







目录
有关数据表的DML操作INSERT INTO、DELETE、TRUNCATE、UPDATE、SELECT、条件查
询、查询排序、聚合函数、分组查询。
1.INSERT语句
INSERT INTO table [(column [, column...])] VALUES(value [, value...]);
默认情况下,一次插入操作只插入一行一次性插入多条记录:
INSERT INTO table [(column [, column...])] VALUES(value [, value...]),(value [, value...])
如果为每列都指定值,则表名后不需列出插入的列名;
如果不想在表名后列出列名,可以为那些无法指定的值插入null
可以使用如下方式一次插入多行:
insert into 表名[(列名,…)]
select 语句——可以非常复杂。
如果需要插入其他特殊字符,应该采用\转义字符做前缀
2.REPLACE语句
replace语句的语法格式有三种语法格式。
语法格式1:replace into 表名 [(字段列表)] values (值列表)
语法格式2:
replace [into] 目标表名[(字段列表1) select (字段列表2) from 源表 where 条件表达式
语法格式3:
replace [into] 表名 set 字段1=值1, 字段2=值2
REPLACE与INSERT语句区别:
replace语句的功能与insert语句的功能基本相同,不同之处在于:使用replace语句向表插入新记录
时,如果新记录的主键值或者唯一性约束的字段值与已有记录相同,则已有记录先被删除(注意:
已有记录删除时也不能违背外键约束条件),然后再插入新记录。
使用replace的最大好处就是可以将delete和insert合二为一(效果相当于更新),形成一个原子操作,
这样就无需将delete操作与insert操作置于事务中了。
3.UPDATE语句
UPDATE table
SET column = value [, column = value]
[WHERE condition];
修改可以一次修改多行数据,修改的数据可用where子句限定,where子句里是一个条件表达式,
只有符合该条件的行才会被修改。没有where子句意味着where字句的表达式值为true,也可以同
时修改多列,多列的修改中间采用逗号’,’隔开。
4.DELETE和TRUNCATE语句
DELETE FROM table_name [where 条件];
TRUNCATE TABLE table_name
DROP、TRUNCATE、DELETE的区别:
delete:删除数据,保留表结构,可以回滚,如果数据量大,很慢。
truncate: 删除所有数据,保留表结构,不可以回滚,一次全部删除所有数据,速度相对很快。
drop: 删除数据和表结构,删除速度最快。
5.SELECT语句
简单的SELECT语句:
简单的SELECT语句:
SELECT {*, column [alias],...}
FROM table;说明:
–SELECT列名列表。*表示所有列。
–FROM 提供数据源(表名/视图名)
–默认选择所有行
SELECT语句中的算术表达式:
对数值型数据列、变量、常量可以使用算数操作符创建表达式(+ - * /)
对日期型数据列、变量、常量可以使用部分算数操作符创建表达式(+ -)
运算符不仅可以在列和常量之间进行运算,也可以在多列之间进行运算。
SELECT last_name, salary, salary*12
FROM employees;
补充:+说明
-- MySQL的+默认只有一个功能:运算符
SELECT 100+80; # 结果为180
SELECT '123'+80; # 只要其中一个为数值,则试图将字符型转换成数值,转换成功做预算,结果为203
SELECT 'abc'+80; # 转换不成功,则字符型数值为0,结果为80
SELECT 'This'+'is'; # 转换不成功,结果为0
SELECT NULL+80; # 只要其中一个为NULL,则结果为NULL
运算符的优先级:
乘法和除法的优先级高于加法和减法
同级运算的顺序是从左到右
表达式中使用括号可强行改变优先级的运算顺序
SELECT last_name, salary, salary*12+100
FROM employees;
SELECT last_name, salary, salary*(12+100)
FROM employees;
限制所选择的纪录:
使用WHERE子句限定返回的记录
WHERE子句在FROM 子句后:
SELECT[DISTINCT] {*, column [alias], ...}
FROM table–[WHEREcondition(s)];
WHERE中的字符串和日期值
字符串和日期要用单引号扩起来
字符串是大小写敏感的,日期值是格式敏感的
SELECT last_name, job_id, department_id
FROM employees
WHERE last_name = "king";
WHERE中比较运算符:
SELECT last_name, salary, commission_pct
FROM employees
WHERE salary<=1500;
其他比较运算符-----使用BETWEEN运算符显示某一值域范围的记录
SELECTlast_name, salary
FROM employees
WHERE salary BETWEEN 1000 AND 1500;
使用IN运算符-----使用IN运算符获得匹配列表值的记录
SELECTemployee_id, last_name, salary, manager_id
FROM employees
WHERE manager_id IN (7902, 7566, 7788);
使用LIKE运算符-----使用LIKE运算符执行模糊查询
查询条件可包含文字字符或数字
(%) 可表示零或多个字符
( _ ) 可表示一个字符
SELECT last_name
FROM employees
WHERE last_name LIKE '_A%';
使用IS NULL运算符
查询包含空值的记录
SELECT last_name, manager_id
FROM employees
WHERE manager_id IS NULL;
逻辑运算符
使用AND运算符----- AND需要所有条件都是满足T.
