






 本文详细介绍了Spark SQL中数据的加载和保存方法,包括通用的加载和保存API,如`spark.read.load`和`df.write.save`,以及特定格式如Parquet和JSON的处理。文中还提到了Parquet作为默认数据源的优势,以及如何加载和保存JSON文件。此外,还讨论了Spark SQL如何处理JDBC数据以及SaveMode的使用。
本文详细介绍了Spark SQL中数据的加载和保存方法,包括通用的加载和保存API,如`spark.read.load`和`df.write.save`,以及特定格式如Parquet和JSON的处理。文中还提到了Parquet作为默认数据源的优势,以及如何加载和保存JSON文件。此外,还讨论了Spark SQL如何处理JDBC数据以及SaveMode的使用。
一 、Spark 数据的加载和保存
(一)通用的加载和保存方式
SparkSQL 提供了通用的保存数据和数据加载的方式。这里的通用指的是使用相同的
API,根据不同的参数读取和保存不同格式的数据,SparkSQL 默认读取和保存的文件格式
为 parquet
1、加载数据
spark.read.load 是加载数据的通用方法

- 如果读取不同格式的数据,可以对不同的数据格式进行设定
scala> spark.read.format("…")[.option("…")].load("…") format(“…”):指定加载的数据类型,包括"csv"、“jdbc”、“json”、“orc”、"parquet"和
“textFile”。
load(“…”):在"csv"、“jdbc”、“json”、“orc”、"parquet"和"textFile"格式下需要传入加载
