







MySQL使用最多的就是B+树索引,而B+树是借鉴了二分查找法、二叉查找树、平衡二叉树、还有B树的一些思想构建的,因此我们要先了解这些算法
一、二分查找法
二分查找法(Binary Search)是一种高效的查找算法,用于在有序数组或列表中查找特定元素。它的基本思想是通过不断将查找区间一分为二,逐步缩小查找范围,直到找到目标元素或确定其不存在。
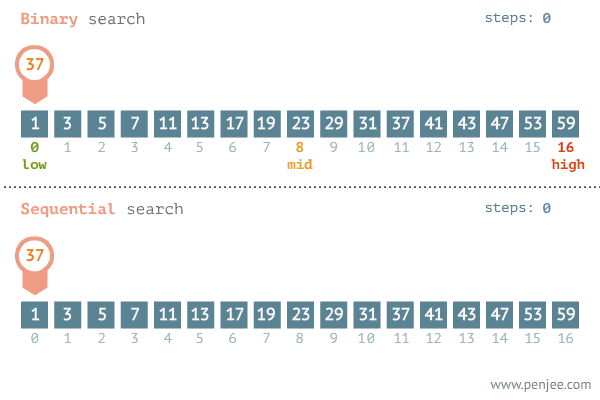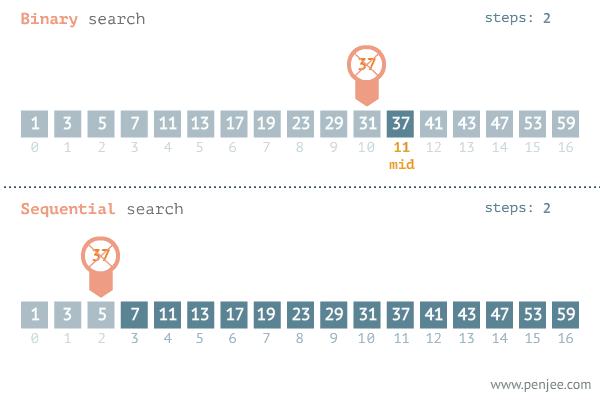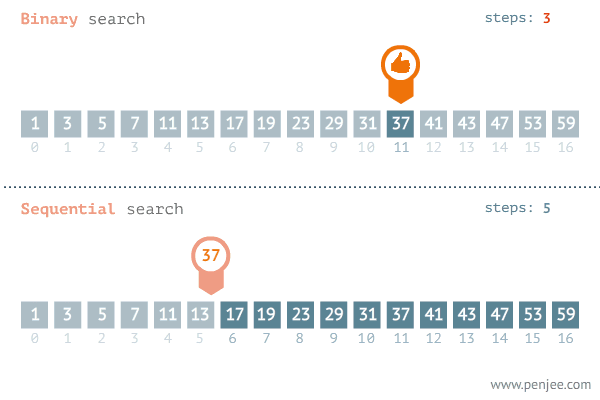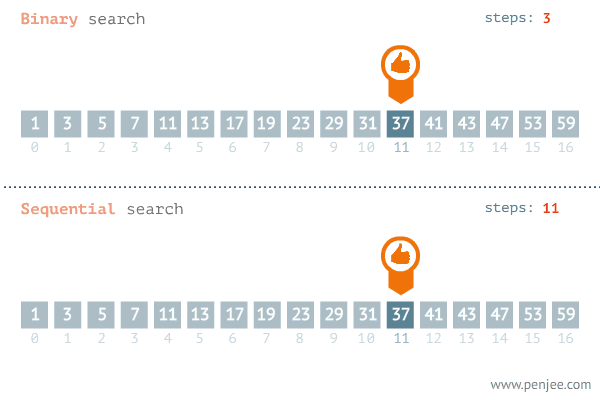
二、二叉查找树
-
查找:从根节点开始,若目标值等于根节点值,则查找成功;若小于根节点值,则继续在左子树中查找;若大于根节点值,则继续在右子树中查找。重复此过程直到找到目标值或到达空树。
- 局限性
二分搜索树在时间性能上是具有局限性的。
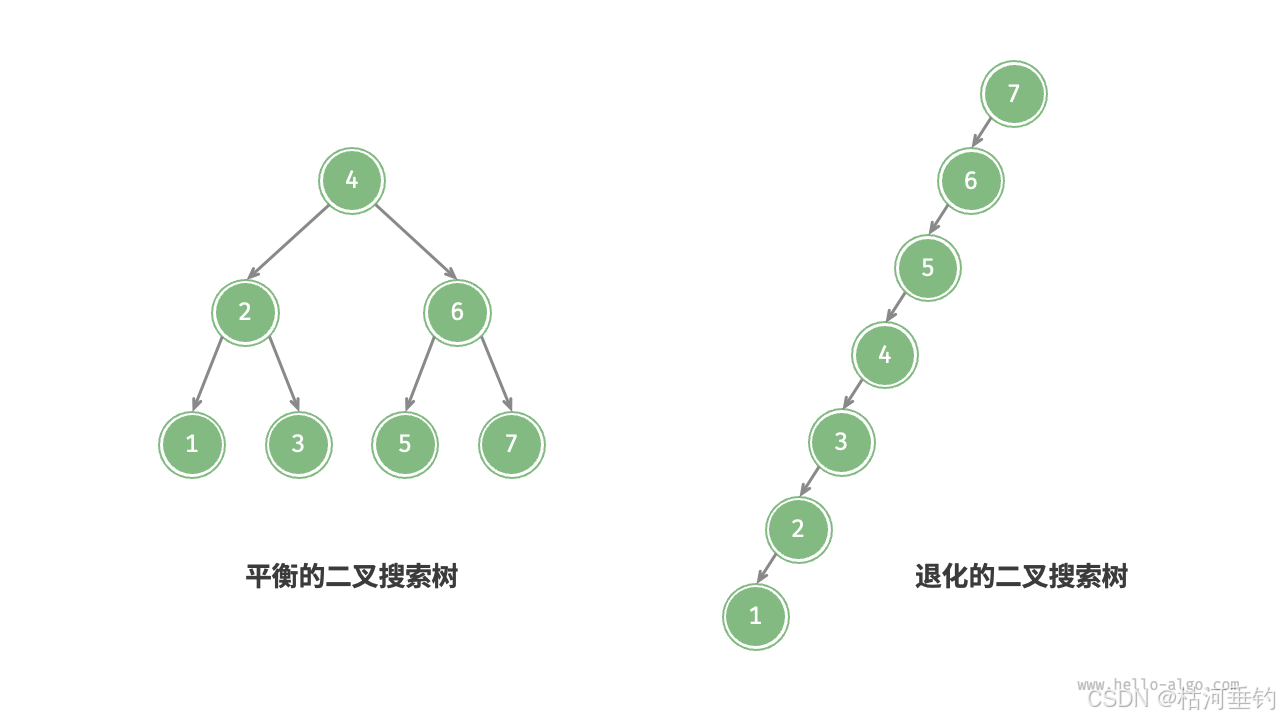
在理想情况下,二叉搜索树是“平衡”的,这样就可以在 log𝑛 轮循环内查找任意节点。
然而,如果我们在二叉搜索树中不断地插入和删除节点,可能导致二叉树退化为如图所示的链表,相应的,二叉搜索树的查找操作是和这棵树的高度相关的,而此时这颗树的高度就是这颗树的节点数 n,这时各种操作的时间复杂度也会退化为 𝑂(𝑛) 。
三、平衡二叉树
平衡二叉树(Balanced Binary Tree),又被称为AVL树(Adelson-Velsky和Landis树),是一种特殊的二叉搜索树。它通过维护树的高度平衡来确保操作的高效性。以下是平衡二叉树的一些关键点:
定义
-
平衡因子:平衡二叉树中每个节点的平衡因子定义为该节点左子树的高度减去右子树的高度。平衡因子的绝对值不超过1,即平衡因子∈{-1,0,1}。
-
高度平衡:平衡二叉树中任意一个节点的左子树和右子树的高度差的绝对值不超过1
四、B树
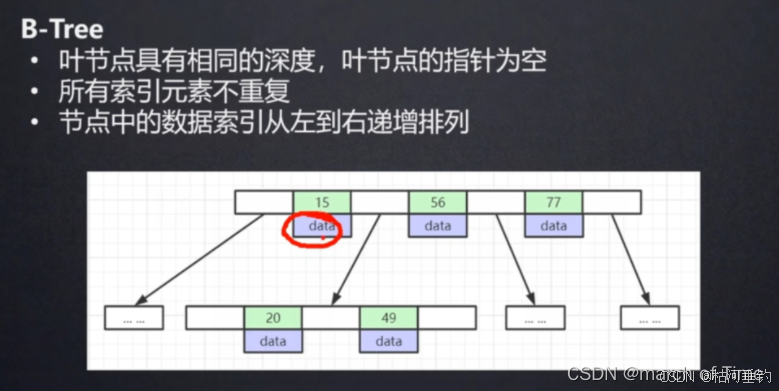