使用OR运算符-----OR只要两个条件满足一个就可以
使用NOT运算符-----NOT是取反的意思使用正则表达式:REGEXP
<列名> regexp '正则表达式'
例:select * from product where product_name regexp '^2018';
数据分组--GROUP BY
GROUP BY子句的真正作用在于与各种聚合函数配合使用。它用来对查询出来的数据进行分组
分组的含义是:把该列具有相同值的多条记录当成一组记录处理,最后只输出一条记录。
分组函数忽略空值,结果集隐式按升序排列,如果需要改变排序方式可以使用Order by 子句。
#如果select语句中的列未使用组函数,那么它必须出现在GROUP BY子句中
#而出现在GROUP BY子句中的列,不一定要出现在select语句中分组函数重要规则:
如果使用了分组函数,或者使用GROUP BY 的查询:出现在SELECT列表中的字段,要么出现在组合函数里,要么出现在GROUP BY 子句中。
GROUP BY 子句的字段可以不出现在SELECT列表当中。
使用集合函数可以不使用GROUP BY子句,此时所有的查询结果作为一组。
数据分组--限定组的结果:HAVING子句
HAVING子句用来对分组后的结果再进行条件过滤。
#分组后加条件 使用having
#where和having都是用来做条件限定的,但是having只能用在group by之后
HAVING与WHERE的区别:
WHERE是在分组前进行条件过滤, HAVING子句是在分组后进行条件过滤,WHERE子句中不
能使用聚合函数,HAVING子句可以使用聚合函数。
组函数的错误用法:
不能在WHERE 子句中限制组;
限制组必须使用HAVING 子句;
不能在WHERE 子句中使用组函数。
对结果集排序:
查询语句执行的查询结果,数据是按插入顺序排列
实际上需要按某列的值大小排序排列
按某列排序采用order by 列名[desc],列名…
设定排序列的时候可采用列名、列序号和列别名
如果按多列排序,每列的asc,desc必须单独设定
联合查询
例如:查询中国或美国的城市信息
SELECT * FROM city
WHERE countrycode IN ('CHN' ,'USA');
SELECT * FROM city WHERE countrycode='CHN'
UNION ALL
SELECT * FROM city WHERE countrycode='USA'说明:一般情况下,我们会将 IN 或者 OR 语句 改写成 UNION ALL,来提高性能
UNION 去重复
UNION ALL 不去重复
查询结果限定:
在SELECT语句最后可以用LIMLT来限定查询结果返回的起始记录和总数量。MySQL特有。
SELECT … LIMIT offset_start,row_count;
offset_start:第一个返回记录行的偏移量。默认为0.
