







 本文通过MetaSpore平台逐步构建一个电影推荐系统,涵盖环境安装、数据处理、召回算法、排序算法及在线系统搭建。MetaSpore提供一站式机器学习开发,支持离线训练和在线推理,包含深度学习训练框架、高性能在线服务等功能。文章以MovieLens-1M数据集为例,详细讲解推荐系统的关键步骤,包括数据预处理、正负样本生成、CTR模型、双塔模型和LightGBM模型的实现,并介绍在线系统与实验框架,帮助读者理解推荐系统架构并快速实践。
本文通过MetaSpore平台逐步构建一个电影推荐系统,涵盖环境安装、数据处理、召回算法、排序算法及在线系统搭建。MetaSpore提供一站式机器学习开发,支持离线训练和在线推理,包含深度学习训练框架、高性能在线服务等功能。文章以MovieLens-1M数据集为例,详细讲解推荐系统的关键步骤,包括数据预处理、正负样本生成、CTR模型、双塔模型和LightGBM模型的实现,并介绍在线系统与实验框架,帮助读者理解推荐系统架构并快速实践。
首先,附上Github链接
LakeSoul:https://github.com/meta-soul/LakeSoul
导读
推荐系统是当前互联网产品中非常重要的组成部分。对于互联网平台来说,一个好的推荐场景不但可以快速提升点击率、互动率等短期业务指标,同时对于DAU、用户满意度、回访率等偏长期用户指标及用户体验都有好的助益。那么,你是否也想DIY一个类似的信息流推荐系统呢?
这篇文章会帮助读者基于MetaSpore平台一步一步构建一个属于自己的电影推荐系统,同时,整个系统具有很强的扩展性。我们实现了近年来在工业界经典的排序算法和召回算法,并且软件接口设计统一,无论在线还是离线相关算法只需要少量代码和配置修改就可以应用到实际的业务中。
关于MetaSpore
MetaSpore是由数元灵出品的开源一站式机器学习开发平台,提供从数据预处理、模型训练、离线实验、在线推理、在线应用框架的全流程框架和开发接口。我们希望用户可以在MetaSpore的通用组件的基础上,通过低代码的方式就可以快速创建集分布式机器学习训练、高性能模型推理、高可用AB实验框架等能力于一身的工业级AI系统。
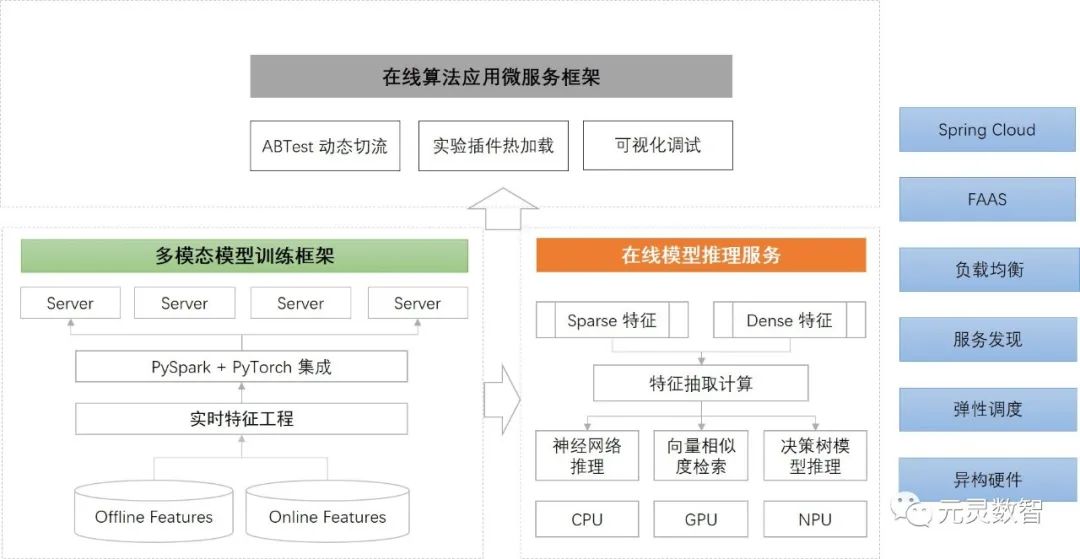
