






 MySQL的存储引擎包括MyISAM和InnoDB,它们在事务处理、锁定机制、性能等方面存在显著差异。MyISAM不支持事务,访问速度快,适合读取密集型业务,而InnoDB支持事务,采用行级锁定,适合写入频繁和需要事务一致性的场景。了解这些特性有助于选择合适的存储引擎以优化数据库性能。
MySQL的存储引擎包括MyISAM和InnoDB,它们在事务处理、锁定机制、性能等方面存在显著差异。MyISAM不支持事务,访问速度快,适合读取密集型业务,而InnoDB支持事务,采用行级锁定,适合写入频繁和需要事务一致性的场景。了解这些特性有助于选择合适的存储引擎以优化数据库性能。
1、概念
1、MySQL中的数据用各种不同的技术存储在文件中,每一种技术都使用不同的存储机制、索引技巧、锁定水平并最终提供不同的功能和能力,这些不同的技术以及配套的功能在 MySQL中称为存储引擎
2、存储引擎就是 MySQL将数据存储在文件系统中的存储方式或者存储格式
3、目前 MySQL常用的两种存储引擎
MyISAM
InnoDB
(innodb支持事务,myisam不支持事务)
4、MySQL存储引擎是 MySQL数据库服务器中的组件,负责为数据库执行实际的数据I/O操作
使用特殊存储引擎的主要优点之一在于:
仅需提供特殊应用所需的特性
数据库中的系统开销较小
具有更有效和更高的数据库性能
5、MySQL系统中,存储引擎处于文件系统之上,在数据保存到数据文件之前会传输到存储引擎,之后按照各个存储引擎的存储格式进行存储
2、Myisam
1)、特点:
1、myisam不支持事务,也不支持外键
2、访问速度快
3、对事物完整性没有要求
4、myisam在磁盘上存储成三个文件
.frm文件存储表定义
数据文件的扩展名为.MYD(MYData)
索引文件的扩展名是.MYI(MYIndex)
5、表级锁定形式,数据在更新时锁定整个表(不允许两个人同时操作)
6、数据库在读写过程中相互阻塞
会在数据写入的过程阻塞用户数据的读取,也会在数据读取的过程中阻塞用户的数据写入
7、数据单独写入或读取,速度过程较快且占用资源相对少
(1)静态表:静态表是默认的存储格式
(2)动态表 :态表包含可变字段( varchar),记录不是固定长度的,这样存储的优点是占用空间较少。但是频繁的更新、删除记录会产生碎片,需要定期执行OPTIMIZETABLE语句或myisamchk -r
(3)压缩表:压缩表由myisamchk工具创建,占据非常小的空间,因为每条记录都是被单独压缩的,所以只有非常小的访问开支。
2)、适用生产场景
1、公司业务不需要事务的支持
2、单方面读取或写入数据比较多的业务
3、myisam存储引擎数据读写都比较频繁场景不适合
4、使用读写并发访问相对较低的业务
5、数据修改相对较少的业务
6、对数据业务一致性要求不是非常高的业务
7、服务器硬件资源相对比较差
3、Innodb
1)、特点:
1、支持事务:支持4个事务隔离级别
2、行级(读写分离)锁定,但是全表扫描仍然会是表级锁定
3、读写阻塞与事务隔离级别相关
4、具有非常高效的缓存特性:能缓存索引,也能缓存数据
5、表与主键以簇的方式存储
6、支持外键约束,5.5以前不支持全文索引,5.5版本以后支持全文索引
7、对硬件资源要求还是比较高的场合
mysql> show processlist;

