







 本文详细介绍了ELK(Elasticsearch, Logstash, Kibana)组件的使用,包括Elasticsearch的基础概念和集群配置,Logstash的事件处理流程,以及如何部署和配置ELK栈。通过创建索引、安装elasticsearch-head插件和部署Kibana,实现日志信息的高效搜索和可视化。"
79427954,5088635,NumPy中的按位与逻辑运算,"['NumPy库', '数据处理', 'Python编程', '数学运算', '数组操作']
本文详细介绍了ELK(Elasticsearch, Logstash, Kibana)组件的使用,包括Elasticsearch的基础概念和集群配置,Logstash的事件处理流程,以及如何部署和配置ELK栈。通过创建索引、安装elasticsearch-head插件和部署Kibana,实现日志信息的高效搜索和可视化。"
79427954,5088635,NumPy中的按位与逻辑运算,"['NumPy库', '数据处理', 'Python编程', '数学运算', '数组操作']
ELK组件
- Elasticsearch
日志信息、日志信息搜索(全文搜索引擎)(外部端口9200;内部端口9300) - Logstash
数据输入、输出、数据传输、数据处理、格式化 - Kibana
针对Elasticsearch分析及可视化平台,数据整合、数据分析,简单数据导出 (端口5601)
Elasticsearch
Elasticsearch是一个基于Lucene的搜索服务器。它基于RESTful web接口提供了一个分布式多用户能力的全文搜索引擎。
Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是第二流行的企业搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便
基础概念
-
接近实时
ES是一个接近实时(延迟约1s)的搜索平台 -
集群
一个集群就是由一个或多个节点组织在一起,它们共同持有你整个的数据,并一起提供索引和搜索功能。 -
节点
节点就是一台单一的服务器,是集群的一部分,存储数据并参与集群的索引和搜索功能。 -
索引
一个索引就是一个拥有几分相似特征的文档的集合 -
类型
在一个索引中,你可以定义一种或多种类型。一个类型是你的索引的一个逻辑上的分类/分区,其语义完全由你来定 -
文档
存储数据信息的基本单元,使用json来表示 -
分片和备份
在ES中,索引会备份成分片,每个分片是独立的lucene索引,可以完成搜索分析存储等工作
分片的好处
1.如果一个索引数据量很大,会造成硬件硬盘和搜索速度的瓶颈。如果分成多个分片,分片可以分摊压力。
2.分片允许用户进行水平的扩展和拆分
3.分片允许分布式的操作,可以提高搜索以及其他操作的效率
备份的好处
1.当一个分片失败或者下线时,备份的分片可以代替工作,提高了高可用性
2.备份的分片也可以执行搜索操作,分摊了搜索的压力
LogStash
LogStash由JRuby语言编写,基于消息(message-based)的简单架构,并运行在Java虚拟机(JVM)上。不同于分离的代理端(agent)或主机端(server),LogStash可配置单一的代理端(agent)与其它开源软件结合,以实现不同的功能
事件处理三阶段
- Input
收集源数据(访问日志、错误日志等) - Filter Plugin
用于过滤日志和格式转换 - Output
输出日志
部署ELK
服务器准备
| 项目 | 主机名 | 域名及IP | 所需工具 |
|---|---|---|---|
| Node1节点 | hbh2 | www.node1.com/192.168.88.4 | Elasticsearch Kibana |
| Node2节点 | hbh3 | www.node2.com/192.168.88.5 | Elasticsearch |
| Apache节点 | hbh1 | www.apache.com/192.168.88.11 | Logstash Apache |
配置es环境
在node节点上互相做地址映射,确保java环境的存在
echo '192.168.88.4 www.node1.com' >> /etc/hosts
echo '192.168.88.5 www.node2.com' >> /etc/hosts
java -version #如果没有安装,yum -y install java
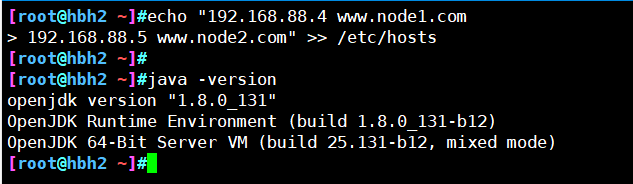
在node节点上部署es软件
解包
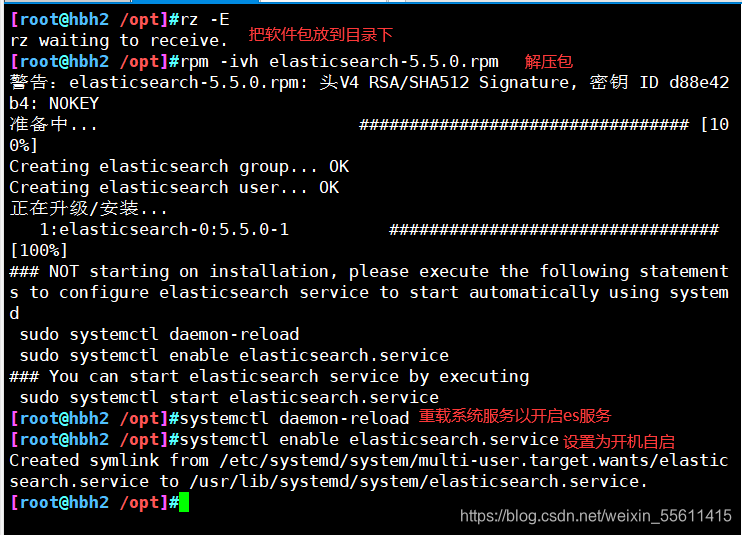
修改es主配置文件
cp -p /etc/elasticsearch/elasticsearch.yml{
,.bak} #进行备份
vim /etc/elasticsearch/elasticsearch.yml
#17行;取消注释,修改;集群名字
cluster.name: my-elk-cluster
#23行;取消注释,修改;节点名字(node2修改成node2) 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 594
594

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









