



协程和管道
协程
进程线程协程区别
程序与进程,程序是写的代码生成的二进制文件,是一个静态的概念,写好了就放在那了,而进程是一个动态的概念,同一个进程享有同一份资源,进程是程序运行时的描述,可以分为5种状态。创建态,就绪态,执行态,阻塞态,终止态,就是程序开始后就交给操作系统来管理以进程的方式。
线程,在程序执行中有时要面临多个任务,老式程序中只能顺序执行,视频时不能发消息,现在程序可以利用线程来解决这种问题,一个进程中可以含有多个线程,线程之间可以并发,从而达到边发消息边视频的功能。引入线程后,cpu就以线程为单位来进行调度,当切换到同进程的线程时,因为他们之间共享资源,切换时开销比较小,切换到别的进程的线程时才需要大量开销,总体还是减少了开销,提高了效率,并使得一个进程可以同时完成多个任务。
协程也是为了提高性能,线程遇到问题无法执行,要被替换,但是如果,给线程多个工作,一个执行不了被阻塞可以换其他工作来执行,不必切换抵消了切换的开销。而这多个工作就叫协程,协程间的切换就更小了,不涉及下处理器(cup),协程是编程概念的,程序员操作,进程线程是操作系统概念,由操作系统来管理。
1 进程是资源分配的单位
2 线程是操作系统调度的单位
3 进程切换需要的资源很最大,效率很低
4 线程切换需要的资源一般,效率一般
5 协程切换任务资源很小,效率高
6 多进程、多线程根据cpu核数不一样可能是并行的 也可能是并发的。协程的本质就是使用当前进程在不同的函数代码中切换执行,可以理解为并行。 协程是一个用户层面的概念,不同协程的模型实现可能是单线程,也可能是多线程。
详见Go语言——线程、进程、协程的区别_go线程线程进程-优快云博客
管道
协程之间可以来回切换实现高并发,还有各个goroutine之间的通信问题,线程之间通信常用手段,共享内存,消息传递,管道通信。go通信模型基于csp哲学,不推荐使用共享内存,而使用管道进行通信,此管道不是操作系统提供的管道,是go自己实现的数据结构。chan实现多个goroutine通信,所以chan一定是线程安全的,底层通过锁来实现。
| 操作 | nil的chan | 正常chan | 关闭的chan |
|---|---|---|---|
| <- ch | 阻塞 | 空阻塞,非空正常 | 读到零值 |
| ch<- | 阻塞 | 满阻塞,非满正常 | panic |
| close(ch) | panic | 成功 | panic |
无缓冲 channel 在读和写的过程中是都会阻塞,无缓冲阻塞到读写同时进行。
关于selectselect采用多路复用思想,通过多个case监听多个Channel的读写操作,任何一个case可以执行则选择该case执行,否则执行default。如果没有default,且所有的case均不能执行,则当前的goroutine阻塞。对于多个chan传递的信息,可以使用一个进程来进行处理,本来多个进程处理的事情使用一个进程就叫做多路复用,select使用一个协程同时监视多个chan信号,提高信息处理效率。针对select中case数量的不同,编译器会对生成代码进行优化,针对不同情况生成不同函数来调用。最常见情况是多个case情况,这时生成的函数叫selectgo逻辑是,1.根据规则生成遍历顺序和加锁顺序并加锁,2,根据遍历顺序检查各case对应chan的缓冲队列情况,3,没有可行情况则检测是否有default,有执行,没有则给所以chan解锁,把该协程g加入到各chan对应的发送或接收等待队列并阻塞当前进程等待唤醒。4、等有chan可行了,会唤醒该进程g并完成对应分支操作。5,对各chan加锁,在个chan发送或接收队列中移除自身,然后按序解锁后返回。
基于共享变量的并发
竞争条件
竞争条件,通过方法实现修改变量balance的函数,Balance方法和deposit方法,Deposit传入参数amount来修改balance+=balance,Banlance来得到balance的值。修改值分三步,取到寄存器,修改寄存器,放回原地址空间。不同协程同时调用这些方法时候,三个步骤之间交错进行,可能的不到我们希望的结果,操作系统的经典案例。
基于这个背景,衍生出来两种数据结构,锁,读写锁。
sync.Mutex互斥锁
sema <- struct{}{} // 无缓冲的管道,其他协程同样操作,可确保只有一个协程继续下去 balance = balance + amount //进行有风险操作,可以确保无人同步操作,这一部分叫临界区 <-sema // release token //操作完之后释放这个管道,供其他人使用。这种方式被sync.Mutex类型直接支持,lock方法就是入管道,进入临界区,unlock方法退出临界区出管道。
sync.RWMutex读写锁
读写互斥锁(RWMutex)是一种特殊类型的互斥锁,它允许多个协程同时读取某个共享资源,但在写入时必须互斥,只能有一个协程进行写操作。相比互斥锁,读写互斥锁在高并发读的场景下可以提高并发性能,但在高并发写的场景下仍然存在性能瓶颈。
关于Banlance之内为什么需要加锁,仅仅只是一个读取操作不修改值为什么需要加锁?
