






目录
8 逻辑回归
摘要:
本章实现的工作是:首先导入样本数据,包括学生的语文、数学、英语成绩及学生所属类别(文科生,理科生、综合生),并划分训练集与测试集。然后采用逻辑回归算法,用样本数据构建回归模型,进而利用模型和更多学生的成绩进行分类预测。最后将预测与真实类别标签值进行对比显示,检验模型的预测正确率。
本章掌握的技能是:1、读取样本数据并划分样本为训练集与测试集。2、使用LogisticRegressionCV模块构建逻辑回归模型。3、使用matplotlib库绘制散点图,实现数据的可视化。
8.1 本章工作任务
采用逻辑回归算法编写程序,根据学生的语文、数学、英语成绩对学生所属类别进行预测。1、算法的输入是:600位学生的语文、数学、英语成绩和学生类别标签值(1 表示文科生,2 表示理科生 3 表示综合生)。2、算法模型需要求解的是:逻辑回归模型的参数。3、算法的结果是:根据逻辑回归模型预测的学生类别标签值(1 表示文科生,2 表示理科生,3 表示综合生)
8.2 本章技能目标
掌握逻辑回归原理。
使用Python对数据划分训练集和测试集。
使用Python实现逻辑回归模型建模与求解。
使用Python通过逻辑回归模型实现对不同学生的分类。
使用Python对逻辑回归结果进行可视化展示。
8.3 本章简介
逻辑回归分析是指:一种分类的方法,首先根据样本训练集计算出逻辑函数的系数,然后将测试集带入逻辑函数得到输出结果,再将该输出结果映射为0或1,最终实现分类。
二分类逻辑回归是指:分类结果只有两种类别的逻辑回归。
多分类逻辑回归是指:分类结果有多种类别的逻辑回归,是逻辑回归的推广。
逻辑回归算法可以解决的实际应用问题是:根据600名学生的语文、数学、英语成绩以及学生的类别标签值,建立逻辑回归模型,根据上述模型和测试集中学生的各科成绩,可以预测出对应学生的类别标签值。
本章的重点是:逻辑回归算法的理解和使用。
8.4 编程实战
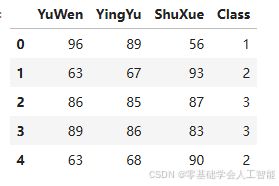
步骤1 准备数据。引入pandas包,并命名为pd。读入在当前工作目录下名为 “ClassifyMyMake”的数据集,赋值给datas,显示datas的前5行数据。
import pandas as pd
datas = pd.read_csv('ClassifyMyMake.csv') # 读入csv格式的数据
datas.head()输出结果:
步骤2 在3种类别的原数据集中,筛选出分类为2的数据和分类为3的数据。其中,使用iloc(located by index, 按照索引号定位)与 loc 函数(按照索引定位)对数据进行切片,将分类为2、3的数据的集合赋值给 datas_two。
temp = datas.iloc[:, 3] != 1 # ':' 即为行或列的全部
datas_two = datas.loc[temp, ] # temp 保留了布尔型的判断结果(即此元组是否为第1类)。步骤3 将datas_two数据集划分为训练集与测试集。
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(datas_two.iloc[:, 0:3], datas_two.iloc[:, 3], test_size = 0.2, random_state = 220)
# (1) test_size 参数代表测试集占据的比例。(2) random_state参数将分割的 training 和 testing 集合打乱,相当于随机数种子的设定。random_state 参数
#如果相同,则每次运行结果都相同步骤4 构建二分类逻辑回归模型并求解模型参数:1、导入sklearn逻辑回归中的LogisticRegressionCV包。2、建立逻辑回归模型model。3、逻辑回归模型求解:输入为 X_train, Y_train。
from sklearn.linear_model import LogisticRegressionCV
import numpy as np
model = LogisticRegressionCV(fit_intercept = True, Cs = np.logspace(-2, 2, 1), cv = 3, penalty = "l2", solver = "lbfgs", tol=0.01)
model.fit(X_train, Y_train)
print("决策函数中的特征系数:", model.coef_)
print("决策函数中的截距: ", model.intercept_)
输出结果:
决策函数中的特征系数: [[ 0.22023508 0.13977968 -0.3081703 ]]
决策函数中的截距: [-0.00319601]
步骤5 根据模型求解测试集的预测类别值。
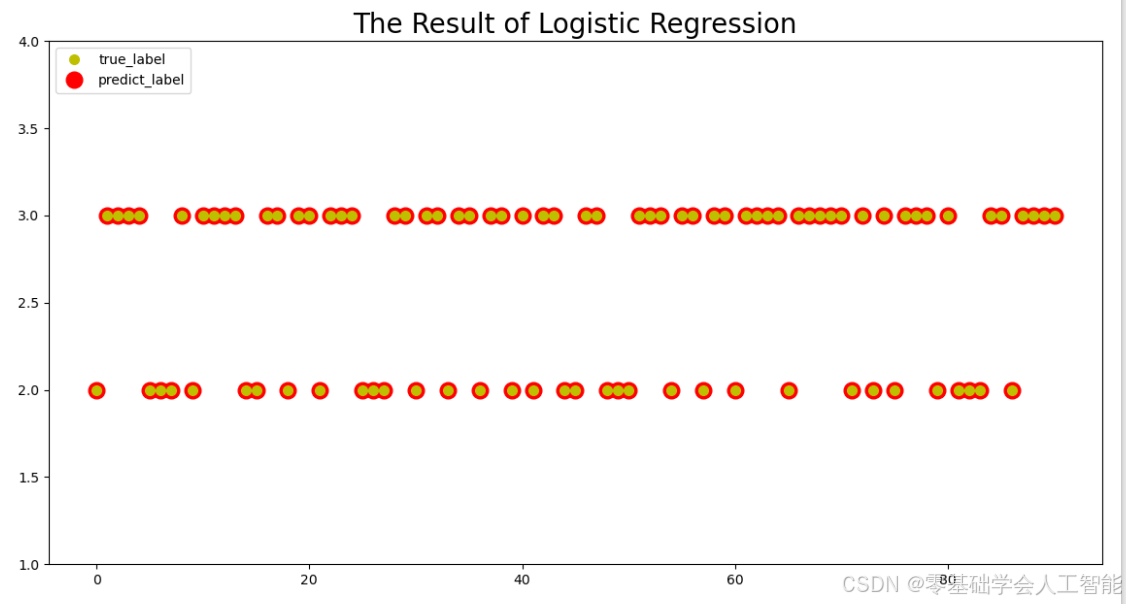
predict = model.predict(X_test)步骤6 将测试集的预测类别值与真实类别值的对比结果进行可视化展示。1、引入matplotlib.pyplot包,并给此包定义一个别名plot。2、画图对预测值和真实值进行比较,并输出模型预测结果的正确率。
import matplotlib.pyplot as plot
def logistic_model_figure(): #封装一个名为 logistic_model_figure的函数:其功能为画出logistic模型预测结果与真实值的对比图
x_len = range(len(X_test)) #以测试集 X_test 的范围定义横轴的长度
