






 文章介绍了HTTP响应状态码中的常见代码,如200(成功)、404(未找到)、403(禁止访问)、405(方法不允许)、500(服务器内部错误)和302、301(重定向)。此外,还提及了HTTP响应头中的Content-Type字段,用于定义响应正文的格式,如HTML、CSS、JavaScript和JSON。最后,简要对比了HTTP的1.1、2.0和3.0版本在连接方式、安全性、传输层协议和头部压缩等方面的不同。
文章介绍了HTTP响应状态码中的常见代码,如200(成功)、404(未找到)、403(禁止访问)、405(方法不允许)、500(服务器内部错误)和302、301(重定向)。此外,还提及了HTTP响应头中的Content-Type字段,用于定义响应正文的格式,如HTML、CSS、JavaScript和JSON。最后,简要对比了HTTP的1.1、2.0和3.0版本在连接方式、安全性、传输层协议和头部压缩等方面的不同。
在前两篇文章当中,已经分别介绍了HTTP是什么,以及常见的请求头当中的属性。
【网络原理7】认识HTTP_革凡成圣211的博客-优快云博客HTTP抓包,Fiddler的使用![]() https://blog.youkuaiyun.com/weixin_56738054/article/details/129148515?spm=1001.2014.3001.5502
https://blog.youkuaiyun.com/weixin_56738054/article/details/129148515?spm=1001.2014.3001.5502
下面,继续谈一下HTTP响应头当中有哪些比较常见的属性。
目录
⑦状态码:302:Move temporarily(临时重定向)
长连接和多路复用是网络通信中的两个不同概念,它们的区别具体如下:
一、HTTP状态码(HTTP响应行当中的内容)
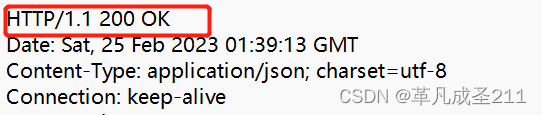
这一个状态码的含义,也在前两篇文章当中提到了。下面,介绍几个常见的状态码
①状态码:200
状态码显示200,说明浏览器很顺利地获取到想要的内容了,没有出什么bug。
②状态码:404
请求的资源不存在,这个时候就会提示404不存在。
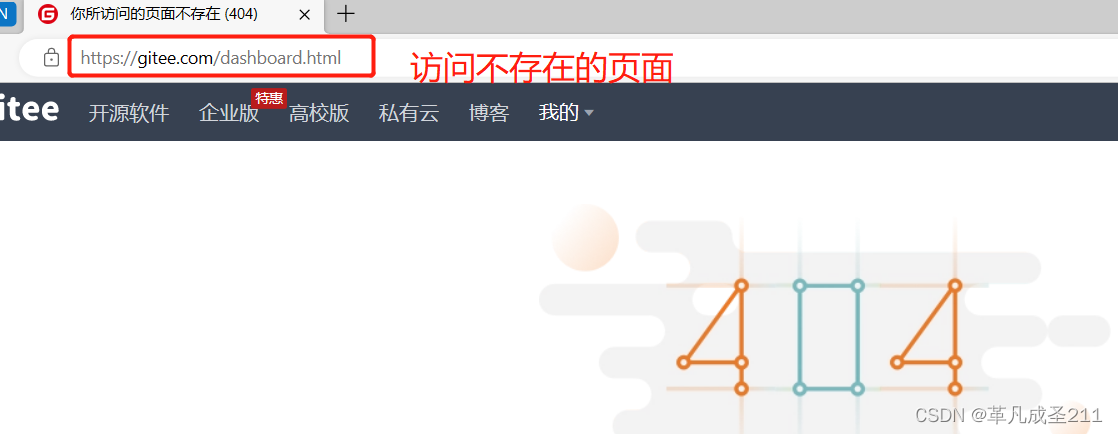
③状态码:403
403提示当前资源存在,但是由于用户的权限不够,因此不可以访问。关于怎样校验权限,目前大部分是使用spring-security来校验权限。
④状态码:405
这个状态码的含义是:Method Not Allowed,这种状态比较少遇到。
例如:当用户使用get访问服务器,但是服务器的接口只支持post。
⑤状态码:500
这个状态码的含义是服务器内部出现错误。
例如在运行的时候出现了异常(Exception),那么就会显示500,也是不那么常见的情况。
在Tomcat启动之后,如果运行过程当中出现了异常,会经历以下4个步骤:
步骤1:如果异常位于try-catch代码块当中,就会按照catch代码块的逻辑来处理;
步骤2:如果在没有catch进行处理,那么这个异常就会沿着调用栈不断向上传递。
步骤3:如果在最顶层的Servlet当中依然没有处理的了,那么这个异常就会交给Tomcat来进行处理。
