作业题目
- 拼接多个csv文件
- 去除重复数据,重新索引
- 自动挡和手动挡数目
- 计算每个城市二手车数量
- 统计每个汽车品牌平均售价价格(不是原价) (提示:groupby,可以先不做)
答案
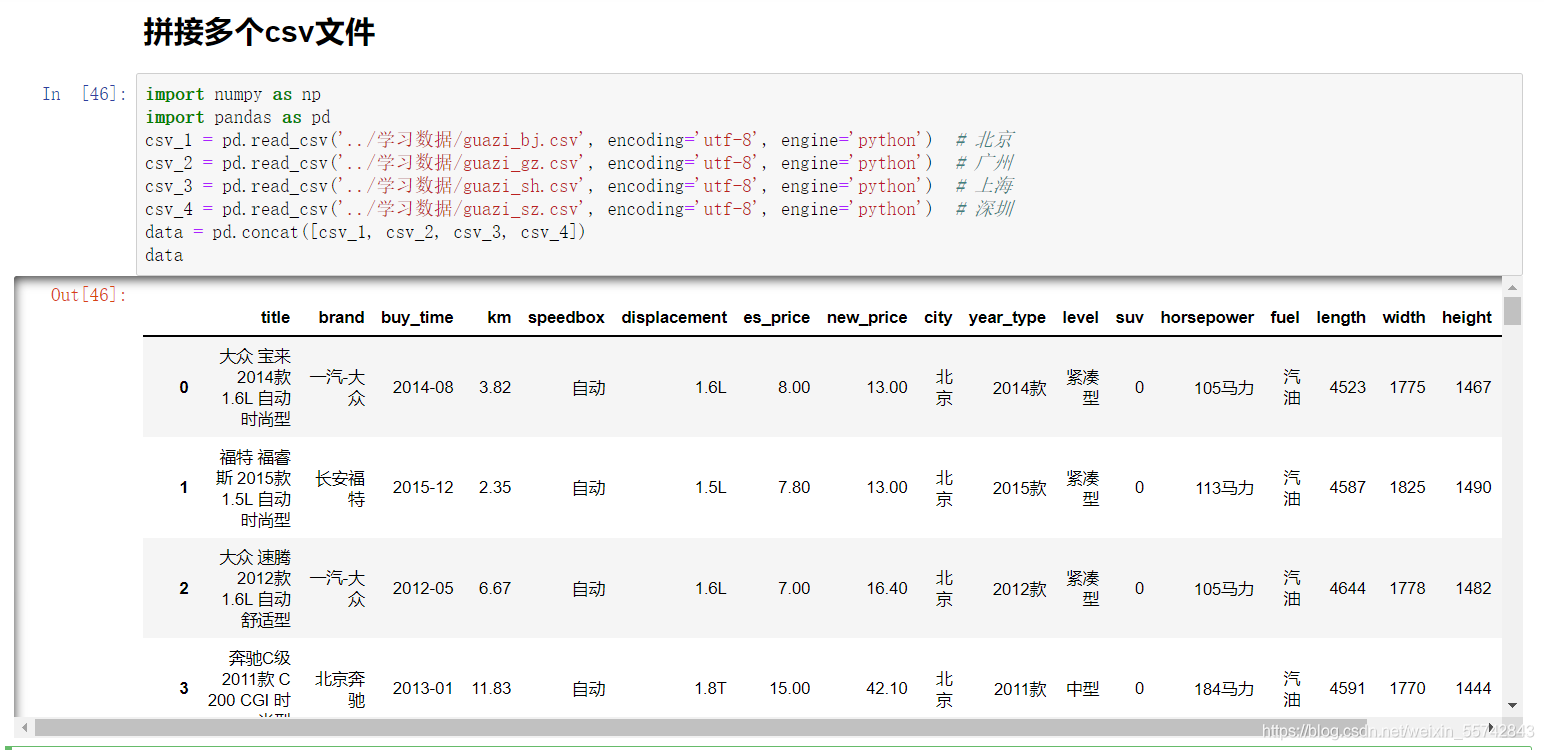
拼接多个csv文件
代码
import numpy as np
import pandas as pd
csv_1 = pd.read_csv('../学习数据/guazi_bj.csv', encoding='utf-8', engine='python') # 北京
csv_2 = pd.read_csv('../学习数据/guazi_gz.csv', encoding='utf-8', engine='python') # 广州