row_count:要返回记录行的最大数目。
例如:
SELECT * FROM TB_EMP LIMIT 5;/*检索前5个记录*/
SELECT * FROM TB_EMP LIMIT 5,10;/*检索记录行6-15*/MySQL中的通配符:
MySQL中的常用统配符有三个:
%:用来表示任意多个字符,包含0个字符
_ : 用来表示任意单个字符
escape:用来转义特定字符
6.SQL函数
聚合函数
聚合函数对一组值进行运算,并返回单个值。也叫组合函数。
COUNT(*|列名) 统计行数
AVG(数值类型列名) 平均值
SUM (数值类型列名) 求和
MAX(列名) 最大值
MIN(列名) 最小值
除了COUNT()以外,聚合函数都会忽略NULL值
| 函数名称 | 作用 |
| MAX | 查询指定列的最大值 |
| MIN | 查询指定列的最小值 |
| COUNT | 统计查询结果的行数 |
| SUM | 求和,返回指定列的总和 |
| AVG | 求平均值,返回指定列数据的平均值 |
数值型函数
| 函数名称 | 作用 |
| ABS | 求绝对值 |
| SQRT | 求平方根 |
| POW和POWER | 两个函数的功能相同,返回参数的幂次方 |
| MOD | 求余数 |
| CEIL和CEILING | 两个函数功能相同,都是返回不小于参数的最小整数,即向上取整 |
| FLOOR | 向下取整,返回值转化为一个BIGINT |
| RAND | 生成一个0~1之间的随机数,传入整数参数是,用来产生重复序列 |
| ROUND | 对所传参数进行四舍五入 |
| SIGN | 返回参数的符号 |
字符串函数
| 函数名称 | 作用 |
| LENGTH | 计算字符串长度函数,返回字符串的字节长度 |
| CHAR_LENGTH | 计算字符串长度函数,返回字符串的字节长度,注意两者的区别 |
| CONCAT | 合并字符串函数,返回结果为连接参数产生的字符串,参数可以使一个或多个 |
| INSERT(str,pos,len,newstr) | 替换字符串函数 |
| LOWER | 将字符串中的字母转换为小写 |
| UPPER | 将字符串中的字母转换为大写 |
| LEFT(str,len) | 从左侧字截取符串,返回字符串左边的若干个字符 |
| RIGHT | 从右侧字截取符串,返回字符串右边的若干个字符 |
| TRIM | 删除字符串左右两侧的空格 |
| REPLACE(s,s1,s2) | 字符串替换函数,返回替换后的新字符串 |
| SUBSTRING(s,n,len) | 截取字符串,返回从指定位置开始的指定长度的字符换 |
| REVERSE | 字符串反转(逆序)函数,返回与原始字符串顺序相反的字符串 |
| STRCMP(expr1,expr2) | 比较两个表达式的顺序。若expr1 小于 expr2 ,则返回 -1,0相等,1则相反 |
| LOCATE(substr,str [,pos]) | 返回第一次出现子串的位置 |
| INSTR(str,substr) | 返回第一次出现子串的位置 |
日期和时间函数
| 函数名称 | 作用 |
