






作用:
文件导入,读取文件中的图片。
如图: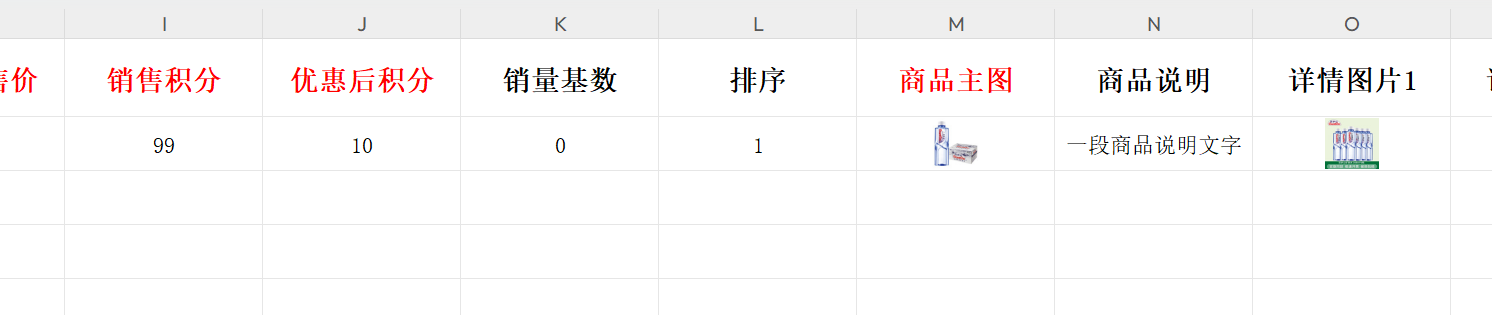
jdk17版本代码
主要功能方法: (方法中会有冗余部分,考虑性能的可以自己微调一下)
public void importLoaclExcel(List<BookStackImportLocalExcelVO> list,
MultipartFile file) {
try (InputStream inputStream = file.getInputStream()) {
// InputStream inputStream = file.getInputStream();
// 将文件内容读取到字节数组中
byte[] fileBytes = inputStream.readAllBytes();
// 使用 ByteArrayInputStream 读取ZIP文件中的图片
Map<String, byte[]> cellImageMap = new HashMap<>();
Map<String, String> relsMap = new HashMap<>();
Map<String, byte[]> imagesData = new HashMap<>();
ByteArrayOutputStream baos = null;
String sheetXml = null;
String cellImagesXml = null;
String cellImagesRelsXml = null;
ZipEntry zipEntry;
try (ZipInputStream zis = new ZipInputStream(new ByteArrayInputStream(fileBytes))) {
while ((zipEntry = zis.getNextEntry()) != null) {
String entryName = zipEntry.getName();
if ("xl/cellimages.xml".equals(entryName)) {
baos = new ByteArrayOutputStream();
IOUtils.copy(zis, baos);
cellImagesXml = baos.toString("UTF-8");
baos.close();
} else if ("xl/_rels/cellimages.xml.rels".equals(entryName)) {
baos = new ByteArrayOutputStream();
IOUtils.copy(zis, baos);
cellImagesRelsXml = baos.toString("UTF-8");
baos.close();
} else if (entryName.startsWith("xl/media/")) {
byte[] imageBytes = IOUtils.toByteArray(zis);
String imageName = entryName.substring("xl/media/".length());
imagesData.put(imageName, imageBytes);
}
zis.closeEntry();
}
zis.close();
}
if (cellImagesRelsXml != null) {
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
Document relsDoc = builder.parse(new ByteArrayInputStream(cellImagesRelsXml.getBytes("UTF-8")));
NodeList relNodes = relsDoc.getElementsByTagName("Relationship");
for (int i = 0; i < relNodes.getLength(); i++) {
Element relElement = (Element) relNodes.item(i);
String rId = relElement.getAttribute("Id");
// e.g., "media/image1.png"
String target = relElement.getAttribute("Target");
if (target.startsWith("media/")) {
relsMap.put(rId, target.substring("media/".length()));
} else {
// 处理不符合预期的情况,例如记录日志或跳过该条目
relsMap.put(rId, null);
}
}
}
// 解析cellimages.xml,提取图片与单元格的关系
if (cellImagesXml != null) {
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
Document cellImagesDoc = builder.parse(new ByteArrayInputStream(cellImagesXml.getBytes("UTF-8")));
NodeList cellImageNodes = cellImagesDoc.getElementsByTagName("etc:cellImage");
for (int i = 0; i < cellImageNodes.getLength(); i++) {
Element cellImageElement = (Element) cellImageNodes.item(i);
// 获取图片 name 属性,如 "ID_6C483737A6AC427DAA4E4974252FB8A8"
Element picElement = (Element) cellImageElement.getElementsByTagName("xdr:pic").item(0);
Element cNvPr = (Element) picElement.getElementsByTagName("xdr:cNvPr").item(0);
// e.g., "ID_6C483737A6AC427DAA4E4974252FB8A8"
String imageName = cNvPr.getAttribute("name");