csv_3 = pd.read_csv('../学习数据/guazi_sh.csv', encoding='utf-8', engine='python') # 上海
csv_4 = pd.read_csv('../学习数据/guazi_sz.csv', encoding='utf-8', engine='python') # 深圳
data = pd.concat([csv_1, csv_2, csv_3, csv_4])
data
执行效果
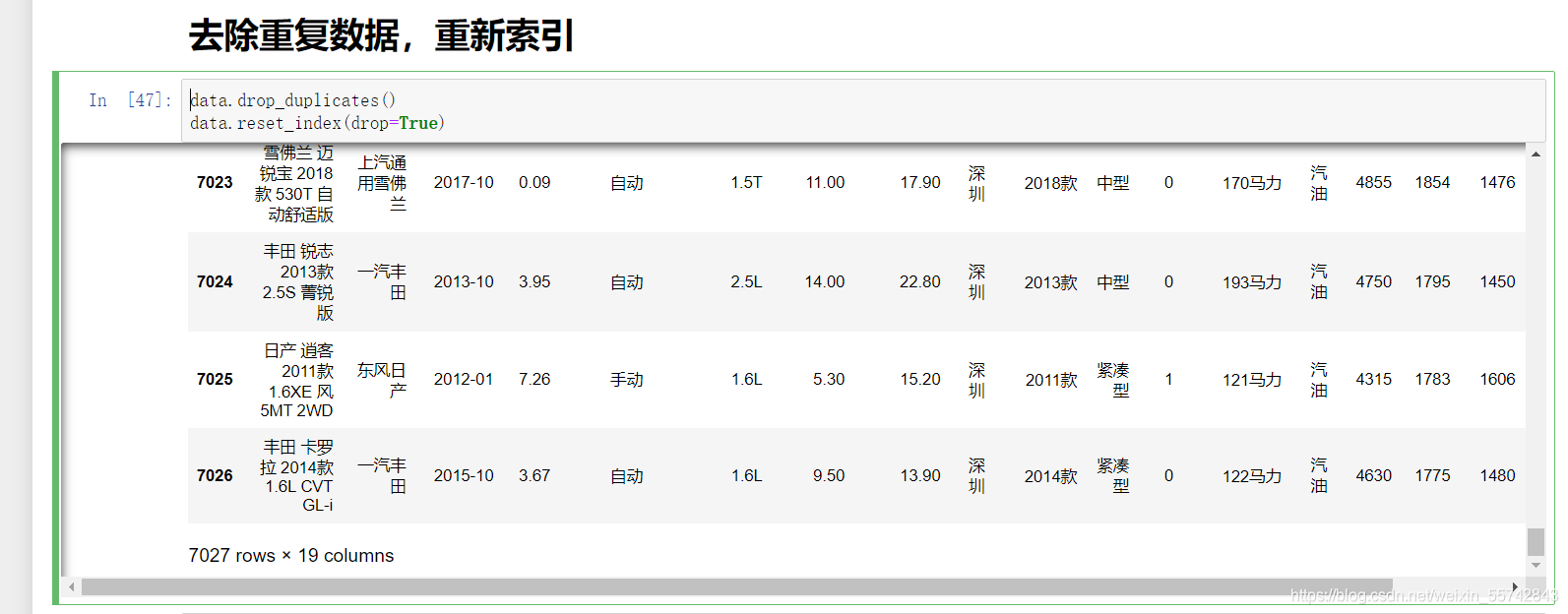
去除重复数据,重新索引
代码
data.drop_duplicates()
data.reset_index(drop=True)
执行效果
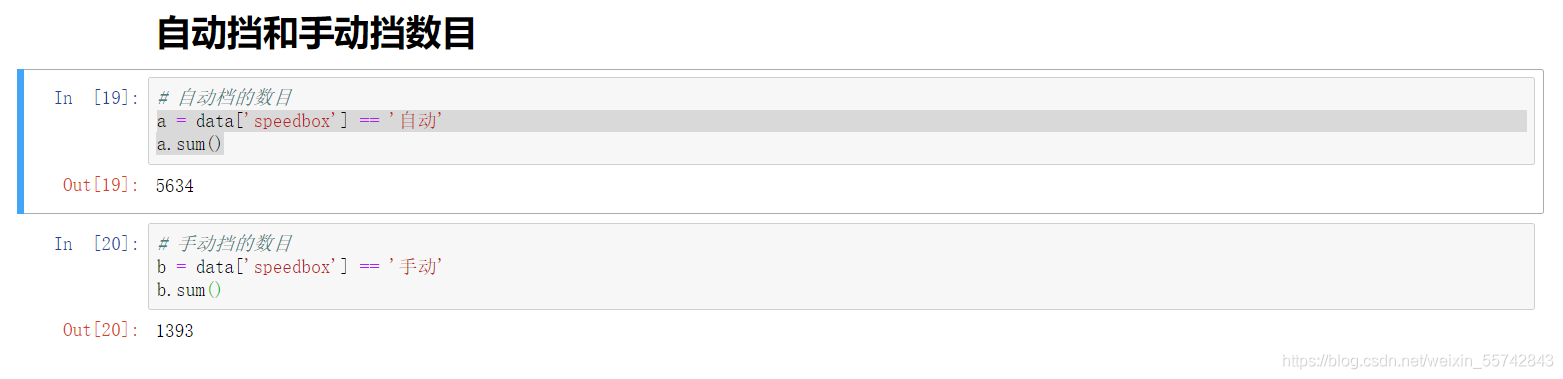