MetaSpore 具有如下几个特点:
-
一站式端到端开发,从离线模型训练到在线预测和分桶实验调试,全链路统一的开发体验;
-
完善的深度学习训练框架,兼容 PyTorch 用户生态,支持分布式大规模稀疏特征学习
-
训练框架与 PySpark 打通,无缝读取数据湖和数仓上的训练数据;
-
高性能在线推理服务,支持神经网络、决策树、Spark ML、SKLearn 等多种模型;支持异构计算推理加速;
-
在离线统一特征抽取框架,自动生成线上特征读取逻辑,统一特征抽取逻辑;
-
在线算法应用框架,提供模型预测、实验分桶切流、参数动态热加载和可视化的 Debug 功能;
-
丰富的行业算法示例和端到端完整链路解决方案。
同时,MetaSpore也是遵守Apache License 2.0的开源项目,我们在GitHub 项目中提供了标准案例与代码教程,项目的新功能和使用文档也正在持续丰富中。
1.典型推荐系统架构
一般来说,典型推荐系统会包括在线和离线两部分,如下图所示:
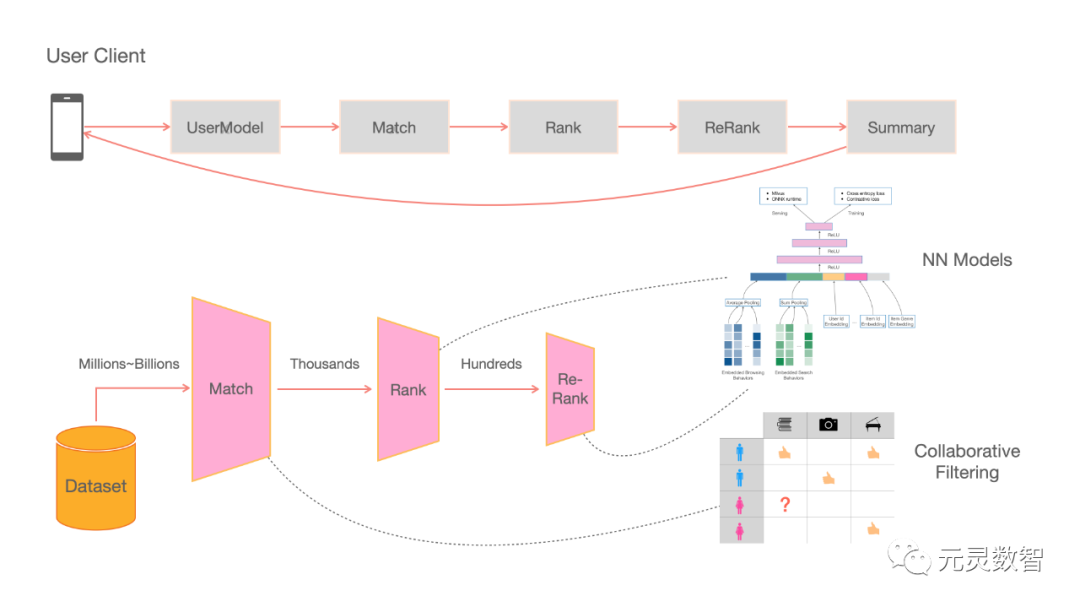
图中上半部分为系统的在线部分,包括用户建模、召回、排序、重排、取摘要等几个部分。这个部分一般使用Java、C++或者Python系统开发,好的系统设计能让算法服务高效且易扩展。当用户从手机端APP发起请求后,服务会经历这些部分的处理,最终给出展示的结果。
图中下半部分为系统的离线部分,一般来说这个部分主要是系统不同阶段的排序模型,比如:在召回阶段可能是用协同过滤或者基于图论的方法,甚至是基于神经网络的方法,做用户与物料之间或者候选物料之间中的相似度的计算与排序;而在排序、重排阶段,则一般是通过复杂机器学习模型方法(如超大规模在线学习的深度模型)建模最终业务指标并进行排序。大量日常优化工作会集中在离线的模型迭代上。
接下来的内容,我们会以MovieLens-1M数据集作为案例,围绕着:MetaSpore环境安装、数据处理与样本生成、召回算法、排序算法、在线系统与实验框架等5个部分来向读者展开一个工业级推荐系统的搭建过程。一些重点的部分我们会有代码和图示,并且会在文章的最后附带我们在github代码链接。
那么我们一起开始探索推荐系统之旅吧!
