






 本文深入探讨了XGBoost的工作原理,包括预测、树的复杂度、泰勒展开求解目标函数及树的结构划分。通过糖尿病数据集案例,展示了XGBoost的预测过程、损失函数的变化以及特征重要性的可视化。此外,还进行了超参数学习率的调节,并通过交叉验证找到了最佳学习率。
本文深入探讨了XGBoost的工作原理,包括预测、树的复杂度、泰勒展开求解目标函数及树的结构划分。通过糖尿病数据集案例,展示了XGBoost的预测过程、损失函数的变化以及特征重要性的可视化。此外,还进行了超参数学习率的调节,并通过交叉验证找到了最佳学习率。
xgboost
xgboost是将很多树模型集成在一起,形成的强分类器
原理
1.xgboost预测
Xgboost算法是和决策树算法联系到一起的,所以我们对不同叶子结点分配不同的权重项。此时我们的预测值,

我们的目标函数,
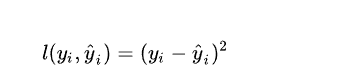
最优函数解,

集成算法的表示,
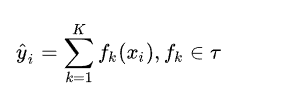
这个式子展开是:

一开始树是0,然后往里面加数,相当于多了一个函数,再加第二棵树,相当于又多了一个函数…,这里需要保证加入新的函数能够提升整体的表达效果。提升表达效果的意思就是加上新的树之后,目标函数(就是损失)的值会下降。
2.数的复杂度