plot.figure(figsize = (14, 7), facecolor='w') #定义图片的大小为 14x7 和表面颜色为白色
plot.ylim(1, 4) #定义竖轴的范围为 1到4
plot.plot(x_len, Y_test, 'yo', markersize = 7, zorder=1, label='true_label')
plot.plot(x_len, predict, 'ro', markersize = 12, zorder=0, label='predict_label'%model.score(X_train, Y_train))
plot.legend(loc='upper left')
plot.title('The Result of Logistic Regression', fontsize=20) # 设置图标题,字体大小为 20号
plot.show() #显示图片
print("%s Score: %0.2f%%"%("logistic 二分类模型预测正确率", model.score(X_test, Y_test)*100)) #输出预测正确率统计结果输出结果:
logistic 二分类模型预测正确率 Score: 100.00%
logistic_model_figure() #调用已封装好的绘图函数进行绘图输出结果:
步骤7 将数据集中的全部数据重新划分为训练集与测试集。
X_train, X_test, Y_train, Y_test = train_test_split(datas.iloc[:, 0:3], datas.iloc[:, 3], test_size=0.2, random_state=220)步骤8 构建多分类逻辑回归模型并求解模型参数。1、导入sklearn逻辑回归中的LogisticsRegressionCV类的库。2、建立多分类逻辑回归模型model_three。3、多分类逻辑回归模型求解:输入为:X_train,Y_train。
model_three = LogisticRegressionCV(fit_intercept=True,Cs=np.logspace(-2,2,1),cv=2,solver='newton-cg',penalty='l2',tol=0.01)
model_three.fit(X_train, Y_train)
print("决策函数中的特征系数:\n", model_three.coef_)
print("决策函数中的截距: ", model_three.intercept_)
输出结果:
决策函数中的特征系数:
[[ 0.15374643 0.17952202 -0.35574413]
[-0.19208398 -0.15340869 0.33103293]
[ 0.03833755 -0.02611333 0.0247112 ]]
决策函数中的截距: [ 0.00062197 0.00570055 -0.00632252]步骤9 根据模型求解测试集的预测类别值。
predict = model_three.predict(X_test)步骤10 将测试集的预测类别值与真实类别值的对比结果可视化。
import matplotlib.pyplot as plot
def logistic_model_figure(): #封装一个名为logistic_model_figure的函数,其功能为画出logistic三分类模型预测结果与真实值的对比图
x_len = range(len(X_test))
plot.figure(figsize=(14,7), facecolor='w')
plot.ylim(0,4)
plot.plot(x_len, Y_test, 'go',markersize=7,zorder=1,label='true label')
plot.plot(x_len,predict,'ro',markersize=12,zorder=0,label=f'predict_label: {model_three.score(X_train, Y_train):.2f}')
plot.legend(loc='upper left')
plot.title('The Result of Multi-class Logistic Regression', fontsize=20)
plot.show()
print(f"logistic 二分类模型预测正确率: {model_three.score(X_test, Y_test):.2%}")
输出结果:
logistic 多分类模型预测正确率: 100.00%logistic_model_figure() # 调用已封装好的绘图函数进行绘图输出结果:

8.5 本章总结
本章实现的工作是:首先导入样本数据,包括学生的语文、数学、英语成绩及学生所属类别(文科生,理科生、综合生),并划分训练集与测试集。然后采用逻辑回归算法,用样本数据构建回归模型,进而利用模型和更多学生的成绩进行分类预测。最后将预测与真实类别标签值进行对比显示,检验模型的预测正确率。
本章掌握的技能是:1、读取样本数据并划分样本为训练集与测试集。2、使用LogisticRegressionCV模块构建逻辑回归模型。3、使用matplotlib库绘制散点图,实现数据的可视化。
8.6 本章作业
1、实现本章的案例,即导入数据集并划分样本数据,实现逻辑回归模型的建模、预测和数据可视化。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