2.MetaSpore环境安装
首先,可以到我们的代码仓库:MetaSpore项目(https://github.com/meta-soul/MetaSpore)中找到离线训练环境安装说明并安装和配置好模型训练和服务的基础环境。
其次,在这个Demo的项目里,我们使用MoiveLens-1M这个数据集来演示。这份数据集在推荐领域非常著名,可以从给出的官网链接(https://grouplens.org/datasets/movielens/1m/)中下载,并存储在您的云端/本地存储上。
最后,在MovieLens Demo项目offline目录中找到离线训练模型的使用说明,并训练好模型。最后需要在MovieLens Demo项目online目录中找到在线Java环境的安装说明,并运行相应的配置脚本。后面我们将在这一章的基础上一步一步搭建我们的系统,在您移步到其他章节之前,请您确保以上的环境已经在您的服务器上已经配置完成。
3.数据处理与样本生成
一般来说数据方面的工作,包括:日志清洗、样本处理、特征挖掘、实验效果追踪与分析等方面的工作,可能会占一个典型应用算法工程师70%的时间,甚至更多。而一个算法项目最终是否能取得线上业务指标的收益,数据方面的工作至关重要。我们这里是个Demo的原型系统,数据分析部分我们会针对MovieLens 1M的数据集做简要的分析,而特征方面的工作,由于和模型更紧密,我们会和对应的模型来一起说明,这里主要说明一下数据基础操作和样本生成的过程。
3.1数据分析
针对MovieLens 1M的数据,这个数据集中一共包含了6040个用户对3883部电影进行评价。我们在这里简要的做下数据分析:
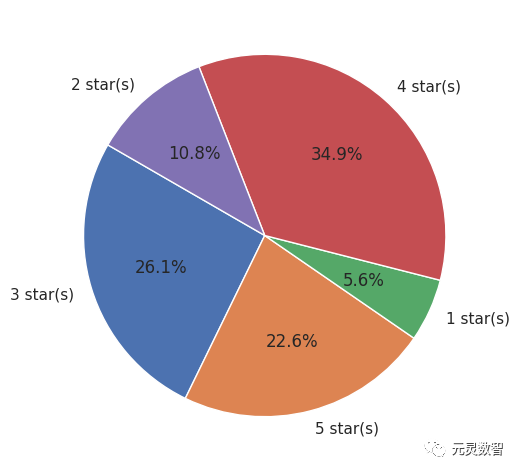