这个就关系到计算机组成,现代计算机是多cpu的,每一个cpu都有缓存,手写代码逻辑看似没有问题,修改后数据回缓存在本地的缓存中,写入主存顺序不同可能导致跟我们实际的逻辑结果不一致。比如这段代码可能会输出x:0 y:0或y:0 x:0,协程a两条指令不直接相关,a协程以为谁前谁后都一样,编译时两条命令的顺序就不确定了,协程b同理,所以就导致了均为0的情况出现。
var x, y int go func() { x = 1 // A1 fmt.Print("y:", y, " ") // A2 }() go func() { y = 1 // B1 fmt.Print("x:", x, " ") // B2 }()通过锁机制可以保证一系列操作顺序进行,防止协程并发执行造成未知错误。
惰性初始化
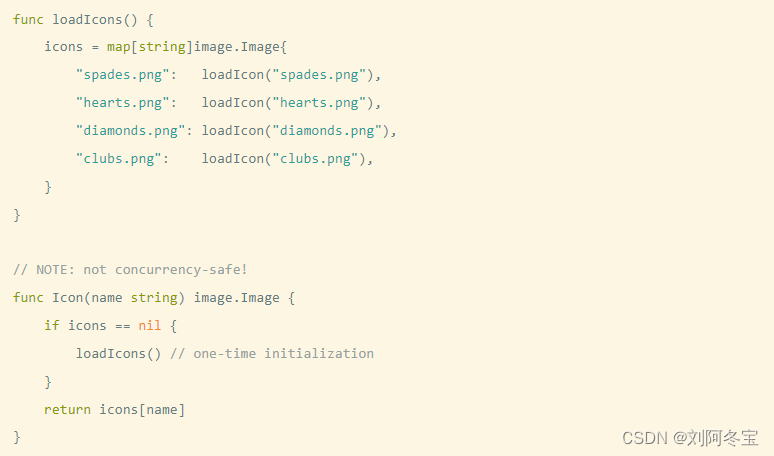
var mu sync.RWMutex // guards icons
var icons map[string]image.Image
// Concurrency-safe.
func Icon(name string) image.Image {
mu.RLock() //若已经初始化完可以直接拿到值,通过读锁即可,性能高一点也
if icons != nil {
icon := icons[name]
mu.RUnlock()
return icon
}
mu.RUnlock()
// acquire an exclusive lock
mu.Lock() //map不为nil则需要初始化,读锁就不可以了,互斥锁同步。
if icons == nil { // NOTE: must recheck for nil
loadIcons()
}
icon := icons[name]
mu.Unlock()
return icon
}这种方式比较复杂,go提供了更好的方式
var loadIconsOnce sync.Once
var icons map[string]image.Image
// Concurrency-safe.
func Icon(name string) image.Image {
loadIconsOnce.Do(loadIcons)
return icons[name]
}sync.Once.Do传入一个函数,只会执行这个函数一次,sync.Once里面是一个布尔变量一个互斥变量,用来标志是否是初始化一次,与init函数类似,init是在程序加载时执行初始化,sync.Once是在需要的时候来进行初始化。
测试
测试用法
以_test.go为后缀名的源文件在执行go build时不会被构建成包的一部分,它们是go test测试的一部分,通常都是《待测试文件名_test.go》文件来进行测试,通过go test命令来执行测试文件。
测试文件必须导入testing包,测试文件中函数命名还有要求,测试函数的名字必须以Test开头,可选的后缀名必须以大写字母开头,如TestLog,测试函数的参数有三种分别是t *testing.T,*testing.B,*testing.M对应不同的测试方式。
- 运行
go test,该 package 下所有的测试用例都会被执行。 go test -v,-v参数会显示每个用例(测试函数)的测试结果-
go test -run TestAdd -v测试指定用例
子测试是 Go 语言内置支持的,可以在某个测试用例中,用法 go test -run TestMul/pos -v

帮助函数
在测试文件中处理测试函数也就是测试用例之外还可以有帮助函数,在用例中调用,辅助测试用例使用。帮助函数例子
// calc_test.go
package main
import "testing"
type calcCase struct{ A, B, Expected int }
func createMulTestCase(t *testing.T, c *calcCase) {
// t.Helper()
if ans := Mul(c.A, c.B); ans != c.Expected {
t.Fatalf("%d * %d expected %d, but %d got",
c.A, c.B, c.Expected, ans)
}
}
func TestMul(t *testing.T) {
createMulTestCase(t, &calcCase{2, 3, 6})
createMulTestCase(t, &calcCase{2, -3, -6})
createMulTestCase(t, &calcCase{2, 0, 1}) // wrong case
}代码中注释了t.Helper(),没有helper报错时报在帮助函数内不方便观察出错地方,有了t.Helper即使是帮助函数内部错误,报错显示的调用他的函数方便确定位置。
setup,teardown和TestMain
func setup() {
fmt.Println("Before all tests")
}
func teardown() {
fmt.Println("After all tests")//这俩特殊函数可用用来执行关闭网络连接,释放文件等功能
}
func Test1(t *testing.T) {
fmt.Println("I'm test1")
}
func Test2(t *testing.T) {
fmt.Println("I'm test2")
}