// 获取 r:embed 属性,如 "rId1"
Element blipFill = (Element) picElement.getElementsByTagName("xdr:blipFill").item(0);
Element blip = (Element) blipFill.getElementsByTagName("a:blip").item(0);
// e.g., "rId1"
String rId = blip.getAttribute("r:embed");
// e.g., "image1.png"
String imageFileName = relsMap.get(rId);
if (StringUtils.isEmpty(imageFileName)) {
cellImageMap.put(imageName, null);
continue;
}
// 保存图片到本地
byte[] imageBytes = imagesData.get(imageFileName);
cellImageMap.put(imageName, imageBytes);
}
}
for (int i = 0; i < list.size(); i++) {
BookStackImportLocalExcelVO item = list.get(i);
try {
//开始匹配图片和数据
if (StringUtils.isNotBlank(list.get(i).getBookCover())) {
byte[] imageByCellValue = cellImageMap.getOrDefault(extractContentInQuotes(list.get(i).getBookCover()), null);
// imageByCellValue 就是拿到的图片的字节信息,之后就可以执行自己需要的操作了
}
} catch (Exception e) {
log.error("本地导入数据异常:" + e.getMessage());
}
}
} catch (Exception e) {
log.error("导入任务异常:" + e.getMessage());
}
}
public static String extractContentInQuotes(String input) {
// 定义正则表达式,用于匹配双引号内的内容
String regex = "\"([^\"]*)\"";
Pattern pattern = Pattern.compile(regex);
Matcher matcher = pattern.matcher(input);
// 查找匹配的内容
if (matcher.find()) {
return matcher.group(1);
}
return null; // 如果没有找到匹配的内容,返回 null
}
相关的实体对象
@Data
@Builder
@AllArgsConstructor
@NoArgsConstructor
@HeadRowHeight(24)
@ContentRowHeight(24)
@Accessors(chain = false) // 设置 chain = false,避免用户导入有问题
@ExcelIgnoreUnannotated
public class BookStackImportLocalExcelVO {
@ColumnWidth(30)
@ExcelProperty(value = "ISBN编码", index = 0)
private String isbn;
@ColumnWidth(30)
@ExcelProperty(value = "书名", index = 1)
private String title;
@ColumnWidth(30)
@ExcelProperty(value = "封面", index = 2)
private String bookCover;
@ColumnWidth(30)
@ExcelProperty(value = "作者", index = 3)
private String author;
@ColumnWidth(30)
@ExcelProperty(value = "装帧", index = 4)
private String binding;
@ColumnWidth(30)
@ExcelProperty(value = "出版社", index = 5)
private String publisher;
@ColumnWidth(30)
@ExcelProperty(value = "出版日期", index = 6)
private String publishDate;
@ColumnWidth(30)
@ExcelProperty(value = "简介", index = 7)
private String introduction;
private String resultInfo;
}
jdk8版本代码
把17版本的方法贴过去 ,会有下面一行代码报错
// jdk8中 没有 readAllBytes方法
byte[] fileBytes = inputStream.readAllBytes();
// 改造成
byte[] fileBytes = toByteArray(inputStream);
public static byte[] toByteArray(InputStream inputStream) throws IOException {
ByteArrayOutputStream buffer = new ByteArrayOutputStream();
byte[] data = new byte[1024];
int bytesRead;
while ((bytesRead = inputStream.read(data, 0, data.length)) != -1) {
buffer.write(data, 0, bytesRead);
}
buffer.flush();
return buffer.toByteArray();
}

















 3245
3245

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