首先,分析一下电影的评分的分布情况,通过下面的饼图可以看到,相对来说,用户其实是更倾向于给电影打高分的(评分>3),原因可能是用户更可能给自己喜欢电影进行点评;
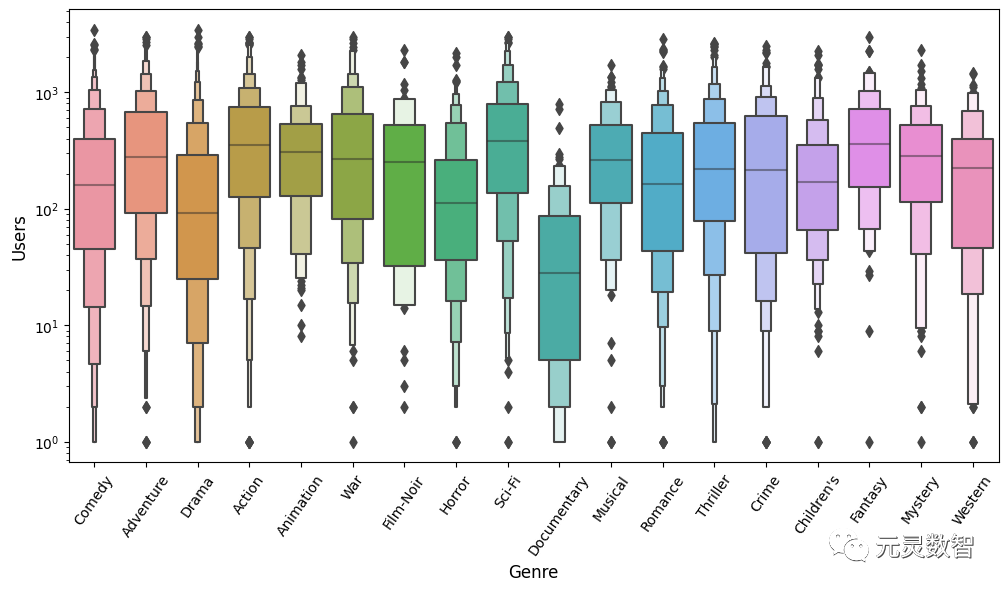
其次,我们可以使用增强箱图来分析一下不同类型电影的流行度分布,横轴是电影的类型,纵轴是评价电影的用户数量;
最后,我们可以看一下用户观看电影的数量分布,可以发现大部分用评价的电影数量在100以内,但是也有不少用户评价电影的数量在100-200之间,整体来看用户行为并不是非常稀疏。
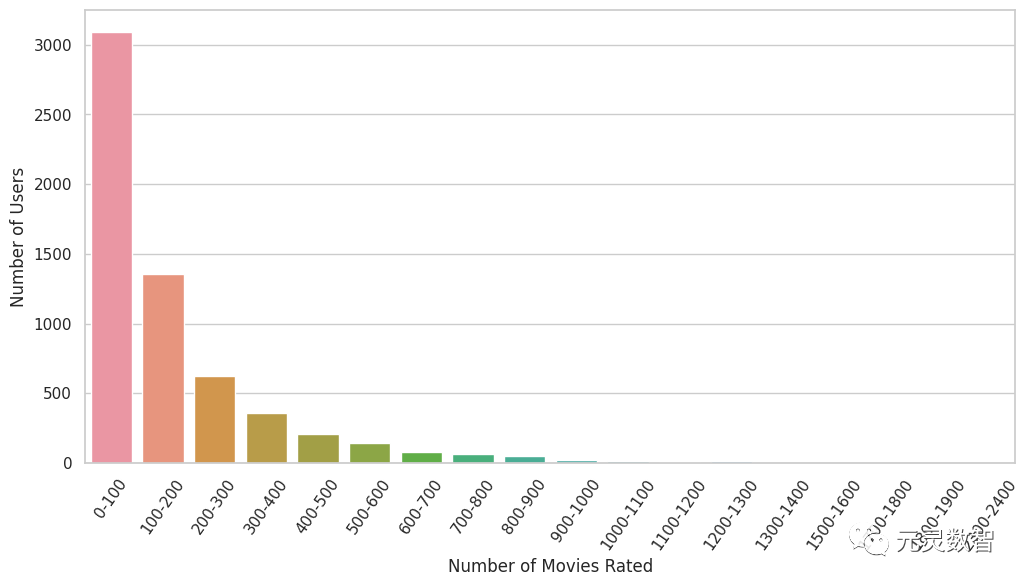
当然,真实场景中的数据分析要比上述示范的要复杂很多,并且每次迭代实验,还有不少实验结果归因的工作,这里就不一一展开了。
3.2数据集划分
对于一个机器学习系统来说,数据集划分是一个系统在设计最开始就要解决的问题,不同的划分方式,可能最终会带来不同的结果。一般来说,我们会有训练集/验证集/测试集的划分,对于线上的推荐系统而言,我们通常采用时间的划分方式,比如抽取前[-N, -2]天作为训练集,最后1天的数据随机抽取出测试集和验证集。
由于我们这里采用的是一个中等规模的电影数据集,数据量并不大,为了处理方便,针对召回、排序的过程并没有特殊的trick,我们这里采用Next-Item的方式:即对一个用户而言,前[-N, -2]个交互序列作为训练集,最后一个交互的电影数据作为测试集:
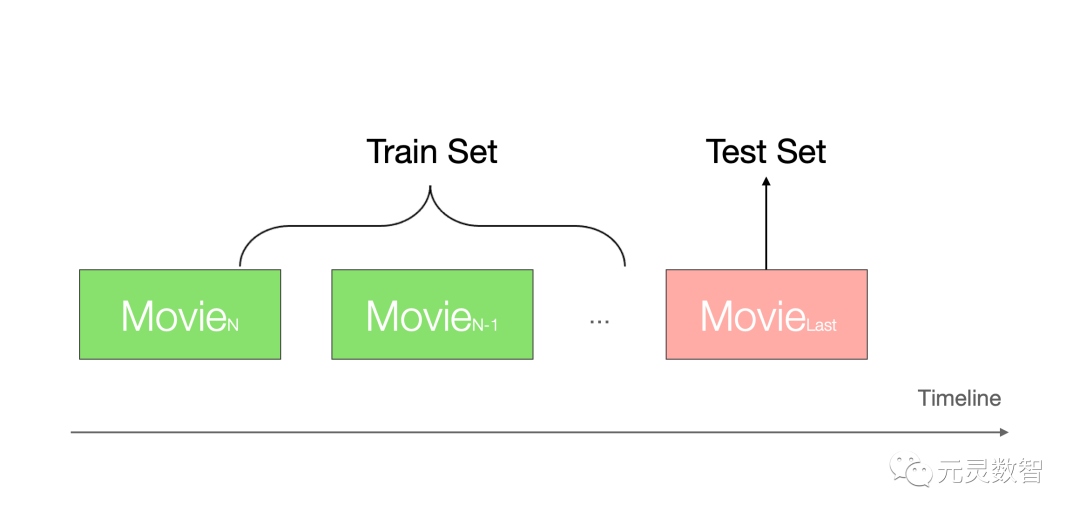
需要强调的是,样本划分的方式需要根据自己的业务和数据情况来确定,比如同样是对MovieLens-1M数据集进行划分,有的工作采用的随机划分,那么最终模型评估结果可能会有差异。
