






1、注意:由于 MySQL 使用了 GUID 标识和管理复制拓扑中的事务,它要求每台服务器的 UUID 必须不 能重复,因此,务必不要使用虚拟机克隆来创建 repl-server2 和 repl-server3。
UUID含义是通用唯一识别码 (Universally Unique Identifier),这 是一个软件建构的标准,也是被开源软件基金会 (Open Software Foundation, OSF) 的组织在分布式计算环境 (Distributed Computing Environment, DCE) 领域的一部份。
UUID 的目的,是让分布式系统中的所有元素,都能有唯一的辨识资讯,而不需要透过中央控制端来做辨识资讯的指定。如此一来,每个人都可以建立不与其它人冲突的 UUID。在这样的情况下,就不需考虑数据库建立时的名称重复问题。目前最广泛应用的 UUID,即是微软的 Microsoft's Globally Unique Identifiers (GUID),而其他重要的应用,则有 Linux ext2/ext3 档案系统、LUKS 加密分割区、GNOME、KDE、Mac OS X 等等。
UUID格式:xxxxxxxx-xxxx- xxxx-xxxxxxxxxxxxxxxx(8-4-4-16)
GUID格式:xxxxxxxx-xxxx-xxxx-xxxxxx-xxxxxxxxxx (8-4-4-4-12)
注:x代表0-9或a-f范围内的一个十六进制的数字。
UUID由以下几部分的组合:
(1)当前日期和时间,UUID的第一个部分与时间有关,如果你在生成一个UUID之后,过几秒又生成一个UUID,则第一个部分不同,其余相同。
(2)时钟序列。
(3)全局唯一的IEEE机器识别号,如果有网卡,从网卡MAC地址获得,没有网卡以其他方式获得。
2、配置Linux主机
(1)# ip a s 命令查看是否有动态分配的网卡 IP 地址,使用 # dhclient 命令分配动态 IP
(2)配置网络
修改网卡:
# ip a s
# nmcli connection show
# nmcli connection modify "ens33" ipv4.addresses 192.168.30.121/24
connection.autoconnect yes
# nmcli connection up "ens33"设置主机名称,关闭防火墙:
# hostnamectl set-hostname server1
# systemctl stop firewalld
# systemctl disable firewalld
# cat >> /etc/hosts <<EOF
> 192.168.30.121 server1
> 192.168.30.122 server2
> 192.168.30.123 server3
> EOF使用 reboot 重启 server1,使用静态 IP 连接 server1,使用 ping 测试解析:
# reboot
# ping server1 -c 4 //-c 4:这个选项指定发送4个ICMP数据包来测试server1。3、安装MySQL服务器
使用虚拟光驱提取MySQL镜像文件到Linux文件系统,勾选“已连接”。
(1)在 server1 创建光盘镜像的挂载目录/mnt/cdrom,然后从挂载目录复制到根目录:
# mkdir /mnt/cdrom
# mount /dev/cdrom /mnt/cdrom
# cp -R /mnt/cdrom/stage / //-r 或 --recursive:用于复制目录及其所有的子目录和文件,如果要复制目录,需要使用该选项。
# ls -l /stage/(2)将 MySQL8.0 程序解压到 /opt 目录,再创建到 MySQL 默认安装目录 /usr/local/mysql 的软连接, 访问默认安装目录时就会连接到实际的安装目录,这种方法非常方便后续软件版本升级:
# cd /opt
# tar xf /stage/mysql-commercial-8*.tar.gz
# ln -s /opt/mysql* /usr/local/mysql
# ls /usr/local/mysql/bin(3)将 mysql 客户机和使用程序的路径添加到 PATH 系统环境变量中,以便随时使用这些程序。
# vim ~/.bashrc
添加export PATH=$PATH:/usr/local/mysql/bin
