适用于需要知道数据随使时间的变化的变化趋势、散点图适用于观察数据所具有的线性特征、柱状图、条形图更多集中在对数据分类后数据本身的个数,分布特征而进行使用。总而言之,在数据可视化过程中,提前确定好你要绘出的合适的图形,对于你最后想要的答案可能有着事半功倍的效果。
数据可视化实例
上图是可视化前的数据,即使我们前面对其进行了初步的处理,让数据更加可用,具有参考价值,但我们但从表格中对单个或单类数据观测依旧难以直观的分析出其背后包含的信息。数据可视化的高效性遍再次凸显,在我们对数据绘制成相应的图形时,我们通过表格、图像便可直观获取数据的特征信息。下面让我们来看看实例吧!
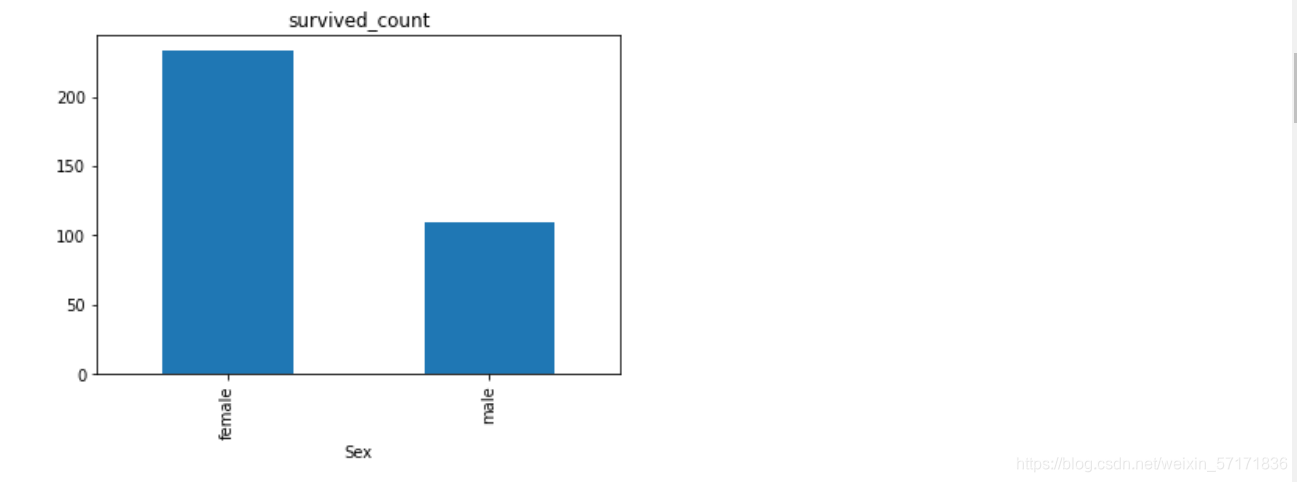
2.7.2 任务二:可视化展示泰坦尼克号数据集中男女中生存人数分布情况(用柱状图试试)。
#代码编写
sex = text.groupby('Sex')['Survived'].sum()
sex.plot.bar()
plt.title('survived_count')
plt.show()
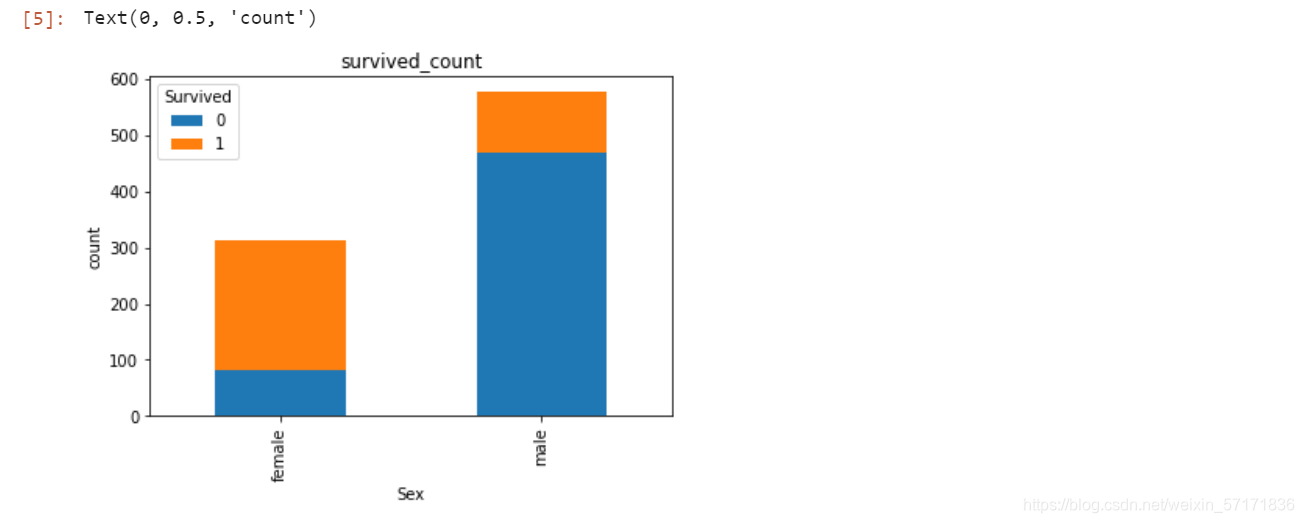
2.7.3 任务三:可视化展示泰坦尼克号数据集中男女中生存人与死亡人数的比例图(用柱状图试试)。
#代码编写
# 提示:计算男女中死亡人数 1表示生存,0表示死亡
text.groupby(['Sex','Survived'])['Survived'].count().unstack().plot(kind='bar',stacked='True')
