







文章目录

论文标题:PokeMQA:可编程知识编辑的多跳问题回答
论文链接:https://arxiv.org/abs/2312.15194
arXiv:2312.15194v2 [cs.CL] 15 Feb 2024
摘要
多跳问答(MQA)是评估机器理解和推理能力的具有挑战性的任务之一,其中大型语言模型(LLM)已广泛达到与人类相当的性能。由于现实世界中知识事实的动态性,人们已经开始探索在避免昂贵的重新训练或微调的同时,使用知识编辑来更新模型以获取最新的事实。从编辑后的事实开始,更新后的模型需要在MQA链中提供级联变化。以前的艺术品只是采用了一个混合提示来指导LLMs(大型语言模型)顺序执行多个推理任务,包括问题分解、答案生成和通过与编辑过的事实进行比较的冲突检查。然而,这些功能各异的推理任务之间的耦合抑制了LLMs在理解并回答问题方面的优势,同时干扰了它们不擅长的任务——冲突检查。因此,我们提出了一种框架,名为可编程知识编辑的多跳问题回答(PokeMQA),以解耦这些任务。具体来说,我们提示LLMs(大型语言模型)对知识增强型多跳问题进行分解,同时与分离的可训练范围检测器交互,根据外部冲突信号调节LLMs的行为。在三个大型语言模型(LLM)的实验中和两个基准数据集上,我们验证了在多问题回答(MQA)的知识编辑方面我们的优越性。在几乎所有设置中,我们都以很大优势超过了所有竞争对手,并始终产生可靠的推理过程。我们的代码可以在https://github.com/Hengrui-Gu/PokeMQA上找到。
1 简介
多跳问题回答(MQA)需要一系列交互的知识事实来得出中间答案Inter Miami,通过事实“梅西为Inter Miami效力”,然后通过另一个事实“Inter Miami位于北美”推断出最终答案NA。例如,考虑图1中的两跳问题,有必要通过其他事实推断出最终答案。MQA对问答系统的推理能力提出了巨大挑战(Mavi等人,2022年;Chen等人,2019年;Lan等人,2021年)。得益于大规模预训练带来的自然语言理解和推理能力,大型语言模型(LLMs)在MQA任务中证明了其不可或缺的实用性(Rao等人,2022年;Khalifa等人,2023年;Xu等人,2023年;Chen等人,2022年)。
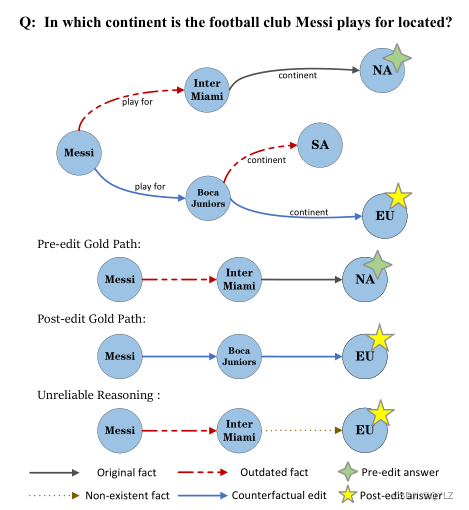
图1:知识编辑下多跳问题回答的一个示例,包括相关知识事实和解决两跳问题的三条具体推理路径。对于不可靠的推理,它使用了一个过时的事实和一个不存在的事实,最后得到了正确的答案欧洲。
然而,LLMs中的知识可能在事实上有误或随着时间的推移变得无效。为了确保LLMs的正确性而不必进行昂贵的重新训练(Liu等人,2023),已经开展了知识编辑技术,以提供模型行为的高效和有针对性的更新(Sinitsin等人,2020,Zhu等人,2020,De Cao等人,2021)。这段文字介绍了两种流行的方法:参数修改型编辑和基于记忆的编辑。前者通过元学习、微调或知识定位来根据已编辑的事实修改内部模型权重(Meng等,2022a,Mitchell等,2021,Meng等,2022b)。后一种方法利用外部存储器显式地存储编辑的事实(或称为编辑),并对其进行推理,同时保持LLMs参数不变(Mitchell等人,2022;Zheng等人,2023a)。由于其简单性和对背骨LLMs的普遍适用性,记忆型模型编辑通常被采用。