# source ~/.bashrc //使修改在当前 shell 立即生效。(4)接着复制已经编写好的my.cnf配置文件到系统默认位置 /etc目录,并添加mysql用户,将来MySQL8 数据库服务器属于 mysql 所拥有,adduser-r 选项会创建一个非登录账户,以利于安全考虑。
# cp /stage/my.cnf /etc/my.cnf
# adduser -r mysqladduser -r命令的作用是创建一个系统用户,也就是一个没有登录账户的用户。这种用户通常用于运行系统服务,因为它们不具有交互式shell访问权限,而且他们的权限通常比常规用户更受限制。使用-r选项创建的用户具有以下特点:
- 没有密码:无法通过登录来访问该用户账户。
- 没有家目录:不会为该用户创建/home目录,节省磁盘空间。
- 没有登录Shell:无法以该用户身份进行交互式登录,因为Shell被设置为/sbin/nologin或/bin/false。
在Linux系统中,系统用户通常以uid小于1000的数字标识符表示。使用adduser -r命令创建的系统用户的UID通常开始于100,以确保与普通用户的UID不冲突。
(5)使用 mysqld –initialize 命令创建数据库,该命令会在默认的数据目录 /var/lib/mysql 目录生 成新数据库运行所必须的文件,包括三个系统数据库目录:msyql、performance_schema、sys;innodb 存储引擎的系统表空间文件;服务器和客户端的 ssl 加密公钥和私钥文件;重做日志文件;还原表空间文件等。
在建库的同时,该命令还给 MySQL 服务器的最高管理账户 root 生成了一个临时口令,在初次登陆 时需要重置 root 口令,否则不能执行进一步的操作。记录下该临时口令备用。
# mysqld --initialize
# ls /var/lib/mysql/由于 pid-file 选项引用的是 /var/run/mysqld 目录,但该目录尚不存在,创建该目录并将其所有权 授予 mysql 用户和组。
# cat /etc/my.cnf
# mkdir /var/run/mysqld
# chown mysql:mysql /var/run/mysqld/(6)现在就可以启动 mysqld 服务器进程,& 选项指示在后台运行:
# mysql_safe &(7)为了能从 server1 主机上的 Linux 客户机访问 mysqld 服务器进程,需要配置 client 的 socket 选项, 使用 vim 打开 /etc/my.cnf 配置文件,添加如下代码,保存退出。
[client]
socket=/var/lib/mysql/mysql.sock使用 mysql 客户机以 root 用户登陆,输入建库时系统生成的临时口令:
# mysql -uroot -p输入 ALTER USER USER() IDENTIFIED BY 'oracle'; 语句重置 root 口令后,才能正常执行数据库操作:
mysql> ALTER USER USER() IDENTIFIED BY 'oracle';
mysql> show databases;(8)最后,配置 mysqld 系统服务,以便可以使用 Linux 操作系统的 systemctl 命令来管理 mysqld 服务。
关闭 mysqld 服务:
# mysqladmin -uroot -p shutdown
复制 mysqld.service 服务配置文件到 systemd 系统目录,启用即可:
# cp /stage/mysqld.service /usr/lib/systemd/system
# systemctl enable mysqld.service
# systemctl start mysqld
# systemctl status mysqld
从操作系统检查 mysqld 的状态:
# ps aux | grep mysqld提示:server1 上的 /stage 目录可以更方便地使用 scp 命令直接发送到其它机器的根目录,而不 必使用光驱镜像方式。
[root@server1~]# scp -r /stage root@server2:/
[root@server1~]# ssh root@server2 "ls /stage"4、配置复制拓扑
本节实验的操作需同时在三台主机上进行,因此要确保各个主机上的 MySQL 服务器都正常运行, 同时各主机之间的网络均可相互访问。
典型的复制拓扑是主/从属服务器的一对多关系,高级复杂复制拓扑有双向复制、循环复制以及多源复制等。本章节实验涵盖了在三个独立节点上构建循环复制拓扑的技术内容。
(1)配置基本复制结构
分别在三台主机上停止 mysqld 服务,并对状态进行确认:
# systemctl stop mysqld
# systemctl status mysqld对三个 MySQL 服务器的配置文件/etc/my.cnf分别进行编辑,在 [mysqld] 选项组中添加以下条目:
server-id=11
...