步骤4:如果Tomcat也没有办法处理,这个时候就会抛出500错误代码,然后把异常交给jvm进行处理,也就引发了程序的崩溃
⑥状态码:504:Gateway Timeout
指的是服务器当前太繁忙了,来不及响应。
⑦状态码:302:Move temporarily(临时重定向)
关于请求转发和重定向的区别,会在后续的文章当中讲到。‘
其中,登录跳转就是一个常见的重定向场景。
里面有一个字段,叫做Location:

其中,这一个字段的含义就是:需要跳转的资源在哪里
Location和Refer的区别就在于:
| Location | Refer | |
| 位置 | HTTP请求头 | HTTP响应头 |
| 含义 | 当前页面从哪里跳转过来 | 这个HTTP请求需要重定向到哪个页面 |
⑧状态码:301(永久重定向)
301的状态码代表的含义是永久重定向
301,302,304状态码的区别
1. 301 Moved Permanently
-
含义:请求的资源已永久移动到新的 URL。
-
用途:用于资源永久重定向。
-
行为:
-
客户端(如浏览器)会缓存新的 URL,后续请求会直接访问新地址。
-
搜索引擎会更新索引,将权重转移到新的 URL。
-
-
示例:
-
网站更换域名时,旧域名重定向到新域名。
-
URL 结构调整,旧路径重定向到新路径。
-
-
响应头:
http
复制
HTTP/1.1 301 Moved Permanently Location: https://www.new-url.com/new-path
2. 302 Found(临时重定向)
-
含义:请求的资源临时移动到新的 URL。
-
用途:用于资源临时重定向。
-
行为:
-
客户端不会缓存新的 URL,后续请求仍会访问原地址。
-
搜索引擎不会更新索引,权重仍保留在原 URL。
-
-
示例:
-
网站维护期间,临时将用户重定向到维护页面。
-
A/B 测试时,临时将用户重定向到不同版本的页面。
-
-
响应头:
http
复制
HTTP/1.1 302 Found Location: https://www.temporary-url.com/temporary-path
3. 304 Not Modified
-
含义:请求的资源未修改,客户端可以使用缓存的版本。
-
用途:用于缓存优化,减少不必要的资源传输。
-
行为:
-
服务器在响应中不返回资源内容,客户端直接使用本地缓存。
-
通常与请求头
If-Modified-Since或If-None-Match配合使用。
-
-
示例:
-
客户端请求一个静态资源(如图片、CSS 文件),服务器检查后发现资源未修改,返回
304。
-
-
响应头:
http
复制
HTTP/1.1 304 Not Modified
对比总结
| 状态码 | 含义 | 类型 | 缓存行为 | 搜索引擎行为 | 典型场景 |
|---|---|---|---|---|---|
| 301 | 永久重定向 | 重定向 | 客户端缓存新 URL | 更新索引,转移权重 | 域名更换、URL 永久调整 |
| 302 | 临时重定向 | 重定向 | 客户端不缓存新 URL | 不更新索引 | 临时维护、A/B 测试 |
| 304 | 资源未修改 | 缓存优化 | 客户端使用本地缓存 | 无影响 | 静态资源缓存优化 |