| CURDATE() CURRENT_DATE() CURRENT_DATE | 两个函数作用相同,返回当前系统的日期值 |
| CURTIME CURRENT_TIME() CURRENT_TIME | 两个函数作用相同,返回当前系统的时间值 |
| NOW | 返回当前系统的日期和时间值 |
| SYSDATE | 返回当前系统的日期和时间值 |
| DATE | 获取指定日期时间的日期部分 |
| TIME | 获取指定日期时间的时间部分 |
| MONTH | 获取指定日期中的月份 |
| MONTHNAME | 获取指定曰期对应的月份的英文名称 |
| DAYNAME | 获取指定曰期对应的星期几的英文名称 |
| YEAR | 获取年份,返回值范围是 1970〜2069 |
| DAYOFWEEK | 获取指定日期对应的一周的索引位置值,也就是星期数,注意周日是开始日,为1 |
| WEEK | 获取指定日期是一年中的第几周,返回值的范围是否为 0〜52 或 1 〜53 |
| DAYOFYEAR | 获取指定曰期是一年中的第几天,返回值范围是1~366 |
| DAYOFMONTH 和 DAY | 两个函数作用相同,获取指定日期是一个月中是第几天,返回值范围是1~31 |
| DATEDIFF(expr1,expr2) | 返回两个日期之间的相差天数,如 SELECT DATEDIFF('2007-12-31 23:59:59','2007-12-30'); |
| SEC_TO_TIME | 将秒数转换为时间,与TIME_TO_SEC 互为反函数 |
| TIME_TO_SEC | 将时间参数转换为秒数,是指将传入的时间转换成距离当天00:00:00的秒数,00:00:00为基数,等于 0 秒 |
流程控制函数
| 函数名称 | 作用 |
| IF(expr,v1,v2) | 判断,流程控制,当expr = true时返回 v1,当expr = false、null 时返回v2 |
| IFNULL(v1,v2) | 判断是否为空,如果 v1 不为 NULL,则 IFNULL 函数返回 v1,否则返回 v2 |
| CASE | 搜索语句 |
7.实验-单表查询
#创建表结果 注意使用'`'反引号哈~
mysql> CREATE TABLE `worker`(
-> `部门号` int(11) NOT NULL,
-> `职工号` int(11) NOT NULL,
-> `工作时间` date NOT NULL,
-> `工资` float(8,2) NOT NULL,
-> `政治面貌` varchar(10) NOT NULL DEFAULT '群众',
-> `姓名` varchar(20) NOT NULL,
-> `出生日期` date NOT NULL,
-> PRIMARY KEY(`职工号`)
-> )ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC;#查看表结构
mysql> desc worker;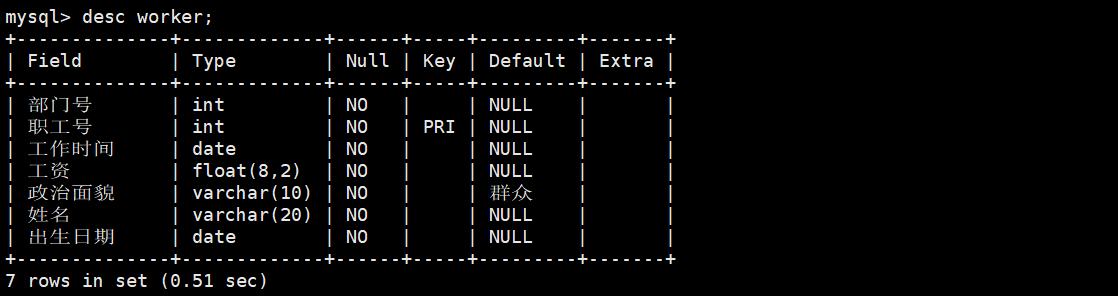
#向表中添加数据