在MQA的背景下,MeLLo(Zhong等人,2023)首先通过设计一个多功能提示来指导LLMs进行问题分解和知识编辑的推理任务。特别是,在分解多跳问题后,LLMs为每个子问题生成一个暂时的答案,然后检测暂时答案和记忆中编辑过的事实之间是否存在事实冲突(例如,“现任英国首相是拉什·苏纳克”和“现任英国首相是利兹·特拉斯”的陈述是彼此不相容的事实)。通过反复提示LLMs,MeLLo达到了多跳问题的答案。
然而,问题分解和知识编辑的结合对LLMs在上下文中精确进行推理演示提出了相当高的要求。首先,知识编辑需要LLMs完全理解两个候选事实的语义,然后基于它们之间的事实兼容性进行冲突检测。在少量样本提示下,大型语言模型由于监督信号不足而容易对编辑逻辑进行欠拟合,尤其当其被嵌入到更复杂的任务中时(例如问题分解),即在统一的提示中,知识编辑指令的引入会以类似的方式为问题分解带来噪声。这种叠加的噪音阻止LLMs(大型语言模型)完全专注于解析多跳问题的语法结构,以精确地识别子问题。
因此,我们提出了可编程知识编辑的多跳问题回答(PokeMQA),在此方案中,我们将两个关键任务(即问题分解和知识编辑)解耦,以减轻LLMs的负担,同时引入辅助知识提示来帮助问题分解。具体来说,我们通过可编程的范围检测器卸载知识编辑中的冲突检测,该检测器用于检测子问题是否在语义空间中任何已编辑事实的影响范围内(挑战#1)。设计了一个两阶段范围检测器:在预检测阶段,我们有效地过滤掉大量无关的编辑;在冲突消歧阶段,我们在剩余的少数候选编辑上进行精确检索。我们的两阶段框架在实际场景中考虑到大量编辑过的事实,提供了计算效率和表现力。检索到的编辑被用来校准LLMs行为。 此外,我们提出了一种知识提示来增强在问题分解过程中的解析分析(挑战#2)。知识提示从输入问题中识别关键实体,并从知识源中检索其外部信息以触发正确的分解。
此外,我们发现多跳问题回答过程可能会使用过时的或不存在的事实,但有时最终会得出正确的答案。我们将这种情况称为不可靠的推理(如图1所示)。为了准确地评估模型的推理能力,我们提出了一种新的度量标准,称为逐跳回答准确率(Hop-Acc),衡量大语言模型遵循示例、逐步分解问题以及为解决多步问题生成所需答案的程度。
2 在知识编辑下的多跳问题回答
根据之前的研究(Zhong等人,2023;Meng等人,2022a),我们把一个事实表示为一个三元组(s, r, o),包括主体s、客体o以及它们之间的关系r,例如(梅西,效力于,国际迈阿密队)。编辑过的事实(即,编辑)是我们想要更新的知识事实,并以相同的形式表示(s、r、o),例如(梅西,效力于,博卡青年队)。我们考虑一个多跳问题Q,回答Q需要顺序查询和检索多个事实。这些事实按照查询的顺序呈现,形成一个事实链⟨(s1, r1, o1) , . . . , (sn, rn, on)⟩,其中si+1 = oi并且on是最终答案,它唯一地表示一个实体间路径P = ⟨s1, o1, . . . , on⟩。应该注意的是,除了s1之外,P中的所有其他实体o1、…、on在Q中都没有出现,需要通过事实推理(像图1中的多跳问题中的Inter Miami和North America)显式或隐式地推断出来。如果我们用编辑e=(si, ri, o i ∗ {o^*_i} oi∗)替换掉无效的事实(si, ri, oi),在一个多跳问题中,由于编辑事实导致的级联效应,事实链相应地改变为<(s1, r1, o1), …, (si, ri, o i ∗ {o^*_i} oi∗), …, ( s n ∗ {s^*_n}
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