服务器的状态码有很多,总结一下:它们大致都有一下特点:
| 状态码 | 含义 |
| 2开头 | 表示响应成功 |
| 3开头 | 重定向 |
| 4开头 | 客户端出错(请求出错) |
| 5开头 | 服务器内部出错 |
其中,1和6开头的状态码,都比较少见。
二、HTTP响应"报头"(header)
HTTP响应是由HTTP响应行,HTTP响应头,还有响应的正文一共3部分组成的。
前面我们也提到了:HTTP的响应头是由多组键值对组成的。下面,将来聊一下一个常见的键值对:Content-Type,它描述的是响应的body的格式,有以下几种常见的格式:
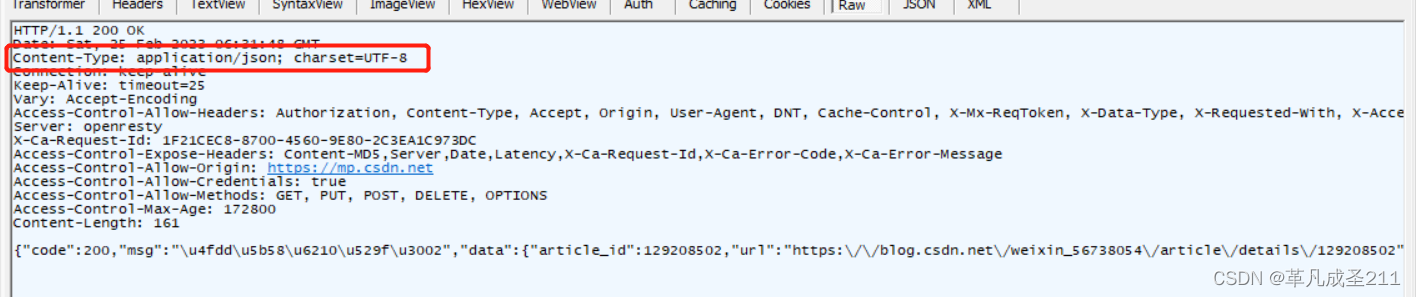
1) text/html:返回的是一个html页面
2) text/css:返回的是一个css页面
3) application/javascript:返回的是一个javascript页面
4)application/json:返回的是一串json格式的字符串
三、HTTP的1.1/2.0/3.0三个版本的对比
| HTTP版本 | 连接方式 | 安全性 | 传输层协议 | 头部是否压缩 | 传输格 式 | 是否支持多路复用 | |
| HTTP1.0 | 短连接:一个连接对应一个请求 | 明文传输 | TCP | 否 | 纯文本 | 否 | |
| HTTP1.1 | 长连接:一个连接可以被同一个客户端多次请求复用; 支持管道传输:客户端可以发起多个请求,只要第一个 请求发出去了,不必等其回来,就可以发送第二次请求。 | 明文传输 | TCP | 否 | 纯文本 | 否 | |
| HTTP2.0 | 密文传输(基于HTTPS) | TCP | 是 如果你同时发出多个请求,他们的头是一样的或是相似的 (在客户端和服务器同时维护一张头信息表,所有字段都会存入这个表,生成一个索引号,以后就不发送同样字段了,只发送索引号,这样就提高速度了。) | 二进制 | 是: 使用一个进程/线程同时管理多个socket。会根据request的id号来完成请求的分发 | ||
| HTTP3.0 | UDP |
长连接和多路复用是网络通信中的两个不同概念,它们的区别具体如下:
连接特性
长连接:指在一次连接建立后,客户端和服务器之间可以进行多次数据交互,连接不会立即断开,而是保持一段时间,以便后续的数据传输,如HTTP长连接,在完成一次请求响应后,连接依然保持,可继续处理后续请求。
多路复用:是在一个连接上同时传输多个数据流,多个请求和响应可以交织在一起,通过特定的标识来区分不同的数据流,如HTTP/2中的多路复用,能在一个TCP连接中同时传输多个HTTP请求和响应。
目的与优势
长连接:主要目的是减少连接建立和断开的开销,提高效率。对于频繁交互的客户端和服务器,可避免每次请求都重新建立连接的时延和资源消耗,提升性能和响应速度。
多路复用:旨在更高效地利用网络带宽,提高连接的并发性。多个数据流能共享一个连接,避免了多个连接竞争带宽的问题,可同时传输多个数据,降低延迟,提高整体传输效率。
数据传输方式
长连接:数据传输是顺序的,在同一连接上,一个请求完成后才进行下一个请求,虽然减少了连接建立开销,但同一时刻只能处理一个请求。
