






 本文详细介绍了程序内存布局中的栈和堆,包括它们的分配方式、特点和生命周期。在数据结构层面,阐述了栈和堆的概念,提供了栈的顺序和链式实现,并通过实例讲解了堆排序的原理。堆排序是基于堆数据结构的一种高效排序算法,通过建立大顶堆或小顶堆进行元素的交换和调整。
本文详细介绍了程序内存布局中的栈和堆,包括它们的分配方式、特点和生命周期。在数据结构层面,阐述了栈和堆的概念,提供了栈的顺序和链式实现,并通过实例讲解了堆排序的原理。堆排序是基于堆数据结构的一种高效排序算法,通过建立大顶堆或小顶堆进行元素的交换和调整。
目录
一、前言
堆(Heap)与栈(Stack)是开发人员必须面对的两个概念,在理解这两个概念时,需要放到具体的场景下,因为不同场景下,堆与栈代表不同的含义。一般情况下,有两层含义:
(1)程序内存布局场景下,堆与栈表示两种内存管理方式;
(2)数据结构场景下,堆与栈表示两种常用的数据结构。
二、程序内存布局场景下
2.1 程序内存分区中的栈
栈由操作系统自动分配释放 ,用于存放函数的参数值、局部变量等,其操作方式类似于数据结构中的栈。参考如下代码:
int main()
{
int b; //栈
char s[] = "abc"; //栈
char *p2; //栈
}其中函数中定义的局部变量按照先后定义的顺序依次压入栈中,也就是说相邻变量的地址之间不会存在其它变量。栈的内存地址生长方向与堆相反,由高到底,所以先定义的变量地址大于后定义的变量,栈中存储的数据的生命周期随着函数的执行完成而结束。
2.2 程序内存分区中的堆
堆由开发人员分配和释放, 若开发人员不释放,程序结束时由 OS 回收,分配方式类似于链表。参考如下代码:
int main()
{
// C 中用 malloc() 函数申请
char* p1 = (char *)malloc(10);
cout<<(int*)p1<<endl; //输出申请的地址
// 用 free() 函数释放
free(p1);
// C++ 中用 new 运算符申请
char* p2 = new char[10];
cout << (int*)p2 << endl; //输出:申请的地址
// 用 delete 运算符释放
delete[] p2;
}堆的内存地址生长方向与栈相反,由低到高,但需要注意的是,后申请的内存空间并不一定在先申请的内存空间的后面,即 p2 指向的地址并不一定大于 p1 所指向的内存地址,原因是先申请的内存空间一旦被释放,后申请的内存空间则会利用先前被释放的内存,从而导致先后分配的内存空间在地址上不存在先后关系。堆中存储的数据若未释放,则其生命周期等同于程序的生命周期。
三、数据结构中的堆与栈
3.1 数据结构中的栈
栈是一种运算受限的线性表,其限制是指只仅允许在表的一端进行插入和删除操作,这一端被称为栈顶(Top),相对地,把另一端称为栈底(Bottom)。把新元素放到栈顶元素的上面,使之成为新的栈顶元素称作进栈、入栈或压栈(Push);把栈顶元素删除,使其相邻的元素成为新的栈顶元素称作出栈或退栈(Pop)。这种受限的运算使栈拥有“先进后出”的特性(First In Last Out),简称 FILO。
栈分顺序栈和链式栈两种。栈是一种线性结构,所以可以使用数组或链表(单向链表、双向链表或循环链表)作为底层数据结构。使用数组实现的栈叫做顺序栈,使用链表实现的栈叫做链式栈,二者的区别是顺序栈中的元素地址连续,链式栈中的元素地址不连续[D1
]。
#include<stdio.h>
#include<malloc.h>
#define DataType int
#define MAXSIZE 1024
struct SeqStack
{
DataType data[MAXSIZE];
int top;
};
//栈初始化,成功返回栈对象指针,失败返回空指针NULL
SeqStack* initSeqStack()
{
SeqStack* s=(SeqStack*)malloc(sizeof(SeqStack));
if(s == null)
{
printf("空间不足\n");
return NULL;
}
else
{
s->top = -1;
return s;
}
}
//判断栈是否为空bool isEmptySeqStack(SeqStack* s)
{
if (s->top == -1)
return true;
else
return false;
}
//入栈,返回-1失败,0成功
int pushSeqStack(SeqStack* s, DataType x)
{
if(s->top == MAXSIZE-1)
{
return -1;
//栈满不能入栈
}
else
{
s->top++;
s->data[s->top] = x;
return 0;
}
}
//出栈,返回-1失败,0成功
int popSeqStack(SeqStack* s, DataType* x)
{
if(isEmptySeqStack(s))
{
return -1;//栈空不能出栈
}
else
{
*x = s->data[s->top];
s->top--;
return 0;
}
}
//取栈顶元素,返回-1失败,0成功
int topSeqStack(SeqStack* s,DataType* x)
{
if (isEmptySeqStack(s))
return -1; //栈空
else
{
*x=s->data[s->top];
return 0;
}
}
//打印栈中元素
int printSeqStack(SeqStack* s)
{
int i;
printf("当前栈中的元素:\n");
for (i = s->top; i >= 0; i--)
printf("%4d",s->data[i]);
printf("\n");
return 0;
}
//test
int main()
{
SeqStack* seqStack=initSeqStack();
if(seqStack)
{
//将4、5、7分别入栈
pushSeqStack(seqStack,4);
pushSeqStack(seqStack,5);
pushSeqStack(seqStack,7);
//打印栈内所有元素
printSeqStack(seqStack);
//获取栈顶元素
DataType x=0;
int ret=topSeqStack(seqStack,&x);
if(0==ret)
{
printf("top element is %d\n",x);
}
//将栈顶元素出栈
ret=popSeqStack(seqStack,&x);
if(0==ret)
{
printf("pop top element is %d\n",x);
}
}
return 0;
}
3.2 数据结构中的堆
堆是一种常用的树形结构,是一种特殊的完全二叉树,当且仅当满足所有节点的值总是不大于或不小于其父节点的值的完全二叉树被称之为堆。堆的这一特性称之为堆序性。因此,在一个堆中,根节点是最大(或最小)节点。如果根节点最小,称之为小顶堆(或小根堆),如果根节点最大,称之为大顶堆(或大根堆)。堆的左右孩子没有大小的顺序。
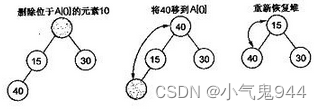
3.3 堆的具体应用——堆排序
堆排序(Heapsort)是堆的一个经典应用,有了上面对堆的了解,不难实现堆排序。由于堆也是用数组来存储的,故对数组进行堆化后,第一次将A[0]与A[n - 1]交换,再对A[0…n-2]重新恢复堆。
(1)稳定性。堆排序是不稳定排序。
// array:待排序数组,len:数组长度
void heapSort(int array[],int len)
{
// 建堆
makeMinHeap(array,len);
// 最后一个叶子节点和根节点交换,并进行堆调整,交换次数为len-1次
for(int i=len-1;i>0;--i)
{
//最后一个叶子节点交换
array[i]=array[i]+array[0];
array[0]=array[i]-array[0];
array[i]=array[i]-array[0];
// 堆调整
minHeapFixDown(array, 0, len-i-1);
}
}[D1]其实我们的顺序表的地址就是连续的,而链式表的地址是不连续的


















 5571
5571

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











