






完全不了解的深度学习的同学建议先学习课程:零基础实践深度学习:飞桨PaddlePaddle-源于产业实践的开源深度学习平台
肺功能测试是一种用于评估和测量个体呼吸系统功能的医学检查。这种测试可以提供有关肺部健康和功能的重要信息,对于诊断和监测呼吸系统疾病非常有帮助。肺功能检测单包含了患者的肺功能测试结果,以及可能的解释和评估。然而要录入大量肺功能单数据并不是一件容易的事,不仅耗时耗力,还极易出错。
在此,分享如何基于百度飞桨(PaddlePaddle)开源深度学习平台开发肺功能单数据提取与自动录入程序。
1、问题分析
1.1、从图片到数据
想必大家都使用过QQ或微信的文字提取功能,那么我们是否可以通过肺功能检测单的照片提取我们想要的数据呢?答案是肯定的。
QQ或微信该功能的实现是通过光学字符识别OCR(Optical Character Recognition)技术,这是一种计算机视觉技术,能够将印刷或手写的文本图像转换为可以被计算机处理的文本数据。
但这种方法被集成到软件中了,那么我们是否有开源的、能够灵活批量处理肺功能单的工具?下面我将隆重介绍我们的主角------PaddleOCR!!!这是百度飞桨平台发布的一个文字识别项目(GitHub - PaddlePaddle/PaddleOCR),它提供了数据标注工具、多语言文字识别预训练模型、模型训练与微调工具、模型推理与部署工具和一系列教程,能够让我们开心快乐地开发出能够实现特定任务的OCR深度学习模型,实现某些特定任务。PaddleOCR旨在打造一套丰富、领先、且实用的OCR工具库,助力开发者训练出更好的模型,并应用落地。
1.2、演示示例
文字识别模型识别图像后返回的结果到底是个什么东西?以下是利用ch_PP-OCRv4_det文本检测模型(检测图像中文本的位置)和ch_PP-OCRv4_rec文本识别模型(根据det模型提供的文本位置识别文本内容)推理的结果展示。

## 以上是检测结果的可视化,以下是实际产生的推理结果的文本文件
/home/aistudio/Croped_imgs/img_rot270_001.jpg
{"ocr_info": [{"transcription": "金**", "bbox": [269, 3, 692, 175], "points": [[276.0, 3.0], [692.0, 21.0], [685.0, 175.0], [269.0, 157.0]], "pred_id": 3, "pred": "ANSWER"}, {"transcription": "Name", "bbox": [128, 87, 247, 159], "points": [[128.0, 87.0], [247.0, 87.0], [247.0, 159.0], [128.0, 159.0]], "pred_id": 1, "pred": "QUESTION"}, {"transcription": "IDNo", "bbox": [128, 154, 247, 226], "points": [[128.0, 154.0], [247.0, 154.0], [247.0, 226.0], [128.0, 226.0]], "pred_id": 1, "pred": "QUESTION"}, {"transcription": "810745", "bbox": [271, 