log-bin=server1-bin //定义二进制日志文件
relay-log=server1-relay-bin //定义中继二进制日志文件
# gtid-mode=ON
# enforce-gtid-consistency注意,一个复制结构中的每台 mysqld 实例必须要有唯一的 server-id, id 值分别为 11、12 和 13。 其中被注释的两行将在后面启用 gtid 时使用。 log-bin 和 relay-log 分别用来定义二进制日志文件和中继二进制日志文件,也要注意区分编号。
分别启动三台服务器并检查进程状态:
# systemctl start mysqld
# ps aux | grep mysqld //-aux 显示所有包含其他使用者的进程在数据目录下可以看到二进制日志文件按照 log-bin 选项的格式进行了设置:
# ls /var/lib/mysql/使用 mysql 客户机以 root 用户登陆到 server1,执行 show master status 命令检查服务器的状态, 记下该二级制日志文件的名称和坐标位置 155,这是开始复制时的起始位置。所有服务器的默认角色都是 master 主服务器。
mysql> SHOW MASTER STATUS\G在 server1 上创建用于执行复制的 MySQL 用户,并授予 replication slave 权限。注意,基于简化配置的考虑,在 repl 用户创建时特别指定了使用非加密验证插件 mysql_native_password,而不是默 认的 caching_sha2_password 插件,主要是 caching_sha2_password 要求配置加密连接,而这个实验的重点在于复制技术本身。
mysql> CREATE USER 'repl' IDENTIFIED WITH mysql_native_password BY 'oracle';
mysql> GRANT REPLICATION SLAVE ON *.* TO 'repl';
在 server1 上创建测试用数据库 world 并填充数据,数据来自转储文件 world.sql:
mysql> CREATE DATABASE world;
mysql> USE world
mysql> SOURCE /stage/world.sql
mysql> show databases;mysql中的source命令用于执行外部SQL脚本,它可以加载指定文件中的SQL语句并执行。使用source命令可以方便地管理和执行大型SQL脚本,而不需要手动复制和粘贴每个SQL语句。
使用方法如下:
source <path to sql file>其中,<
path to sql file>指定了要执行的SQL脚本文件的路径。执行后,MySQL将会自动读取文件中的SQL代码并执行它们。需要注意的是,被执行的SQL脚本文件必须是可读的,并且对于该脚本文件的用户,必须具有足够的权限来执行其中的SQL语句。source命令还有一个常用的用途是在MySQL控制台中加载一个已保存的查询文件,在控制台中执行查询语句。例如:
source /home/user/queries/query1.sql这个命令会在MySQL控制台中加载指定路径下的query1.sql文件,并执行其中的查询语句。这样可以方便地重复使用保存的查询,并减少手动输入SQL语句的错误。
接着配置 server2 成为 server1 的 slave,并启动复制线程,观察数据的同步。
登陆到 server2 服务器,首先执行 CHANGE MASTER TO 命令将 server2 角色更改成为 server1 的从属服务器,再启动复制线程,最后检查 world 数据库是否同步到了 server2:
mysql> CHANGE MASTER TO
-> MASTER_HOST='server1',