多路复用:数据传输是并行的,多个数据流可同时在一个连接上传输,请求和响应能交错进行,不用按顺序等待,提高了传输效率和并发性。
应用场景
长连接:适用于需要频繁进行数据交互,但对实时性和并发性要求不是极高的场景,如即时通讯应用中的心跳包机制,保持连接不断,定时发送数据。
多路复用:适合对并发性和实时性要求高、需同时传输大量数据的场景,如现代网页加载,包含多个资源(图片、脚本、样式表等),多路复用能同时请求和传输这些资源,加快网页加载速度。
select,poll,epoll的区别是什么
select
-
工作原理:
-
使用一个位图(
fd_set)来表示需要监控的文件描述符集合。 -
调用
select时,内核会遍历所有描述符,检查是否有事件发生。 -
返回时,
select会修改fd_set,标记哪些描述符已就绪。
-
-
特点:
-
文件描述符数量有限(通常为 1024)。
-
每次调用都需要重新设置
fd_set。 -
效率随监控的描述符数量增加而下降。
-
-
优点:
-
跨平台支持,几乎所有操作系统都支持。
-
-
缺点:
-
文件描述符数量受限。
-
每次调用都需要遍历所有描述符,效率低。
-
需要维护额外的数据结构来管理描述符。
-
2. poll
-
工作原理:
-
使用一个
pollfd结构数组来表示需要监控的文件描述符集合。 -
调用
poll时,内核会遍历所有描述符,检查是否有事件发生。 -
返回时,
poll会修改pollfd结构中的revents字段,标记哪些描述符已就绪。
-
-
特点:
-
文件描述符数量不受限(仅受系统资源限制)。
-
每次调用都需要遍历所有描述符。
-
效率随监控的描述符数量增加而下降。
-
-
优点:
-
文件描述符数量不受限。
-
比
select更灵活。
-
-
缺点:
-
每次调用都需要遍历所有描述符,效率低。
-
需要维护额外的数据结构来管理描述符。
-
3. epoll
-
工作原理:
-
使用一个内核事件表来管理需要监控的文件描述符集合。
-
调用
epoll_ctl来添加、修改或删除描述符。 -
调用
epoll_wait时,内核只会返回已就绪的描述符,而不需要遍历所有描述符。
-
-
特点:
-
文件描述符数量不受限(仅受系统资源限制)。
-
使用事件驱动机制,只关注活跃的描述符。
-
效率高,适合高并发场景。
-
-
优点:
-
文件描述符数量不受限。
-
只返回已就绪的描述符,效率高。
-
适合高并发场景,性能优于
select和poll。
-
-
缺点:
-
仅适用于 Linux 系统。
-
需要更多的系统调用(
epoll_create、epoll_ctl、epoll_wait)。
-
总结:
| 特性 | select | poll | epoll |
|---|---|---|---|
| 文件描述符数量 | 有限(通常 1024) | 不受限 | 不受限 |
| 效率 | 随描述符数量增加而下降 | 随描述符数量增加而下降 | 高效,只关注活跃描述符 |
| 跨平台支持 | 几乎所有操作系统 | 几乎所有操作系统 | 仅 Linux |
| 使用复杂度 | 简单 | 较简单 | 较复杂 |
| 适用场景 | 低并发、跨平台 | 低并发、跨平台 | 高并发、Linux 系统 |


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









