








Paxos算法
Paxos 算法是基于消息传递且具有高度容错特性的一致性算法,是目前公认的解决分布式一致性问题最有效的算法之一,其解决的问题就是在分布式系统中如何就某个值(决议)达成一致 。
在 Paxos 中主要有三个角色,分别为 Proposer提案者、Acceptor表决者、Learner学习者。Paxos 算法和 2PC 一样,也有两个阶段,分别为 Prepare 和 accept 阶段。
prepare 阶段
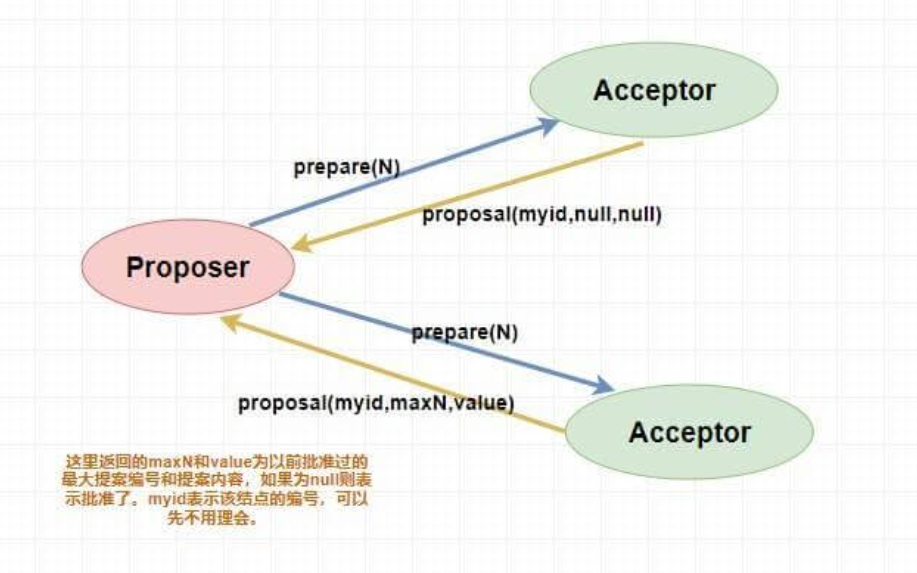
Proposer提案者:负责提出 proposal,每个提案者在提出提案时都会首先获取到一个 具有全局唯一性的、递增的提案编号 N,即在整个集群中是唯一的编号 N,然后将该编号赋予其要提出的提案,在第一阶段是只将提案编号发送给所有的表决者。
Acceptor表决者:每个表决者在 accept 某提案后,会将该提案编号 N 记录在本地,这样每个表决者中保存的已经被 accept 的提案中会存在一个编号最大的提案,其编号假设为 maxN。每个表决者仅会 accept 编号大于自己本地 maxN 的提案,在批准提案时表决者会将以前接受过的最大编号的提案作为响应反馈给 Proposer。
accept 阶段
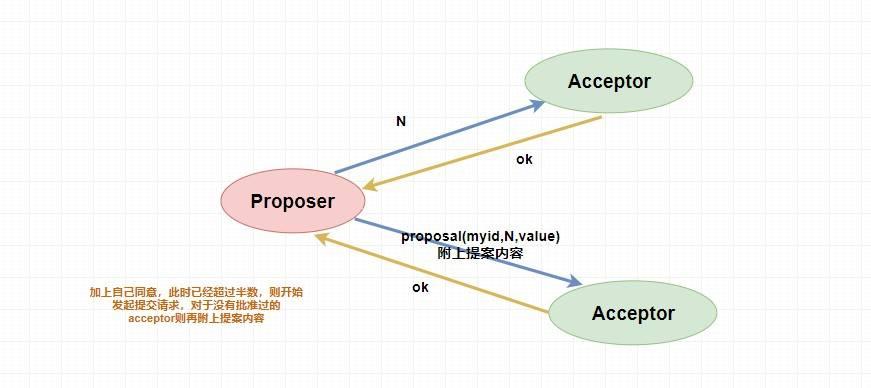
当一个提案被 Proposer 提出后,如果 Proposer 收到了超过半数的 Acceptor 的批准(Proposer 本身同意),那么此时 Proposer 会给所有的 Acceptor 发送真正的提案(可以理解成第一阶段为试探),这个时候 Proposer 就会发送提案的内容和提案编号。
表决者收到提案请求后会再次比较本身已经批准过的最大提案编号和该提案编号,如果该提案编号 大于等于 已经批准过的最大提案编号,那么就 accept 该提案(此时执行提案内容但不提交),随后将情况返回给 Proposer 。如果不满足则不回应或者返回 NO 。

当 Proposer 收到超过半数的 accept ,那么它这个时候会向所有的 acceptor 发送提案的提交请求。需要注意的是,因为上述仅仅是超过半数的 acceptor 批准执行了该提案内容,其他没有批准的并没有执行该提案内容,所以这个时候需要向未批准的 acceptor 发送提案内容和提案编号并让它无条件执行和提交,而对于前面已经批准过该提案的 acceptor 来说 仅仅需要发送该提案的编号 ,让 acceptor 执行提交就行了。
而如果 Proposer 如果没有收到超过半数的 accept 那么它将会将 递增 该 Proposal 的编号,然后 重新进入 Prepare 阶段 。
paxos 算法的死循环问题
比如说,此时提案者 P1 提出一个方案 M1,完成了 Prepare 阶段的工作,这个时候 acceptor 则批准了 M1,但是此时提案者 P2 同时也提出了一个方案 M2,它也完成了 Prepare 阶段的工作。然后 P1 的方案已经不能在第二阶段被批准了(因为 acceptor 已经批准了比 M1 更大的 M2),所以 P1 自增方案变为 M3 重新进入 Prepare 阶段,然后 acceptor ,又批准了新的 M3 方案,它又不能批准 M2 了,这个时候 M2 又自增进入 Prepare 阶段。
就这样无休无止的永远提案下去,这就是 paxos 算法的死循环问题。
ZAB协议
ZAB(ZooKeeper Atomic Broadcast 原子广播) 协议是为分布式协调服务 ZooKeeper 专门设计的一种支持崩溃恢复的原子广播协议。 在 ZooKeeper 中,主要依赖 ZAB 协议来实现分布式数据一致性,基于该协议,ZooKeeper 实现了一种主备模式的系统架构来保持集群中各个副本之间的数据一致性。
ZAB 协议两种基本的模式:崩溃恢复和消息广播
崩溃恢复:当整个服务框架在启动过程中,或是当 Leader 服务器出现网络中断、崩溃退出与重启等异常情况时,ZAB 协议就会进入恢复模式并选举产生新的 Leader 服务器。当选举产生了新的 Leader 服务器,同时集群中已经有过半的机器与该 Leader 服务器完成了状态同步之后,ZAB 协议就会退出恢复模式。其中,所谓的状态同步是指数据同步,用来保证集群中存在过半的机器能够和 Leader 服务器的数据状态保持一致。
消息广播:当集群中已经有过半的 Follower 服务器完成了和 Leader 服务器的状态同步,那么整个服务框架就可以进入消息广播模式了。 当一台同样遵守 ZAB 协议的服务器启动后加入到集群中时,如果此时集群中已经存在一个 Leader 服务器在负责进行消息广播,那么新加入的服务器就会自觉地进入数据恢复模式:找到 Leader 所在的服务器,并与其进行数据同步,然后一起参与到消息广播流程中去。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