-> MASTER_POST=3306,
-> MASTER_LOG_FILE='server1-bin.000001',
-> MASTER_LOG_POS=155;
mysql> START SLAVE USER='repl' PASSWORD='oracle';
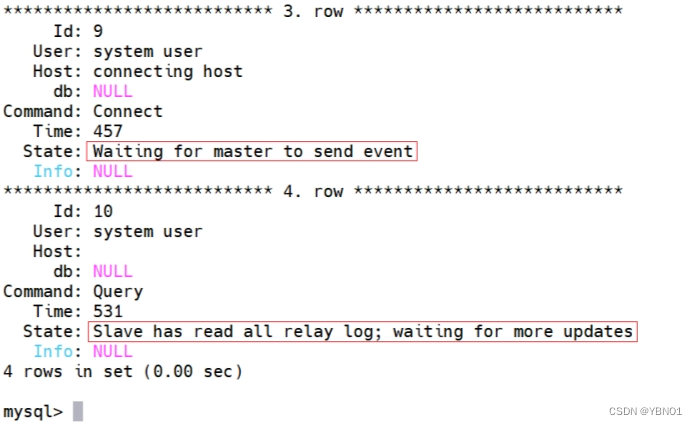
mysql> SHOW DATABASES;在 server1 和 server2 上分别执行 show processlist 命令来检查复制的相关线程: server1 上可以看到有转储线程,它将二进制日志已经发送到 server2 上:
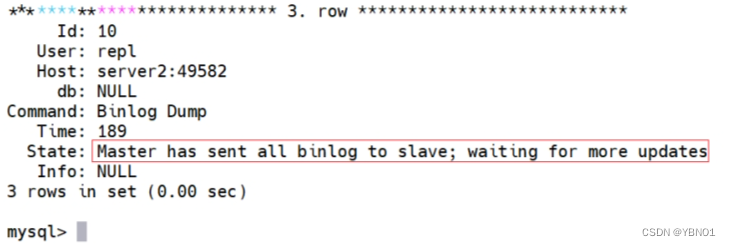
在 server2 上可以看到 I/O 线程和 SQL 线程:
基本的复制拓扑已经配置好,在 server1 上的更改会立即同步到 server2。
(2)给复制拓扑添加新节点
把 server3 加入到前面由 server1 和 server2 组成的复制结构中,server3 会成为 server2 的从属服务器,三个节点共同组成了一个三层的主从简单复制拓扑:server1 -> server2 -> server3。
要将 server3 作为 server2 的从属服务器,首先要把 server2 的历史数据复制到 server3 以保证数据库数据的完整性,这需要使用 mysqldump 工具以逻辑备份的方式将 world 数据库整体转储到一个 sql 文件中保存,然后把该文件发送到 server3 并导入即可。
使用mysqldump工具时可以添加--master-data=2选项,它会在输出文件中添加注释起来的CHANGE MASTER TO 语句,这样在 server3 上导入数据的同时会将 server3 的角色更改为 server2 的 slave。
[root@server2 ~]# mysqldump -uroot -p --master-data=2 \
> -B world > /tmp/server2.sql
[root@server2 ~]# ll /tmp/server2.sql
编辑导出的文件,去掉注释,并添加 MASTER_HOST='server2', MASTER_PORT=3306, 也就是 server3 的主服务器 server2,保存。
CHANGE MASTER TO MASTER_HOST='',MASTER_POST=3306,MASTER_LOG_FILE='',MASTER_LOG_POS=736143;将修改后的转储文件发送到 server3,使用 scp 命令:
[root@server2 ~]# scp /tmp/server2.sql root@server3:/tmp/在 server3 确认转储文件:
[root@server3 ~]# ll /tmp/server2.sql
登陆 server3 服务器,使用 source 命令导入转储文件:
mysql> SOURCE /tmp/server2.sql启动复制线程:
mysql> START SLAVE USER='repl' PASSWORD='oracle';检查 slave 从属服务器的状态,可以看到 I/O 线程和 SQL 线程都正常运行:
mysql> SHOW SLAVE STATUS\G
SHOW SLAVE STATUS命令用于显示MySQL复制从库的状态信息。通过添加\G,可以以更易读的格式显示输出,每个状态变量都显示在单独的行上。
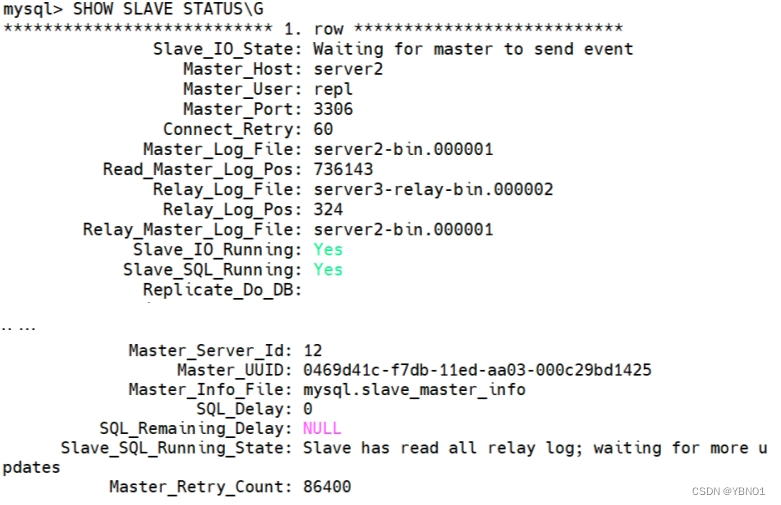
至此,由三个节点构建的多级主从复制结构就已配置完成,下面进行验证。
在 server1 上删除 city 表的 id 大于 4070 的行,然后在 server2 和 server3 上验证。
