







文章目录

论文题目:通过阅读实体描述实现零样本实体链接
论文链接:https://arxiv.org/abs/1906.07348
arXiv:1906.07348v1 [cs.CL] 18 Jun 2019
摘要
我们提出了 "零镜头实体链接 "任务,即必须在没有域内标注数据的情况下将提及链接到未知实体。该任务的目标是将实体稳健地转移到高度专业化的领域,因此不假定有元数据或别名表。在这种情况下,实体只能通过文本描述来识别,模型必须严格依赖语言理解来解析新实体。首先,我们证明了在大量未标记数据上预先训练的强大阅读理解模型可用于泛化未见实体。其次,我们提出了一种简单有效的自适应预训练策略(我们称之为领域自适应预训练(DAP)),以解决与在新领域中链接未见实体相关的领域转移问题。我们介绍了在我们为这项任务构建的新数据集上进行的实验,结果表明 DAP 比包括 BERT 在内的强大预训练基线更有优势。数据和代码可在 https://github.com/lajanugen/zeshel。
1 介绍
当目标实体词典中存在大量可用于训练的实体消歧提及时,实体链接系统就会取得很高的性能。这类系统通常使用强大的资源,如高覆盖率的别名表、结构化数据和链接频率统计。例如,Milne 和 Witten(2008 年)的研究表明,仅使用从维基百科训练文章的超链接统计中收集到的先验概率,就能使维基百科测试文章中链接预测任务的准确率达到 90%。
虽然之前的大多数工作都集中在与一般实体数据库的链接上,但人们往往希望与专业实体词典进行链接,例如法律案例、公司项目描述、小说中的人物集或术语词汇表。遗憾的是,这些专业实体词典的标注数据并不容易获得,而且获取成本往往很高。因此,我们需要开发能够泛化到未见过的专门实体的实体链接系统。如果没有频率统计和元数据,这项任务就会变得更具挑战性。之前的一些研究已经指出了构建可泛化到未见实体集的实体链接系统的重要性(Sil 等人,2012 年;Wang 等人,2015 年),但采用了一套额外的假设。
在这项工作中,我们提出了一种新的零镜头实体链接任务,并为此构建了一个新的数据集。目标字典被简单地定义为一组实体,每个实体都有文字描述(例如,来自实体规范页面)。与之前的一些工作不同,我们并不限制提及的实体必须是已命名的实体,因为这将导致大量候选实体的出现,从而增加任务的难度。在我们的数据集中,有多个实体词典可用于训练,而任务性能则是在一组没有标注数据的测试实体词典上测量的。图 1 展示了任务设置。我们使用 Wikia 中的多个子域构建数据集,并使用超链接自动提取有标签的提及内容。
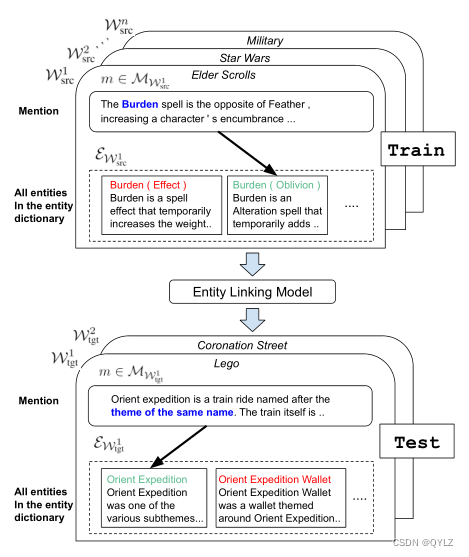
图 1:零镜头实体链接。图中显示了多个训练域和测试域(世界)。该任务有两个关键特性:(1) 它是零镜头任务,因为在训练过程中没有观察到任何测试世界实体被提及。(2) 只有文本(非结构化)信息可用。
零镜头实体链接对实体链接模型提出了两个挑战。首先,在没有强大的别名表或频率先验的情况下,模型必须阅读实体描述,并推理与上下文中提及内容的对应关系。我们的研究表明,一个强大的阅读理解模型至关重要。其次,由于没有测试实体的标注提及,模型必须适应新的提及上下文和实体描述。我们将重点关注这两个挑战。
本文的贡献如下:
- 我们提出了一项新的零镜头实体链接任务,旨在以最少的假设挑战实体链接系统的泛化能力。我们为这项任务构建了一个数据集,该数据集将公开发布。
- 我们利用最先进的阅读理解模型建立了一个强大的基线。我们的研究表明,对上下文中的提及和实体描述之间的关注对于这项任务至关重要,而在之前的实体链接工作中并未使用过这种关注。
- 我们提出了一种简单而新颖的适应策略,称为领域适应性预训练(DAP),并证明它能进一步提高实体链接性能。
2 零点实体链接
我们首先回顾了标准实体链接任务定义,并讨论了先前系统的假设。然后,我们定义了零镜头实体链接任务,并讨论了它与之前工作的关系。
2.1 审查: 实体链接
实体链接(Entity linking,EL)是通过将实体提及与给定的实体数据库或字典中的条目链接起来,从而实现实体提及的基础化。从形式上看,给定一个提及 m 及其上下文,实体链接系统会将 m 链接到实体集 E = {ei}i=1,…,K 中的相应实体,其中 K 是实体的数量。EL 的标准定义(Bunescu 和 Pasca,2006;Roth 等人,2014;Sil 等人,2018)假定提及边界由用户或提及检测系统提供。实体集 E 可能包含数万甚至数百万个实体,因此这是一项具有挑战性的任务。实际上,许多实体链接系统都依赖于以下资源或假设:
单一实体集 假定在训练和测试示例中共享一个单一的实体集 E。
别名表 别名表包含给定提及字符串的候选实体,并将可能性限制在相对较小的范围内。这种表通常是根据标注的训练集和特定领域的启发式方法编制而成的。
频率统计 许多系统使用从大型标注语料库中获得的频率统计来估算实体的流行度以及某个提及字符串与某个实体建立链接的概率。这些统计数据在可用时非常强大。
结构化数据 有些系统假定可以访问结构化数据,如关系元组(如(巴拉克-奥巴马、配偶、米歇尔-奥巴马))或类型层次结构,以帮助消歧。
2.2 任务定义
这项任务的主要动机是扩大实体链接系统的范围,并使其具有泛化能力,适用于未见过的实体集。因此,我们放弃了上述假设,只做一个弱假设:存在一个实体字典E = {(ei, di)}i=1,…,K,其中di是实体ei的文本描述。
我们的目标是构建能够泛化到新领域和实体字典(我们称之为世界)的实体链接系统。我们定义一个世界为W =(MW,UW,EW),其中MW和UW分别是来自该世界的提及和文档的概率分布,而EW是与W
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4168
4168

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









