







文章目录

论文标题:高效地通过平衡主题感知采样教授有效的密集检索器
论文链接:https://arxiv.org/abs/2104.06967
arXiv:2104.06967v2 [cs.IR] 26 May 2021
摘要
关键步骤是广泛采用神经检索模型的资源效率,包括在整个训练、索引和查询工作流程中。最近,神经信息检索社区在训练有效的双编码器密集检索(DR)模型方面取得了巨大进步。密集文本检索模型使用每个查询和段落的单个向量表示来评分匹配,这使得通过最近邻搜索实现低延迟的一阶段检索。越来越普遍的是,训练方法需要巨大的计算能力,因为它们要么在不断更新刷新索引中进行负面段落采样,要么需要非常大的批量大小。为了不依赖更多的计算能力,我们引入了一种有效的主题感知查询和平衡边缘采样技术,称为TAS-Balanced。我们在训练前对查询进行一次聚类,并在每个批次中从一个集群中采样查询。我们使用一种新颖的双教师监督来训练我们的轻量级6层DR模型,该监督结合了成对和批量内的负教师。我们的方法可以在48小时内使用单个消费级GPU进行训练。我们证明,我们的TAS-Balanced训练方法在两个TREC深度学习查询集上实现了最先进的低延迟(每个查询64毫秒)结果。在NDCG@10的评估指标上,我们比BM25提高了44%,比简单训练的DR提高了19%,比docT5query提高了11%,比之前的最佳DR模型提高了5%。此外,TAS-Balanced实现了第一个在TREC-DL上以任何截止点的召回率超过所有其他方法的密集检索器,并允许更耗资源的重排序模型在较少的段落上操作以进一步提高结果。
CCS 概念
• 信息系统 → 学习排序;
关键词
密集检索;知识蒸馏;批量采样
1 介绍
在生活中拥有一位准备充分的老师可以使学习变得更加轻松和高效。通过更有经验和能力的教师模型来训练密集文本检索模型,也是遵循同样的道路。密集检索模型(如基于BERT的[10]双编码器BERTDOT)具有低延迟查询时间的巨大潜力,其准确性和召回率远超传统的第一阶段检索方法,并将大部分计算成本转移到离线索引和训练中。统一的BERTDOT架构已经得到了许多开源搜索引擎的支持。BERTDOT可以作为独立的检索器使用,也可以作为重排流程的一部分。在进一步提高结果质量时,问题变成了硬件资源的成本和训练及索引的要求。最近一种改进检索结果质量的趋势是增强BERTDOT训练过程,这导致对硬件需求的增加。这种趋势的例子包括从不断更新的刷新索引中进行负向段落采样(ANCE[42])、模型生成(LTRe[44])或需要大批次(RocketQA[11])。
一个并发的研究方向是利用知识蒸馏从更有效但不那么高效的架构中作为教师,这可以在成对[14, 16, 25]或批量内负样本[24]设置中实现。批量内负样本重用了每个样本的编码表示,并计算了批量内所有样本之间的交互。我们将这两种知识蒸馏范式结合到一个新颖的双重监督中,使用对批处理中的负样本进行逐对连接的BERTCAT和ColBERT教师。这些方法虽然已经表现良好,但受到单个随机批次所能提供给训练的信息增益的限制。密集检索训练可用的训练数据包括一个查询池,通常与每个查询相关联的是一个带有教师评分差别的段落对集。每个对由一个相关和非相关的段落组成,差值由减去非相关抽样段落的教师评分和相关段落的教师评分来设置。
本文的主要贡献是改进对对和批量教师信号。我们提出了平衡主题感知采样(TAS-Balanced)来组成密集检索训练批处理。这种采样技术包括两个部分:(1)我们根据聚类在主题中的查询来组成批次(TAS);(2)然后选择段落对,以便平衡对对教师得分差值(TAS-Balanced)。我们根据语义点积相似性的基线表示,在训练之前对主题进行一次聚类(这允许在没有词汇重叠的情况下分组查询) - 所有40万个MSMARCO训练查询的总时间成本不到10分钟。图1显示了一个示例的主题聚类选择。此前,一个批次中包含来自训练集的随机查询,为批量内的负样本提供的信息增益很少。通过从单个聚类中选择查询,我们将关于某个主题的信息集中在同一个批次中,经过批量内负样本教学后,可以提高检索结果的质量。
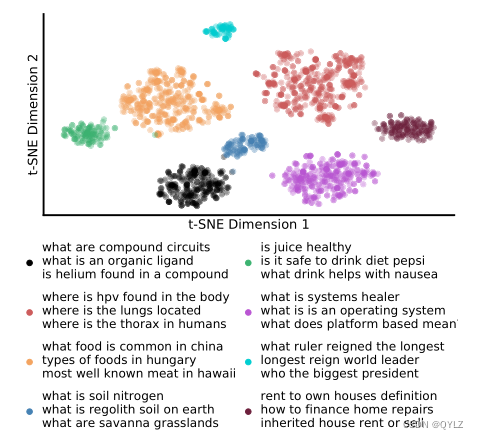
图1:8个随机采样主题聚类的T-SNE图和示例查询。我们的主题感知采样(TAS)在每个批次中从单个集群中组成查询。
我们证明了通过TAS-Balanced批次和双重监督,我们可以在单个消费级(11GB内存)GPU上在48小时内训练出一个非常有效的密集检索模型,而不是常见的8x V100配置,因为我们的方法不依赖于重复索引[42]或大批次训练[11]。具体而言,我们研究以下研究问题:
RQ1 在单教师和双教师监督下,TAS和TAS-Balanced批处理采样技术的效果如何?