server1:
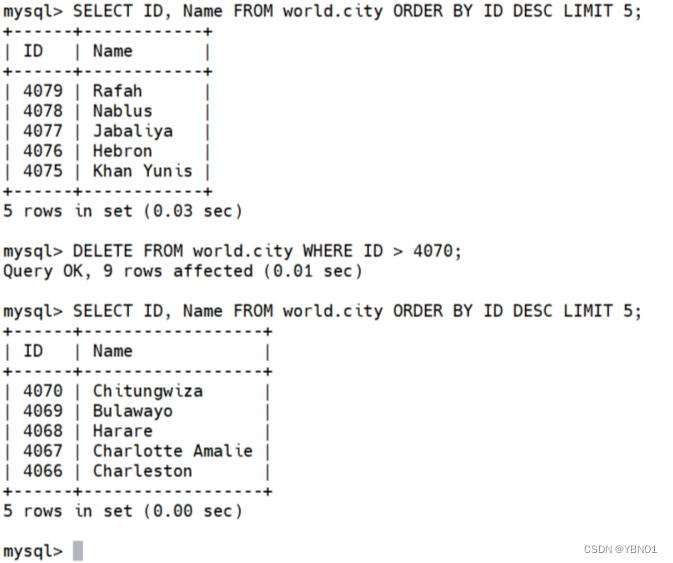
server2:

server3:
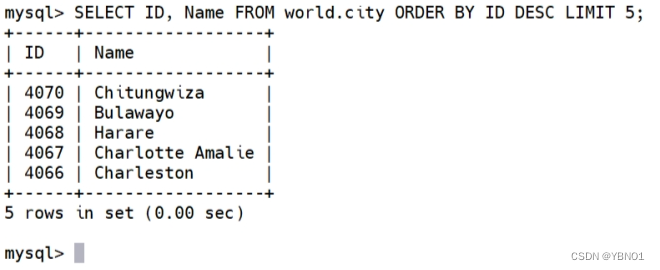
可以看到,server1 上的删除操作,在 server2 和 server3 上都同步进行了删除,保持了数据的一 致性。 另外,在 server2 和 server3 上执行 show slave status 命令检查复制的状态,中继日志坐标位置分别是 736780 和 875,最后,自行在 server3 添加 repl 用户,并授予 replication slave 权限,以备下节使用。
(3)启用 GUID 并配置循环复制
二进制日志坐标只适应于简单的复制结构,对于复杂的比如循环、双向和多源复制,二进制日志 坐标就不能唯一标识一个事务了,这个时候必须使用 GTID(全局事务标识符)来记录产生更改的 事务。
每个 GTID 记录了一次修改,GTID 的格式为<source-uuid>:<transaction-id>,
例如单个事务: 0ed18583-47fd-11e2-92f3-0019b944b7f7:338
或者记录一组事务的集合: 0ed18583-47fd-11e2-92f3-0019b944b7f7:1-338
其中,UUID 用来唯一标识每一个服务器,事务的编号记录了在该服务器上执行的事务的顺序。
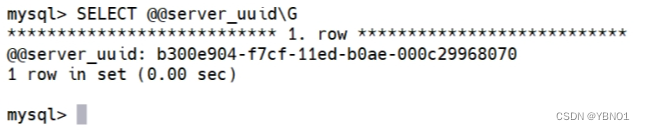
使用 SELECT @@server_uuid\G 命令可以查看服务器的 UUID,sever1 的 UUID 值显示如下:
在复杂复制拓扑中,必须使用 GTID 才能唯一标识某一个事务。
下面我们将在三个服务器上启用 GTID,并构建循环拓扑,也即将 server1 设置为 server3 的 slave, 在这种结构中,每一个服务器既是 master,同时又是 slave,在任何一个服务器上的修改,都会同 步到其余的两个服务器上。
在三个节点上分别操作,先关闭 mysqld 实例,然后修改 my.cnf 配置文件,去除 gtid-mode=ON 和 enforce-gtid-consistency 两个选项的注释,保存。
# systemctl stop mysqld
# vim /etc/my.cnf
# cat /etc/my.cnf分别启动三个 mysqld 实例:
# systemctl start mysqld
# systemctl status mysqld在 server2 和 server3 上执行 stop slave 命令以停止从属服务器上的 I/O 和 SQL 线程。
mysql> STOP SLAVE;
在 sever1、server2 和 server3 上分别执行 reset master 命令,该命令会复位现有的二进制日志文 件,并将 gtid_executed 和 gtid_purged 设置为空字符串,以便日志文件仅包含使用 GTID 的事件。
在MySQL GTID(全局事务标识符)复制中,
gtid_executed记录了主库上已经提交的事务GTID,从库要将主库的变更同步到自己的数据库中,就需要使用gtid_executed来判断自己是否执行过这个事务,如果没有执行过,则需要执行该事务,否则忽略该事务。
gtid_purged具体作用如下:标识当前MySQL实例已经执行过的事务;用于保证在主从复制中避免重复执行已经执行过的事务;用于在故障恢复时快速确定需要恢复的事务;用于检查GTID是否在有效的GTID集合中,以便正确地应用更新。在MySQL GTID复制机制中,gtid_purged非常重要,因为它确保了数据的正确性和一致性。
将它们设置为空字符串可能会导致MySQL服务器无法正确地识别其复制状态,从而可能会导致数据不一致或复制中断的情况。