plt.title('survived_count')
plt.ylabel('count')
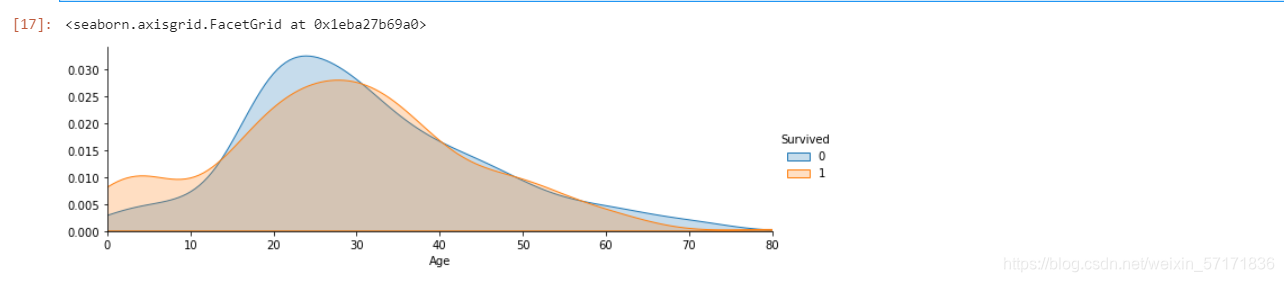
2.7.6 任务六:可视化展示泰坦尼克号数据集中不同年龄的人生存与死亡人数分布情况。(不限表达方式)
#代码编写
import seaborn as sns
facet = sns.FacetGrid(text, hue="Survived",aspect=3)
facet.map(sns.kdeplot,'Age',shade= True)
facet.set(xlim=(0, text['Age'].max()))
facet.add_legend()
先列举了学习过程中的三个任务所画出的图像,可以看到,即使是同样的柱状图,加以颜色、数据就可能表达出不同的信息,因此在你想要得到的信息中,用不同的绘图得出的信息做对比,得到最优的答案我认为是一件很重要的事情。但这是否意味着我们只需要画图就好,不必在乎数据本身的处理呢?
我想并不是这样的。我们来看下面的例子。
2.7.4 任务四:可视化展示泰坦尼克号数据集中不同票价的人生存和死亡人数分布情况。(用折线图试试)(横轴是不同票价,纵轴是存活人数)
【提示】对于这种统计性质的且用折线表示的数据,你可以考虑将数据排序或者不排序来分别表示。看看你能发现什么?