164, 562, 217], "points": [[271.0, 164.0], [562.0, 164.0], [562.0, 217.0], [271.0, 217.0]], "pred_id": 3, "pred": "ANSWER"}, {"transcription": "Date", "bbox": [124, 217, 233, 294], "points": [[124.0, 217.0], [233.0, 217.0], [233.0, 294.0], [124.0, 294.0]], "pred_id": 1, "pred": "QUESTION"}, {"transcription": "05/27/2023 10:02", "bbox": [266, 231, 652, 279], "points": [[266.0, 231.0], [652.0, 231.0], [652.0, 279.0], [266.0, 279.0]], "pred_id": 3, "pred": "ANSWER"}, {"transcription": "Sex", "bbox": [128, 284, 219, 347], "points": [[128.0, 284.0], [219.0, 284.0], [219.0, 347.0], [128.0, 347.0]], "pred_id": 1, "pred": "QUESTION"}, {"transcription": "Male", "bbox": [266, 289, 371, 347], "points": [[266.0, 289.0], [371.0, 289.0], [371.0, 347.0], [266.0, 347.0]], "pred_id": 3, "pred": "ANSWER"}, {"transcription": "Age", "bbox": [500, 284, 600, 352], "points": [[500.0, 284.0], [600.0, 284.0], [600.0, 352.0], [500.0, 352.0]], "pred_id": 1, "pred": "QUESTION"}, {"transcription": "53", "bbox": [657, 284, 733, 342], "points": [[657.0, 284.0], [733.0, 284.0], [733.0, 342.0], [657.0, 342.0]], "pred_id": 3, "pred": "ANSWER"}, {"transcription": "HT", "bbox": [128, 347, 205, 414], "points": [[128.0, 347.0], [205.0, 347.0], [205.0, 414.0], [128.0, 414.0]], "pred_id": 1, "pred": "QUESTION"}, {"transcription": "162.6cm", "bbox": [266, 347, 466, 414], "points": [[266.0, 347.0], [466.0, 347.0], [466.0, 414.0], [266.0, 414.0]], "pred_id": 3, "pred": "ANSWER"}]}