mysql> INSERT INTO `worker`(`部门号`,`职工号`,`工作时间`,`工资`,`政治面貌`,`姓名`,`出生日期`) VALUES(101,1001,'2015-5-4',3500.00,'群众','张三','1990-7-1');
mysql> INSERT INTO `worker`(`部门号`,`职工号`,`工作时间`,`工资`,`政治面貌`,`姓名`,`出生日期`) VALUES(101,1002,'2017-2-6',3200.00,'团员','李四','1997-2-8');
mysql> INSERT INTO `worker`(`部门号`,`职工号`,`工作时间`,`工资`,`政治面貌`,`姓名`,`出生日期`) VALUES(102,1003,'2011-1-4',8500.00,'党员','王亮','1983-6-8');
mysql> INSERT INTO `worker`(`部门号`,`职工号`,`工作时间`,`工资`,`政治面貌`,`姓名`,`出生日期`) VALUES(102,1004,'2016-10-10',5500.00,'群众','赵六','1994-9-5');
mysql> INSERT INTO `worker`(`部门号`,`职工号`,`工作时间`,`工资`,`政治面貌`,`姓名`,`出生日期`) VALUES(102,1005,'2014-4-1',4800.00,'党员','钱七','1992-12-30');
mysql> INSERT INTO `worker`(`部门号`,`职工号`,`工作时间`,`工资`,`政治面貌`,`姓名`,`出生日期`) VALUES(102,1006,'2017-5-5',4500.00,'党员','孙八','1996-9-2');1. 显示所有职工的基本信息。
mysql> select * from worker;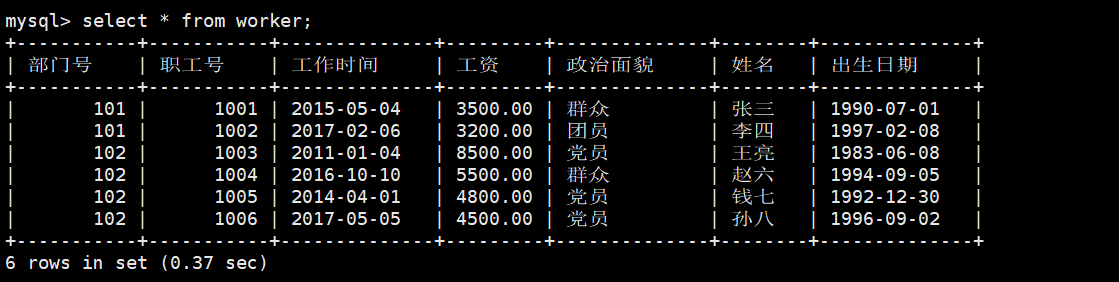
2.查询所有职工所属部门的部门号,不显示重复的部门号。
mysql> select distinct `部门号` from worker;
3.求出所有职工的人数。
mysql> select count(`职工号`) from worker;
4.列出最高工和最低工资。
mysql> select MAX(`工资`),MIN(`工资`) from worker;
5.列出职工的平均工资和总工资。
mysql> select AVG(`工资`),SUM(`工资`) from worker;
6.创建一个只有职工号、姓名和参加工作的新表,名为工作日期表。
#创建完成后并查看表结构
mysql> create table workdate select `职工号`,`姓名`,`工作时间` from worker;
mysql> desc workdate;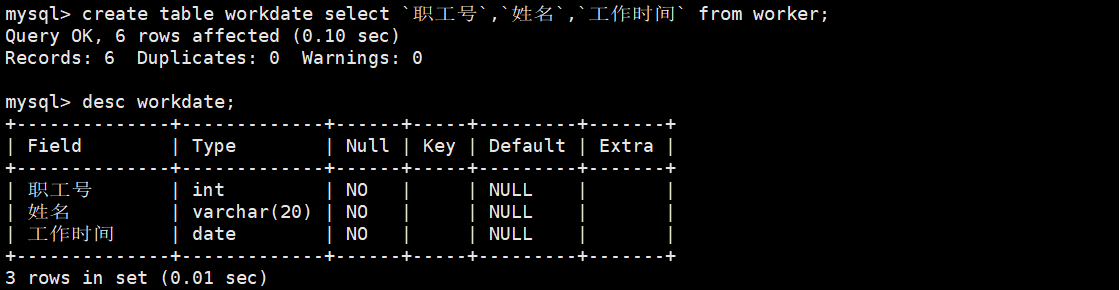
7.显示所有女职工的年龄。
#由于我们表中信息无‘性别’一栏,所以我们在此处将‘女职工’改为‘职工’哈~
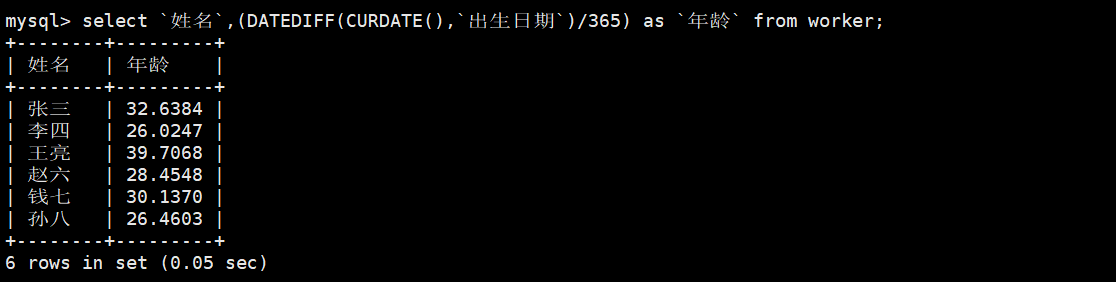