我们发现TAS在单独的批内负样本教学以及我们的双监督教师中都有所提高。TAS-平衡采样改进了对偶训练、批内负样本和双监督训练,这代表了在我们的三个查询集中最好的整体配置。双教师监督对使用Margin-MSE损失的召回率有特别大的积极影响。我们研究了不同的双重监督损失,并发现Margin-MSE在其他损失函数上始终提高了结果。
机器学习研究中的一个常见问题是无意间在特定的超参数组合、随机种子和集合上过拟合。为了对我们的结果有信心,我们研究了以下问题:
RQ2:TAS-Balanced方法对于不同的随机化处理有多稳健?
为了证明TAS-Balanced对随机过拟合具有鲁棒性,我们对5个实例进行了随机化研究,这些实例具有不同的所选聚类和查询的随机顺序。我们发现,在我们的查询集的指标中,标准偏差很小(TREC-DL上的nDCG变化小于0.01;MSMARCO-DEV上的MRR变化小于0.001)。这使我们对我们的技术的有效性和鲁棒性充满信心。为了将我们的研究结果与相关工作联系起来,我们回答:
RQ3:我们的TAS-Balanced方法与其他密集检索训练方法相比如何?
我们使用两个TREC-DL(2019和2020)查询集以及MSMARCO-DEV集对我们的模型进行评估,其中使用了MSMARCO的段落集合。这两个TREC集特别适合研究密集检索器的召回质量,因为每个查询都有数百个经过评判的段落。 我们的TAS平衡和双监督训练的BERTDOT模型在TREC-DL’19和’20查询集上表现出最先进的低延迟结果,使用批处理大小仅为32。我们的BERTDOT模型在NDCG@10的评估中,比BM25提高了44%,比简单训练的DR提高了19%,比docT5query提高了11%,比之前的最佳DR模型提高了5%。在稀疏标注的MSMARCO-DEV查询上,TAS-Balanced表现出最好的结果,适用于使用单个消费级GPU的方法,并且超过了大多数需要20倍更多资源来训练的方法。最后,尽管TAS-Balanced是一个有效的独立低延迟检索器,我们还研究了我们TAS训练模型在一个更大搜索系统中的影响。
RQ4:我们的TAS训练的密集检索器作为第一阶段模块在召回率和重新排序增益方面有多适合?
我们发现,TAS-Balanced在BERTDOT模型中取得了第一个在所有召回截止点上持续超过BM25和docT5query的成果。与docT5query结果融合后,我们在召回方面看到了另一个增长,表明在已经较高的召回水平下,密集和稀疏解决方案仍然可以相互受益。此外,我们还将最先进的重新排名系统mono-duo-T5叠加在我们的第一阶段检索上。由于经过TAS训练的BERTDOT可以提高小截止值的召回率和准确度,我们可以减少昂贵的重新排名系统处理的段落数量,同时仍然获得相当大的好处。然而,我们还发现了一个局限性:在更高的截止值下,质量的重新排序有所限制。尽管TAS-Balanced继续提高更高截止值下的召回率,但重新排序并没有利用这一点。未来的工作可能会在TAS-Balanced的基础上改进重新排名器。
本工作的目的是实现一个非常有效的BERTDOT检索模型,并尽量减少所需的训练资源。我们的贡献如下:
- 我们提出了一种高效的基于主题感知采样的信息密集型检索训练批处理方法(TAS-Balanced)
- 我们证明,在与双教师监督相结合的情况下,TAS-Balanced 在 TREC-DL 上实现了最先进的密集检索结果
- 我们研究了我们的训练鲁棒性以及 TAS-Balanced 如何改进更大的(重新)排名系统
- 我们的源代码已发布在以下网址: https://git
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