推理结果文本格式讲解:
1、每一行就是一张图片的推理结果,以上只显示了一行结果(一张图)的部分内容。
2、一行格式为:图片路径 、制表符、 JSON格式内容(也可以说是python的字典类型数据)
/home/aistudio/Croped_imgs/img_rot270_001.jpg {‘xx’:[xx]}
3、JSON格式内容
{"ocr_info":[
{
"transcription":"金**",
"bbox":[269,3,692,175],
"points":[[276,3],[692,21],[685,175],[269,157]],
"pred_id":3,
"pred":"ANSWER"
},
{
"transcription":"Name",
"bbox":[128,87,247,159],
"points":[[128,87],[247,87],[247,159],[128,159]],
"pred_id":1,
"pred":"QUESTION"
}
]
}
# JSON格式是一个字典类型数据,即{"key": "value"},键值对数据
# key名为ocr_info,value为一个列表数据,即[]
# 列表数据中又包含了多个字典{},每个字典就是一个检测框的数据
# 每个检测框的数据存在一个字典里,字典包含名为transcription、bbox等的键名和对应的值
# transcription是检测的文本结果,bbox是文本框位置
我们就是从推理结果的文本文件中提取我们想要的数据!
1.3、方向分类
某些手机,即使当我们竖着拍照时,图像有时候也会发生旋转,这会极大地影响到后续结果。以下是一个0°的图像和180°的图像的预测结果。


可以看到,发生旋转的图像识别效果非常差!这时就需要训练一个能够自动校正图像方向的模型。那么什么是方向分类模型?那么什么是分类模型,以下是一个例子。
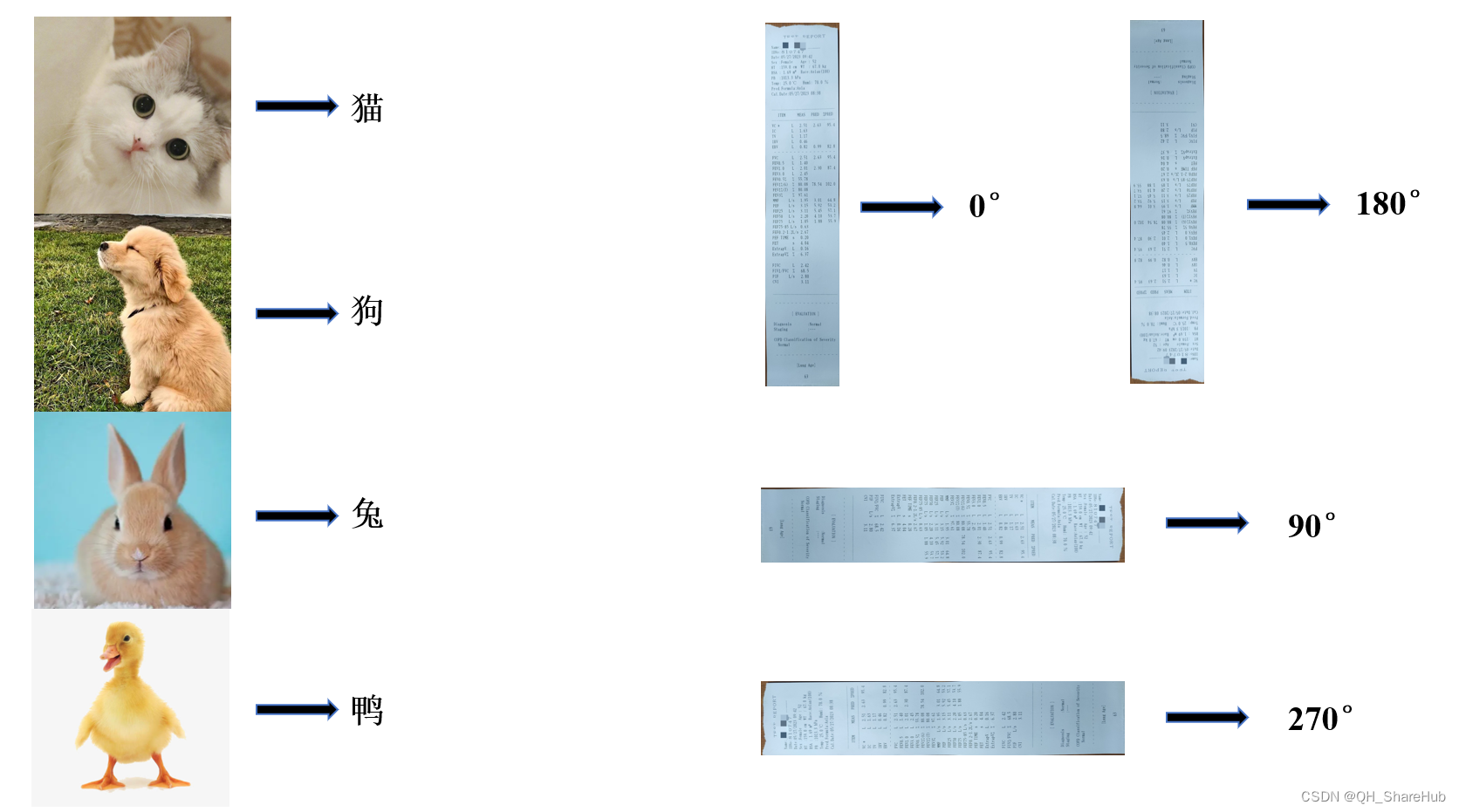
分类模型可以识别主体是什么,比如看见猫的图片就可以识别为“猫”这个标签。类似地,我们可以训练肺功能单的方向分类模型,让正向图片的标签为“0°”,以此类推。当模型见到旋转的图像就会识别为对应的标签,我们就可以根据标签对图像进行转正操作。
该部分参考:
多方向证照图片的OCR方案详解 - 飞桨AI Studio星河社区 (baidu.com)
1.4、目标检测
由于肺功能单比较狭长,照片大概会有2/3无效信息,对无效信息进行裁剪可以提高模型训练和推理的速度。那么我们如何才能精确的裁剪?我们可以利用目标检测模型推理出的目标框进行裁剪。基于人物的目标检测模型可以检测出人物所在的最小四边形。同理,我们也可以训练一个针对肺功能单这个目标的检测模型,并根据检测出的四边形位置信息裁剪图像。

该部分参考:
数据标注懒人包:目标检测小样本手动标注解决方案(一) - 飞桨AI Studio星河社区 (baidu.com)
1.5、关键信息提取KIE, Key Information Extraction
不知道你是否发现:1.2示例的结果文本文件中,识别的内容并不是完全、严格地从上到下、从左到右的顺序识别文本内容,我们就不能知道哪个肺功能指标对应哪个数值!!!