查看系统支持的存储引擎
mysql> show engines\G;
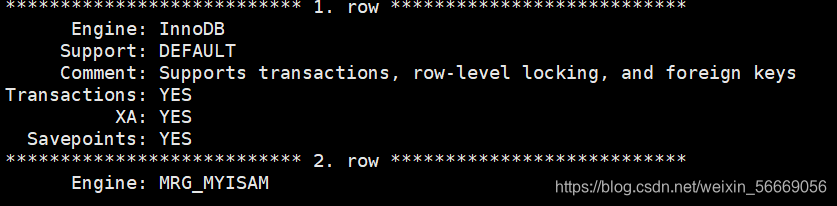
查看表使用的存储引擎
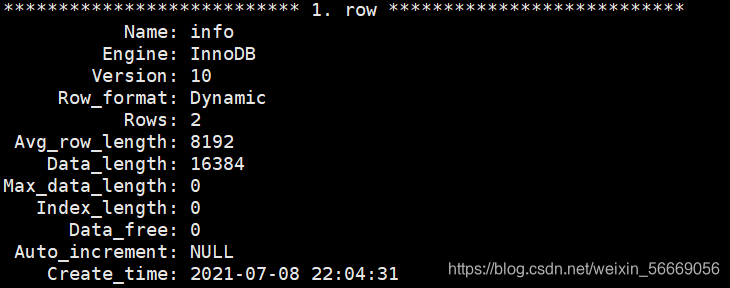
mysql> show table status from school where name='info'\G;
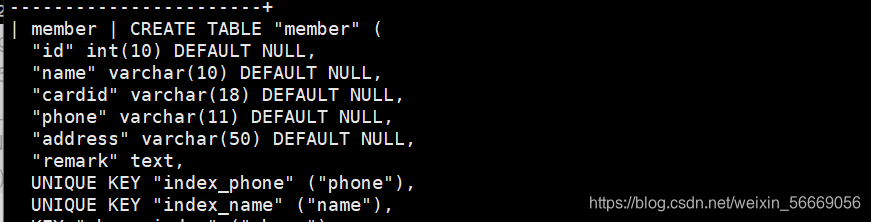
mysql> show create table member;
修改存储引擎
mysql> alter table member engine=myisam;
Query OK, 5 rows affected (0.03 sec)
Records: 5 Duplicates: 0 Warnings: 0
mysql> show create table member;

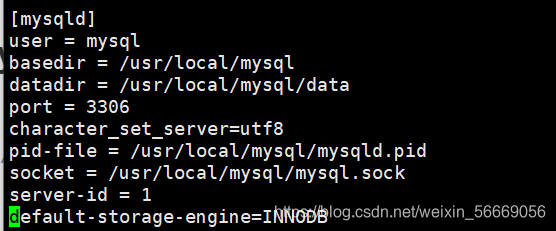
通过修改/etc/my.cnf 配置文件
[root@localhost ~]# vim /etc/my.cnf
[root@localhost ~]# systemctl restart mysqld
[root@localhost ~]# mysql -uroot -pabc123
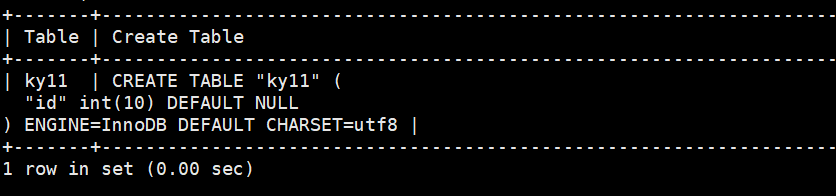
mysql> create table ky11 (id int(10));
Query OK, 0 rows affected (0.01 sec)
mysql> show create table ky11;
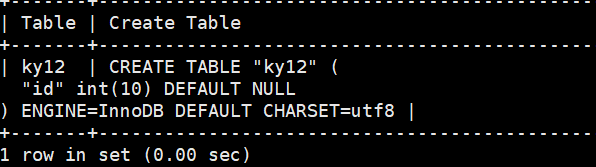
mysql> create table ky12 (id int(10))engine=innodb;
Query OK, 0 rows affected (0.01 sec)
mysql> show create table ky12;

















 1268
1268

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