自动挡和手动挡数目
代码
a = data['speedbox'] == '自动'
print(a.sum())
b = data['speedbox'] == '手动'
b.sum()
执行效果
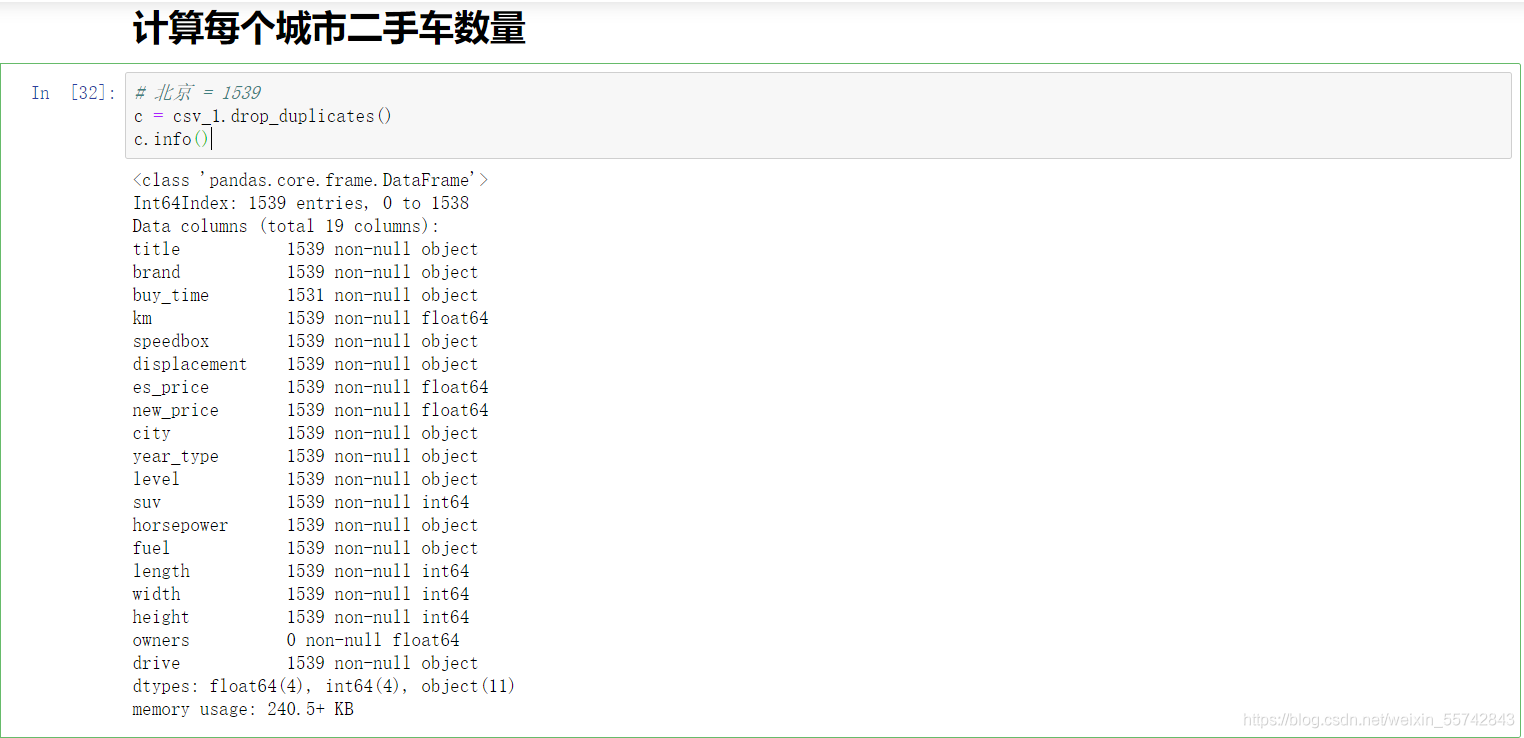
计算每个城市二手车数量
代码
# 北京 = 1539
c = csv_1.drop_duplicates()
c.info()
# -----------------------------------
# 广州 = 2007
d = csv_2.drop_duplicates()
d.info()
# ----------------------------------
# 上海 = 1937
e = csv_3.drop_duplicates()