好在PaddleOCR提供了一种关键信息提抽取实现路径,可以训练模型将问题和答案链接。或许我们也可以训练一个关键信息抽取模型,将肺功能指标和对应的结果链接,就可以完美解决问题和答案不清的问题。
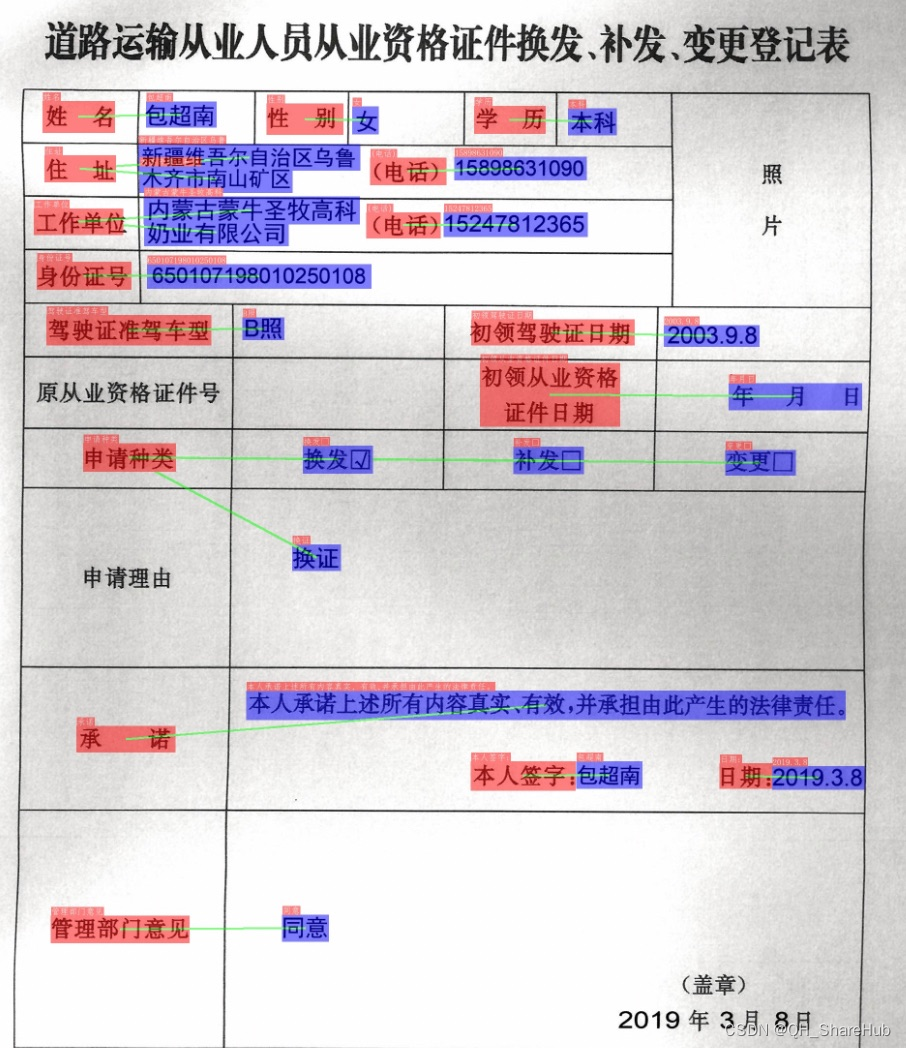
图中红色框表示问题,蓝色框表示答案,问题和答案之间使用绿色线连接。
详细参考:
https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.7/ppstructure/README_ch.md
2、实践流程
根据以上的分析,本项目拟实践流程如下:




















 647
647

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