3.3正负样本划分
在我们进行模型训练之前,需要对数据样本进行划分,这里针对不同类型的模型,我们采用不同的划分方式。
3.3.1CTR模型
我们知道MovieLens数据只有用户评分,并没有典型的推荐场景那种(样本, 曝光,点击)这样的用户反馈数据。在这里,我们参考[1]中,对数据集进行划分的方式:
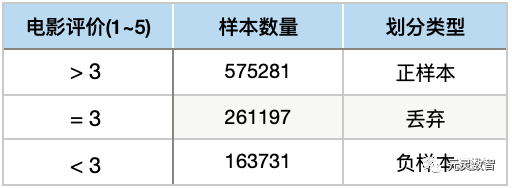
经过以上的数据划分,我们就可以对CTR模型的正负样本进行划分。以上处理方式较为简单,训练出的模型相对于真实场景来说预测较为容易,因为一般观看电影其实已经是用户对电影比较感兴趣了。
3.3.2双塔模型的样本生成
针对于双塔模型,参考YouTube[2],我们需要对样本进行负采样。对样本进行负采样的过程也非常tricky,比如近些年G家的文章在Youtube[3]和Google Play[4]上一直在迭代负采样的策略,重点是解决Batch内负采样的过程,这对于超大规模数据集或者在线学习的方式是很重要的。
由于MovieLens-1M的数据集较小,我们这里采用较为简单的全局负采样的方法。因而我们的采样过程如下:用户观看过的电影作为正样本,用户未观看过的电影作为负样本做全局采样,全局负采样的的采样概率使用的经验公式为
其中是电影
在样本集合中出现的概率。有了采样概率,我们就可以使用PySpark的RDD编程API,通过Map-Reduce的方式来操作采样过程negative_sampling():
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1175
1175

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