e.info()
# ---------------------------------
# 深圳 = 1497
f = csv_4.drop_duplicates()
f.info()
执行效果
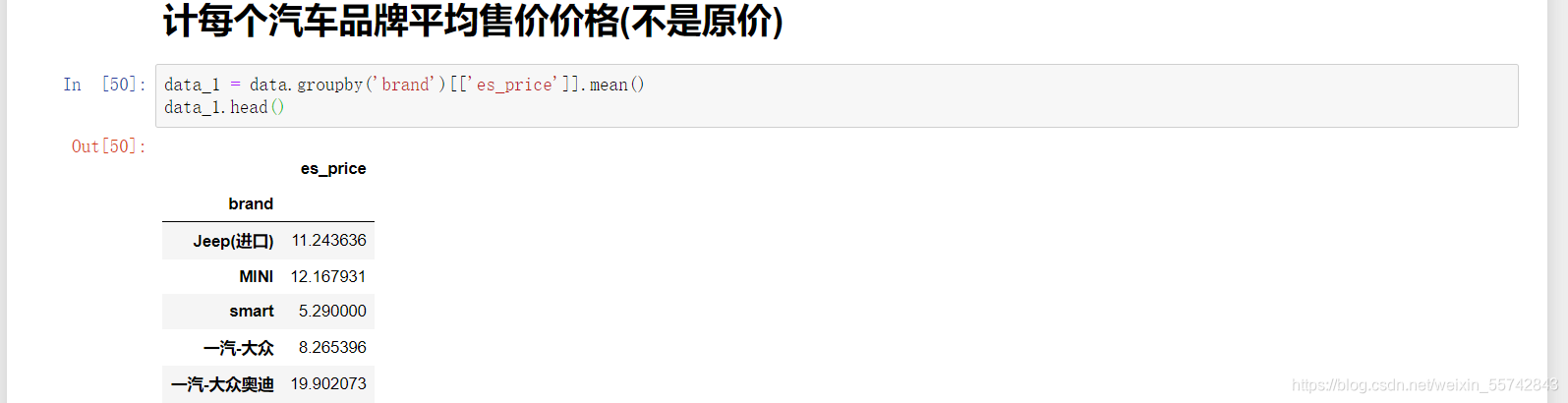
统计每个汽车品牌平均售价价格(不是原价) (提示:groupby,可以先不做)
代码
data_1 = data.groupby('brand')[['es_price']].mean()
data_1.head()
执行效果

























 2370
2370

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