#代码编写
import seaborn as sns
facet = sns.FacetGrid(text, hue="Survived",aspect=3)
facet.map(sns.kdeplot,'Age',shade= True)
facet.set(xlim=(0, text['Age'].max()))
facet.add_legend()
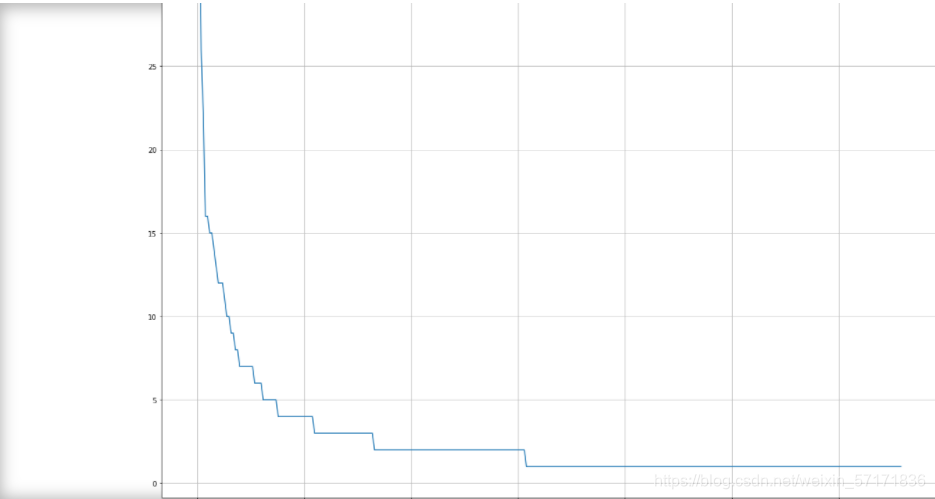
# 排序前绘折线图
fare_sur1 = text.groupby(['Fare'])['Survived'].value_counts()
fare_sur1
fig = plt.figure(figsize=(20, 18))
fare_sur1.plot(grid=True)
plt.legend()
plt.show()
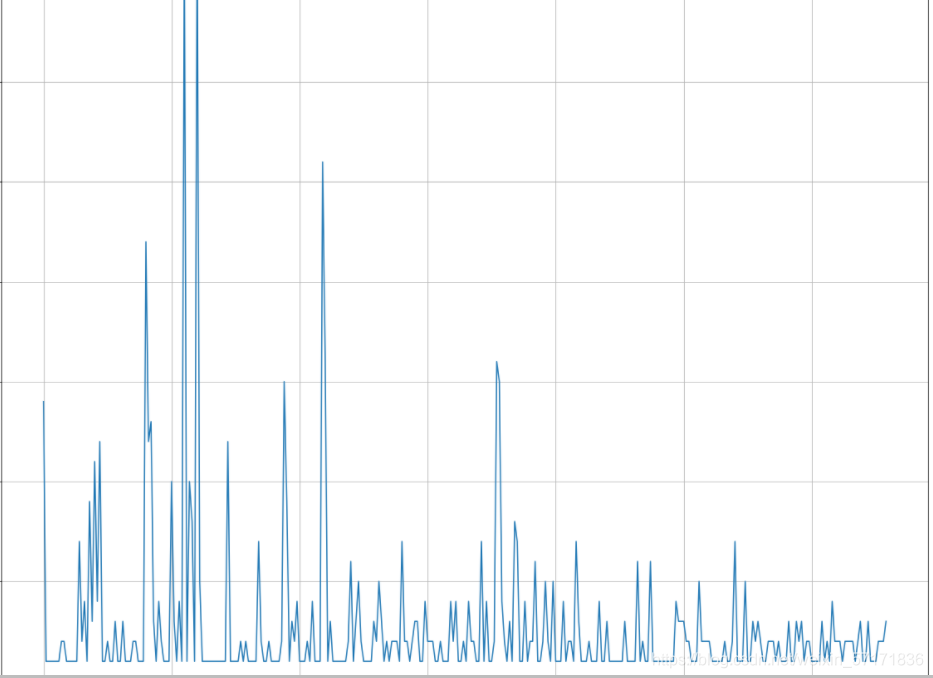
可以看到,在绘图前对数据是否进行排序,绘制出的图像完全是不同的参考意义,在实际过程中,未经排序的不同组的数据可能会有相似的值,如果直接将未排序的数据绘制成图表,将大大降低其的可读性。从而背离我们对数据可视化的目的。
小结
数据可视化的关键,在于你本身要清晰的知道你要的是什么目的的信息,将组成结构,数据类别先进行相应的处理,再进行可视化的操作。
数据可视化学下来,我认为这是再企业中身为数据处理者需要展现再其他人面前的外衣,它要足够清晰自己好看的定位,好看不一定简单,花里胡哨也并非是甲方要的艺术性。让数据呈现出我们想让它呈现的东西,或许是我认为的数据可视化的第一步吧,见我所见。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