B树是一种自平衡的树数据结构,它能够保持数据有序,支持顺序访问和二分查找,同时允许快速的插入和删除操作。B树的每个节点可以有多个子节点和多个键值,这使得它在处理大量数据时非常高效,尤其适用于文件系统和数据库索引等场景。
B树的结构和特性
-
多路搜索树:每个节点可以有多个子节点,子节点的数量由树的阶数决定。例如,m阶B树的每个节点最多有m个子节点,至少有⌈m/2⌉个子节点(根节点除外)。
-
键值有序排列:节点中的键值按照从小到大的顺序排列,且每个键值将节点分割成多个区域,每个区域对应一个子节点。
-
平衡性:所有叶子节点位于同一层,且树的高度相对较低,这保证了查找、插入和删除操作的时间复杂度为O(log n)。
B树的插入和删除操作
-
插入操作:在插入一个新键值时,首先找到该键值应该插入的叶节点。如果叶节点未满(键值数量小于m-1),则直接插入并保持有序;如果叶节点已满,则需要将该节点分裂为两个节点,中间的键值上升到父节点中。
-
删除操作:删除一个键值时,需要确保节点中的键值数量不低于下限(⌈m/2⌉-1)。如果删除后节点键值数量不足,则需要从兄弟节点借键值,或者与兄弟节点合并。
五、B+树
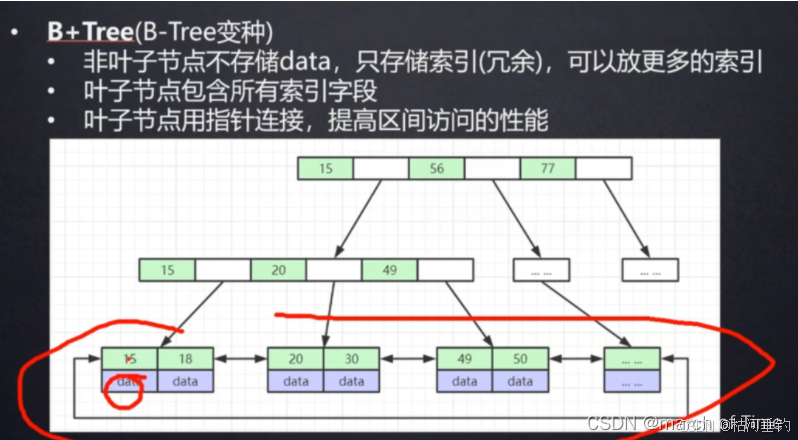
B+树是一种基于B树的变体数据结构,常用于数据库和文件系统的实现中。与B树相比,B+树具有更好的查询性能和更高的存储密度,尤其适合处理大量数据的场景。
B+树的结构和特性
-
所有数据存储在叶子节点:在B+树中,实际的数据记录只存储在叶子节点中,而非叶子节点仅存储键值作为索引,用于指导搜索过程。
-
叶子节点之间的指针:叶子节点之间通过指针相互连接,形成了一个有序的链表结构。这使得B+树能够高效地进行范围查询和顺序访问。
-
更高的存储密度:由于非叶子节点只存储键值,B+树的节点可以容纳更多的键值,从而减少了树的高度,提高了存储效率。
B+树的插入和删除操作
-
插入操作:插入一个新键值时,首先找到合适的叶子节点。如果叶子节点未满,则直接插入;如果已满,则将该节点分裂为两个节点,并将中间的键值插入到父节点中。若父节点也已满,则继续分裂,直至根节点。
-