数据的路径。
option(“…”):在"jdbc"格式下需要传入 JDBC 相应参数,url、user、password 和 dbtable
我们前面都是使用 read API 先把文件加载到 DataFrame 然后再查询,其实,我们也可以直
接在文件上进行查询: 文件格式.文件路径
spark.sql("select * from json.`/opt/module/data/user.json`").show
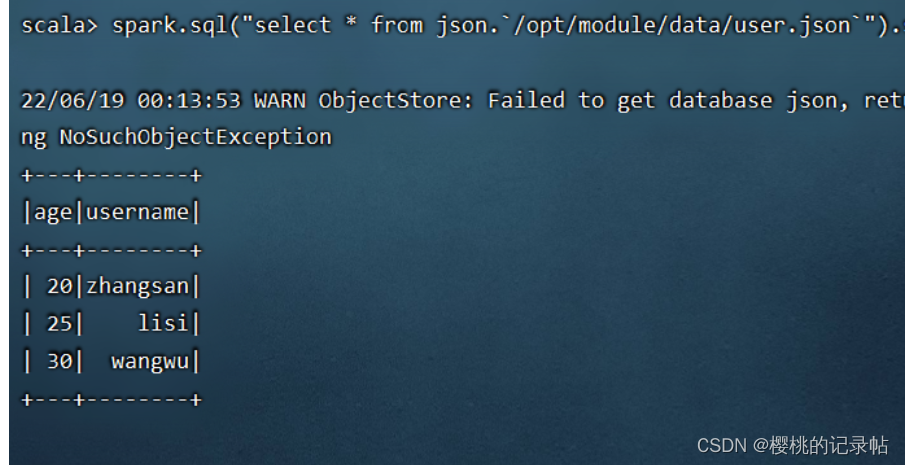
2、保存数据
- df.write.save 是保存数据的通用方法
- 如果保存不同格式的数据,可以对不同的数据格式进行设定
scala>df.write.format("…")[.option("…")].save("…")format(“…”):指定保存的数据类型,包括"csv"、“jdbc”、“json”、“orc”、"parquet"和
“textFile”。
format(“…”):指定保存的数据类型,包括"csv"、“jdbc”、“json”、“orc”、"parquet"和
“textFile”。
option(“…”):在"jdbc"格式下需要传入 JDBC 相应参数,url、user、password 和 dbtable
保存操作可以使用 SaveMode, 用来指明如何处理数据,使用 mode()方法来设置。
SaveMode 是一个枚举类,其中的常量包括:
(二)Parquet
Spark SQL 的默认数据源为 Parquet 格式。Parquet 是一种能够有效存储嵌套数据的列式
存储格式。
数据源为 Parquet 文件时,Spark SQL 可以方便的执行所有的操作,不需要使用 format。