func TestMain(m *testing.M) {//前面提到的一种测试方式,m.Run执行所有用例,
setup()
code := m.Run()
teardown()
os.Exit(code)
}
基准测试
- 函数名必须以
Benchmark开头,后面一般跟待测试的函数名 - 参数为
b *testing.B。 - 执行基准测试时,需要添加
-bench参数。
func BenchmarkHello(b *testing.B) {
for i := 0; i < b.N; i++ {
fmt.Sprintf("hello")
}
}基准测试主要用来测试性能,测试结果结构体
type BenchmarkResult struct {
N int // 迭代次数
T time.Duration // 基准测试花费的时间
Bytes int64 // 一次迭代处理的字节数
MemAllocs uint64 // 总的分配内存的次数
MemBytes uint64 // 总的分配内存的字节数
}反射
反射主要是用于在运行时获取变量的类型信息、值信息、方法信息等等。
//反射包基本使用。
//反射基本的数据结构,Value,Type
//每一个变量对应value和type,通过反射可以生成对应的Value,Type用来操作这个变量
var a = 1
t := reflect.TypeOf(a) //返回值类型为Type类型,通过反射包里的TypeOf方法得到
var b = "hello"
t1 := reflect.ValueOf(b) //返回值类型为Value类型,通过反射包里的ValueOf方法得到
关于Value类型
- 设置值的方法:
Set*:Set、SetBool、SetBytes、SetCap、SetComplex、SetFloat、SetInt、SetLen、SetMapIndex、SetPointer、SetString、SetUint。通过这类方法,我们可以修改反射值的内容,前提是这个反射值得是合适的类型。CanSet 返回 true 才能调用这类方法- 获取值的方法:
Interface、InterfaceData、Bool、Bytes、Complex、Float、Int、String、Uint。通过这类方法,我们可以获取反射值的内容。前提是这个反射值是合适的类型,比如我们不能通过complex反射值来调用Int方法(我们可以通过Kind来判断类型)。- map 类型的方法:
MapIndex、MapKeys、MapRange、MapSet。- chan 类型的方法:
Close、Recv、Send、TryRecv、TrySend。- slice 类型的方法:
Len、Cap、Index、Slice、Slice3。- struct 类型的方法:
NumField、NumMethod、Field、FieldByIndex、FieldByName、FieldByNameFunc。- 判断是否可以设置为某一类型:
CanConvert、CanComplex、CanFloat、CanInt、CanInterface、CanUint。- 方法类型的方法:
Method、MethodByName、Call、CallSlice。- 判断值是否有效:
IsValid。- 判断值是否是
nil:IsNil。- 判断值是否是零值:
IsZero。- 判断值能否容纳下某一类型的值:
Overflow、OverflowComplex、OverflowFloat、OverflowInt、OverflowUint。- 反射值指针相关的方法:
Addr(CanAddr为true才能调用)、UnsafeAddr、Pointer、UnsafePointer。- 获取类型信息:
Type、Kind。- 获取指向元素的值:
Elem。- 类型转换:
Convert。
Len也适用于slice、array、chan、map、string类型的反射值。
关于Type类型(一个接口对象)含有常用通用的方法如下:
string()返回变量对应类型,返回myint
kind()返回底层类型,返回int
Implements(u Type)是否实现了接口u
Comparable()是否可比
Method(int) Method传入数字返回方法,通常for遍历来使用
NumMethod()变量可使用变量数量
等等
还有一些变量含有特殊的方法如果类型不对,则回报panic
ChanDir()返回通道方向,chan专用
IsVariadic()是否为可变参数,func专用
NumField() int返回包含属性数,结构体专用
Field(i int)返回第i个属性,结构体专用
FieldByIndex(index []int)StructField结构体里还是结构体,index拨开访问,结构体专用
FieldByName(name string) (StructField, bool)寻找给定名字的属性,返回是否找到
Key() Type返回map的key类型,map专用
NumIn() int返回函数参数数,func专用
NumOut() int返回值数,func专用
Len() int数组长度,数组专用
详见:深入理解 go reflect - 反射基本原理 - 掘金 (juejin.cn)
反射灵活但是耗费性能很大,bug不好找,能不用尽量不用反射。
底层编程
编写一些实实在在的应用是真理。请远离reflect和unsafe包,除非你确实需要它们。
书末尾这样写到。

















 1211
1211




 到【灌水乐园】发言
到【灌水乐园】发言







