






梯度下降
梯度下降就不是求方程了,也用于最小化损失函数
想让w1的值往导数的方向移动,让导数变成学习力往最小值下降,这就是梯度下降
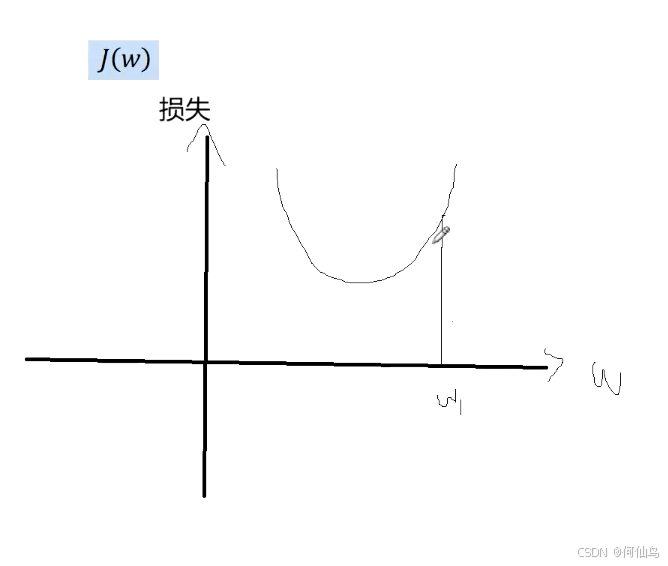
α就是学习率,上面整体是损失(假设只有两个w),下面是对w1求偏导,w1减去后面那个之后完成更新,这就是梯度下降,下面式子的下面改成w0(打错了)。

随机梯度下降代码接口:
sgd = SGDRegressor(eta0=0.01,penalty='l2', max_iter=1000) # 分别是学习率,正则化力度,最大迭代次数下面是一个手写例子,便于理解:
w=1
learning_rate=0.1 #这里是学习率,可以调节
def loss(w):
return 3*w**2+2*w+2
def dao_shu(w):
return 6*w+2
for i in range(30):
w=w-learning_rate*dao_shu(w)
print(f'w {w} 损失{loss(w)}')最终只会找到一个值,可能不会找到全局最优,我们之所以调学习率就是为了找到全局最优如图有两个极小值: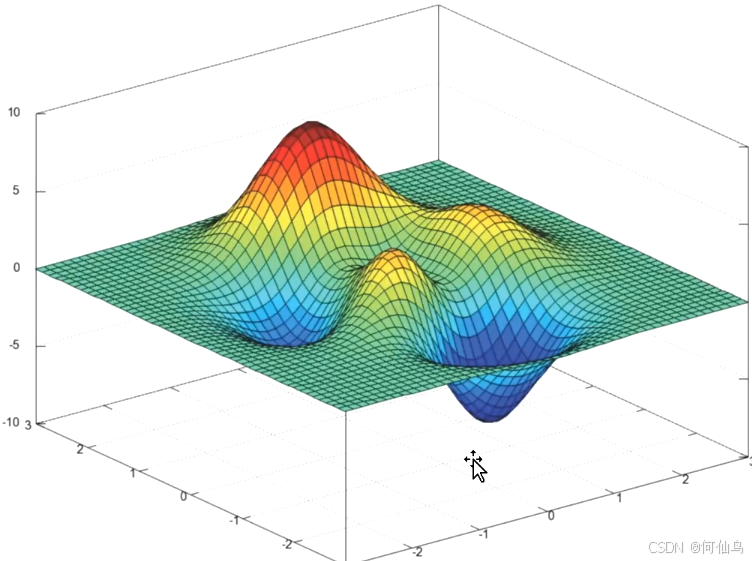
代码:
import os
from sklearn.datasets import fetch_california_housing
from sklearn.linear_model import LinearRegression, SGDRegressor, Ridge, LogisticRegression, Lasso
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import mean_squared_error, classification_report, roc_auc_score
import joblib
import pandas as pd
import numpy as np
# 梯度下降去进行房价预测,数据量大要用这个
# learning_rate的不同方式,代表学习率变化的算法不一样,比如constant,invscaling,adaptive
# 默认可以去调 eta0 = 0.008,会改变learning_rate的初始值
# learning_rate='optimal',alpha是正则化力度,但是会影响学习率的值,由alpha来算学习率
# penalty代表正则化,分为l1和l2
# eta0=0.01, penalty='l2',max_iter=1000
sgd = SGDRegressor(eta0=0.01,penalty='l2', max_iter=1000) # 分别是学习率,正则化力度,最大迭代次数
# # 训练
sgd.fit(x_train, y_train)
#
print('梯度下降的回归系数', sgd.coef_)
#
# 预测测试集的房子价格
# y_sgd_predict = std_y.inverse_transform(sgd.predict(x_test).reshape(-1, 1))
y_predict = sgd.predict(x_test)
# print("梯度下降测试集里面每个房子的预测价格:", y_sgd_predict)
print("梯度下降的均方误差:", mean_squared_error(y_test, y_predict))
# print("梯度下降的原始房价量纲均方误差:", mean_squared_error(std_y.inverse_transform(y_test), y_sgd_predict))学习率的变化方式,会影响学习率的变化:
# learning_rate='optimal',alpha是正则化力度,但是会影响学习率的值,由alpha来算学习率
# learning_rate='constant',eta0是初始学习率,alpha是正则化力度,但是会影响学习率的值,由alpha来算学习率
# learning_rate='invscaling',eta0是初始学习率,power_t是学习率衰减的指数,alpha是正则化力度,但是会影响学习率的值,由alpha来算学习率
# learning_rate='adaptive',eta0是初始学习率,power_t是学习率衰减的指数,alpha是正则化力度,但是会影响学习率的值,由alpha来算学习率


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











