






【强化学习】GRPO算法和Reward设计
前言
略
GRPO

正如上式所描述,目标函数右侧的KL散度依然保持了RLHF中的相同项,用于保持让模型在RL训练的过程中,能够与最初的冷启动的reference model不要有太大的差距(这可能会导致模型的语言能力减弱)。
除此之外,GRPO做出的改变,集中在最后关于Advantage值的计算上,对比一下原版PPO是如何计算Advantage的,
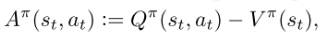
那么原版的PPO中,实际上需要一个单独的Critic模型对当前的状态进行评估得到Value,进而得到Advantage的值,因此GRPO通过这种多次sample的方式,可以优化掉critic model。这在LLM的RL中十分重要,因为LLM的RL过程中,Critic Model很有可能会和大模型本身的大小相差无几,这会严重消耗内存。因此这种通过采样,来估计当前的状态价值,不失为一种很好的策略,不过有意思的是这种方式的提出,貌似看上去公式十分简单,且直观。因此我不禁想问,问什么在提出Actor-Critic的时候,没有人想到这种方式呢?这种方式明明应该更直观啊,为什么我们还需要费尽心思去训练一个Critic Model呢。
Reward构建

关于Reward的设计,DS并没有使用Reward Model的方式,而是采用规则化的得分来实现(这里有个有趣的问题,不同Reward的数值差异很大,该如何解决这些差异呢?文中貌似并未提及。
关于Cold Start的Reward调整

在经历训练的过程中,CoT的内容会出现多种文本混合

















 2158
2158

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