mysql> select `姓名`,('2023'-year(`出生日期`)) as `年龄` from worker;
或
mysql> select `姓名`,(DATEDIFF(CURDATE(),`出生日期`)/365) as `年龄` from worker;
#如果有‘性别’一栏,命令可以写为:
select `姓名`,('2023'-year(`出生日期`)) as `年龄` from worker where `性别`=“女”;
或
select `姓名`,(DATEDIFF(CURDATE(),`出生日期`)/365) as `年龄` from worker where `性别`=“女”;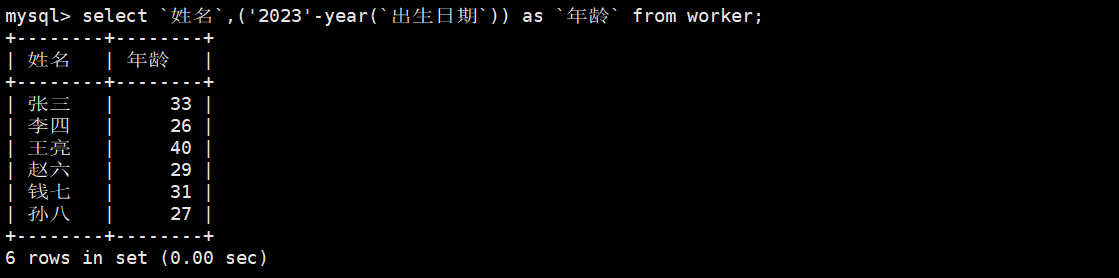
8.列出所有姓刘的职工的职工号、姓名和出生日期。
mysql> select `职工号`,`姓名`,`出生日期` from worker where `姓名` like '刘%';
9.列出1960年以前出生的职工的姓名、参加工作日期。
mysql> select `姓名`,`工作时间` from worker where `出生日期` <="1960-1-1";
10.列出工资在1000-2000之间的所有职工姓名。
mysql> select `姓名` from worker where `工资` between 1000 and 2000;
11.列出所有陈姓和李姓的职工姓名。
mysql> select `姓名` from worker where `姓名` like '陈%' or `姓名` like '李%';
12.列出所有部门号为2和3的职工号、姓名、党员否。
mysql> select `职工号`,`姓名`,if(`政治面貌`="党员","是","否") as `是否为党员` from worker where `.门号` IN (102,103);
13.将职工表worker中的职工按出生的先后顺序排序。
mysql> select * from worker order by `出生日期`;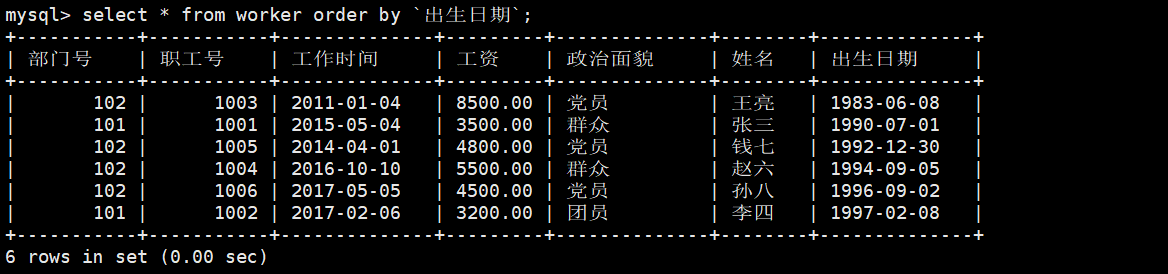
14.显示工资最高的前3名职工的职工号和姓名。
mysql> select `职工号`,`姓名` from worker order by `工资` limit 3;
15.求出各部门党员的人数。
mysql> select `部门号`,count(`职工号`) as `总人数` from worker where `政治面貌`='党员' group by `部门号`;
16.统计各部门的工资和平均工资。
mysql> select `部门号`, sum(`工资`) as `总工资`,avg(`工资`) as `平均工资` from worker group by `部门号`;
17.列出总人数大于4的部门号和总人数。
mysql> select `部门号`,count(`部门号`) as `总人数` from worker group by `部门号`;


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