删除操作:删除一个键值时,需要确保叶子节点中的键值数量不低于下限。如果删除后键值数量不足,则需要从兄弟节点借键值,或者与兄弟节点合并。
B+树与B树的区别
-
数据存储位置:B树将数据存储在所有节点中,而非仅仅叶子节点;B+树则将所有数据存储在叶子节点中,非叶子节点仅作为索引。
-
查询效率:B+树的叶子节点之间的指针使得范围查询更加高效;B树在范围查询时需要回溯,效率相对较低。
-
存储密度:B+树的非叶子节点存储键值更多,树的高度更小,查询效率更高
六、B+树索引的特点
1、由B+树发展而来
所以它的架构就可以理解为就是一个B+树,MySQL正是使用B+树索引。
2、高度一般在2-4层
所以查找某个数据最多只需要2-4次IO,而没索引的情况就需要逐行扫描,明显效率低很多。
3、MySQL的B+树索引并不能给到一个给定键值的行
B+树索引的工作原理是,当查找一个给定键值时,它会先找到包含该键值的页,然后将该页读入到缓冲池中。在缓冲池中,通过二分查找法在页内找到具体的行数据。
七、索引能提高效率的原因
-
减少数据扫描范围:索引能够帮助数据库快速定位符合条件的行,从而减少需要扫描的数据量。例如,在一个包含数百万行的表中,如果没有索引,查询可能需要扫描所有行;而如果有索引,查询可能只需要扫描很少的一部分行。
-
提供有序数据:索引中的数据是按照一定的顺序排列的,这使得数据库在需要对结果进行排序时,可以利用索引的有序性来快速生成排序后的结果,而无需进行额外的排序操作。
-
加速排序和分组操作:在进行排序和分组操作时,索引能够帮助数据库更高效地对数据进行排序和分组,减少操作的时间。
-
加速关联操作:在多表关联查询中,如果关联条件字段上有索引,数据库可以利用索引来快速找到匹配的行,从而加速关联操作。
-
提高唯一性约束的检查速度:对于需要唯一性约束的字段,索引可以帮助数据库快速检查数据的唯一性,确保数据的完整性。
-
支持快速的分页操作:在进行分页查询时,索引能够帮助数据库快速定位到分页的起始位置,从而提高分页操作的效率。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