修改配置项 spark.sql.sources.default,可修改默认数据源格式。
1、加载数据
2、保存数据
(三)JSON
Spark SQL 能够自动推测 JSON 数据集的结构,并将它加载为一个 Dataset[Row]. 可以
通过 SparkSession.read.json()去加载 JSON 文件。
注意:Spark 读取的 JSON 文件不是传统的 JSON 文件,每一行都应该是一个 JSON 串。格
式如下:
{"username":"zhangsan","age":20}
{"username":"lisi","age":25}
{"username":"wangwu","age":30}
1、导入隐式转换
import spark.implicits._2、加载 JSON 文件
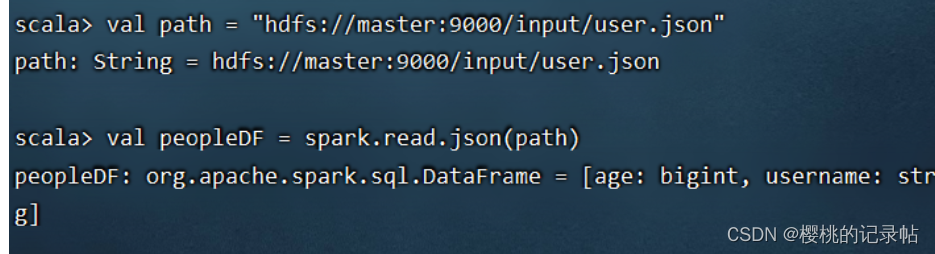
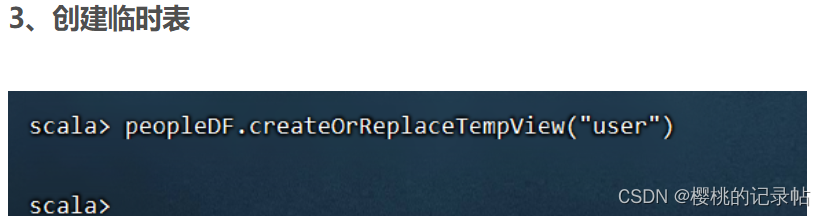
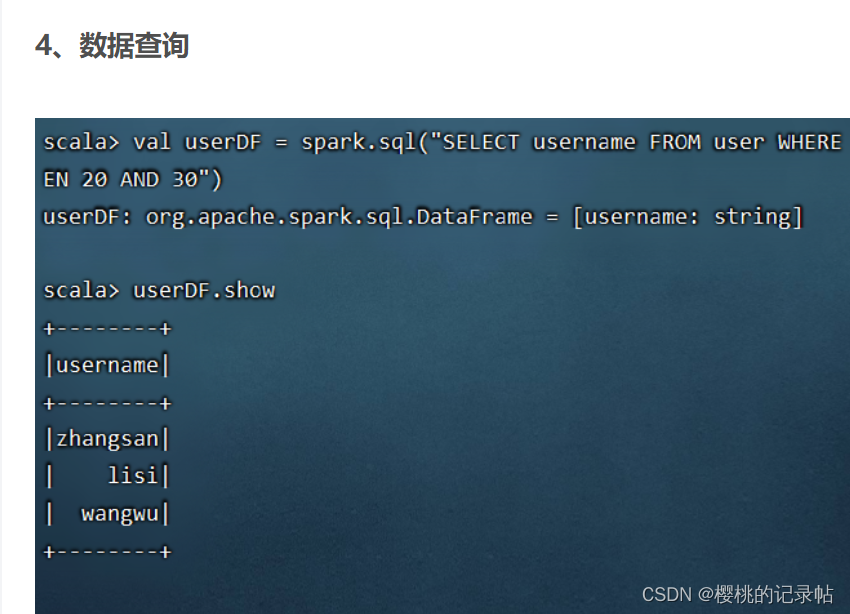
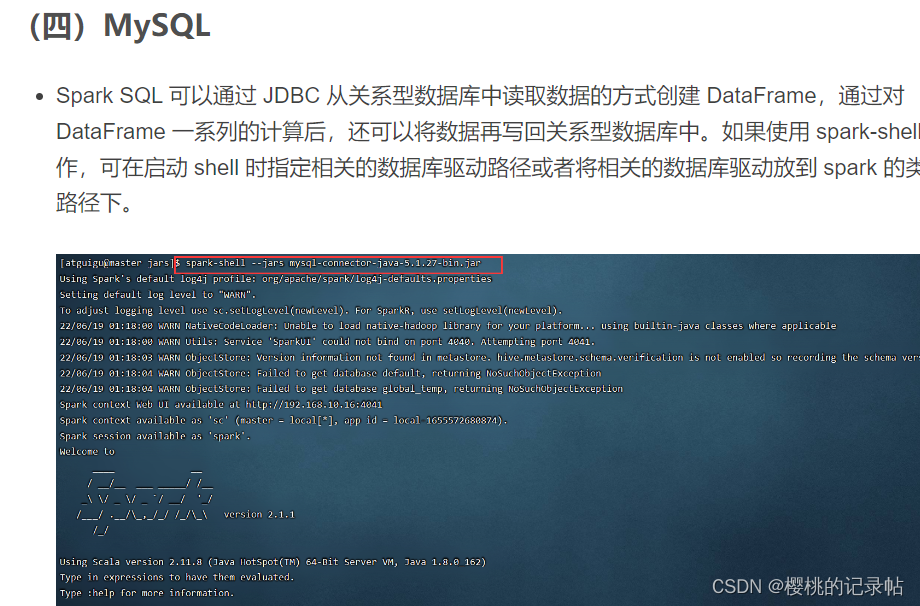
1、读取数据

2、写入数据
- 创建样例类
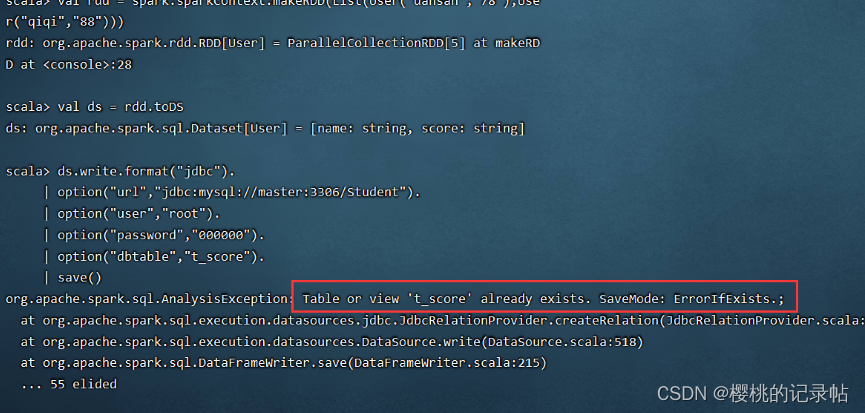
- 创建RDD,将RDD的数据写入到myql
- 错误
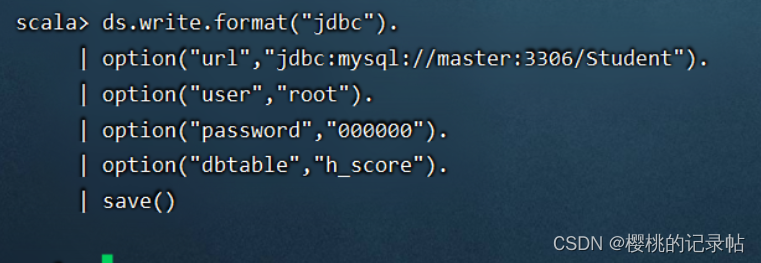
修改结果
查看结果


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