mysql> RESET MASTER;
mysql> SELECT @@server_uuid\G在 server2 和 server3 上分别执行 CHANGE MASTER TO MASTER_AUTO_POSITION=1;和 START SLAVE USER='repl' PASSWORD='oracle'; 恢复前面的三层复制结构,注意这次使用的是 GTID。
mysql> CHANGE MASTER TO MASTER_AUTO_POSITION=1;
mysql> START SLAVE USER='repl' PASSWORD='oracle';
mysql> SHOW SLAVE STATUS\G验证复制功能,在 server1 上删除 city 表 ID 大于 4060 的行:
mysql> DELECT FROM world.city WHERE ID > 4060;在 server2 和 server3 上查看到相同的同步结果,复制成功:
SELECT ID,Name FROM world.city ORDER BY ID DESC LIMIT 5;在 server3,检查从属服务器状态:
mysql> SHOW SLAVE STATUS\G可以看到,server3 上执行的事务,其事务初始执行位置是在 server1。
继续,在 server1 上执行 change master to 命令,更改 server3 为 server1的 master,并启动复制:
mysql> CHANGE MASTER TO MASTER_HOST='server3',MASTER_AUTO_POSITION=1;
mysql> START SLAVE USER='repl' PASSWORD='oracle':
MASTER_HOST:指定主服务器的主机名或IP地址。
MASTER_AUTO_POSITION:指定MySQL GTID复制机制是否启用。如果设置为1,则启用GTID复制机制;如果设置为0,则禁用GTID复制机制。
在 server2 上删除 city 表 ID 大于 4050 的行:
mysql> DELECT FROM world.city WHERE ID > 4050;
mysql> SELECT ID,Name FROM world.city ORDER BY ID DESC LIMIT 5;在 server1 上大于 4050 的行也被删除,查询 server1 的 gtid_executed 变量可以看到该删除操作的 初始执行位置是 server2 (server2 的 UUID=0469d41c-f7db-11ed-aa03-000c29bd1425):
mysql> SELECT ID,Name FROM world.city ORDER BY ID DESC LIMIT 5;
mysql> SELECT @@global.gtid_executed\G
SELECT @@global.gtid_executed:这是一个查询语句,用于查询MySQL数据库服务器上已经执行的GTID列表。
@@global.gtid_executed:这个变量表示MySQL数据库服务器上已经执行的GTID列表。
\G:这是一个命令行工具中的快捷方式,它可以将结果集转换为垂直格式并进行显示,使得我们可以更加容易地阅读结果。
在MySQL GTID复制机制中,GTID是指全局事务标识符,它是由MySQL服务器生成的一个全局唯一的标识符,用于标识每个已提交的事务。这使得在主从复制过程中可以更加准确地确定哪些事务已经被执行,避免主从数据不一致的问题。
通过执行以上命令,我们可以查看已经执行的GTID列表,以便更好地管理MySQL主从复制,并排查主从数据同步的问题。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