接下来定义树的复杂度,对于f_{t}的定义做一下细化,把树拆分成结构函数q(输入x输出叶子结点索引)和叶子权重部分w(输入叶子结点索引输出叶子结点分数),结构函数q把输入映射到叶子的索引号上面去,而w给定了每个索引号对应的叶子分数是什么。
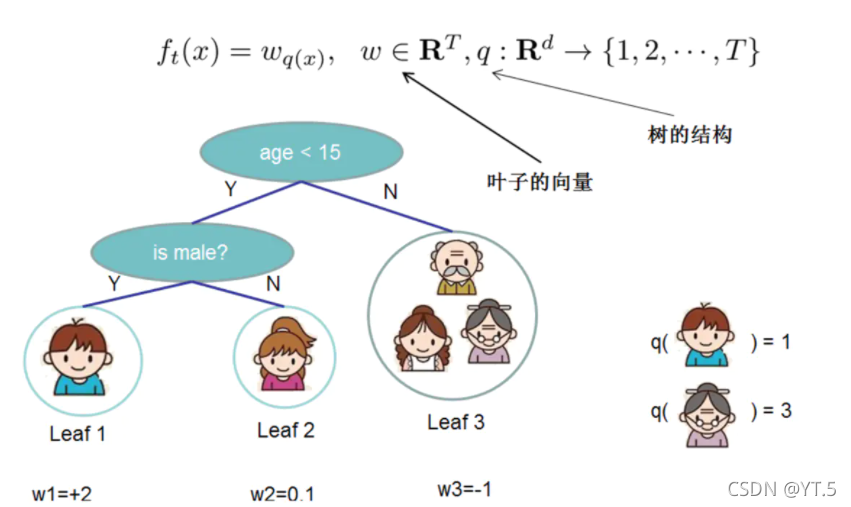
如果叶子结点的个数太多,那么过拟合的风险会越大,所以要限制叶子结点的个数,所以在原来目标函数里加上一个正则化惩罚项,我们来看一下如何计算,
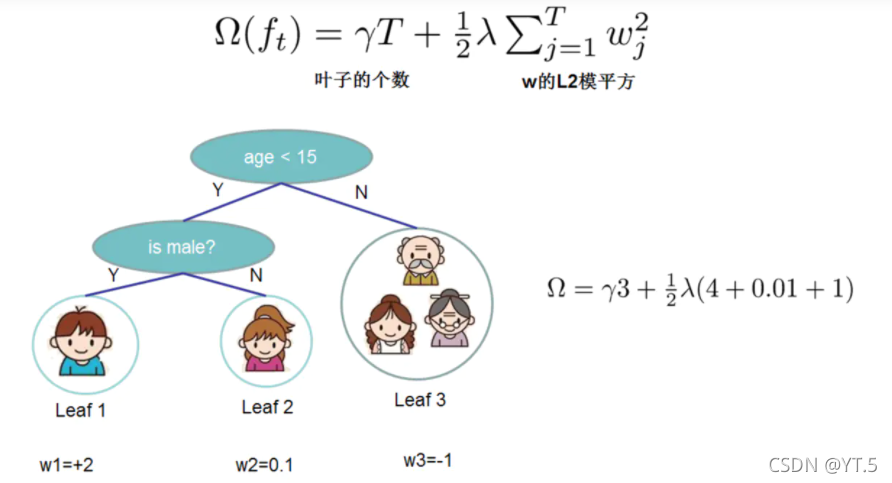
得到目标函数:
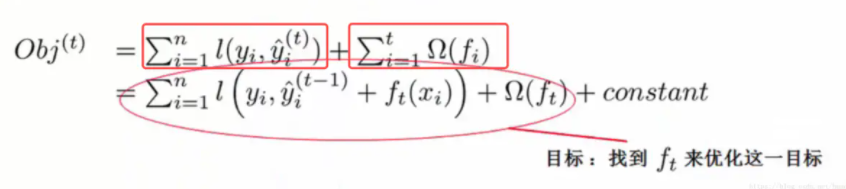
3.泰勒展开求解目标函数
用泰勒展开逼近一个目标函数:
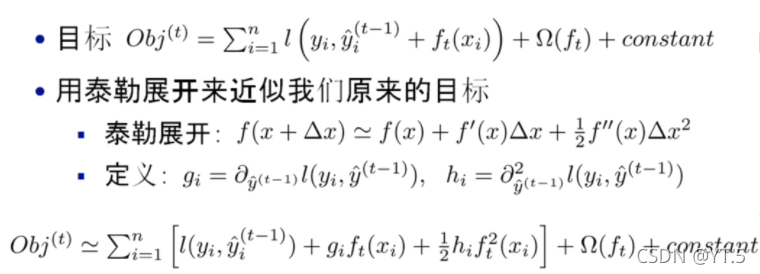
我们发现真实值与上一轮的预测值之间的差值是一个常数项,这个常数项可以移除,就变成了
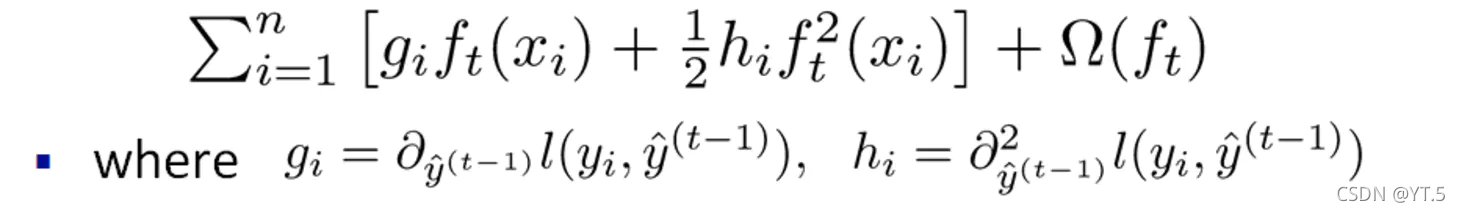
我们将q与j合并继续进行计算,
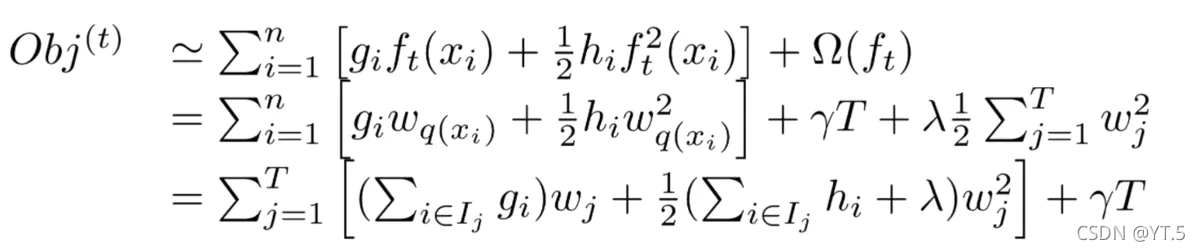
其中被定义为每个叶子上面样本集合(每个叶子结点里面样本集合);等价于求出的值(每一个样本所在叶子索引的分数);为叶子结点数量。定义(每个叶子结点里面一阶梯度的和)(每个叶子结点里面二阶梯度的和),
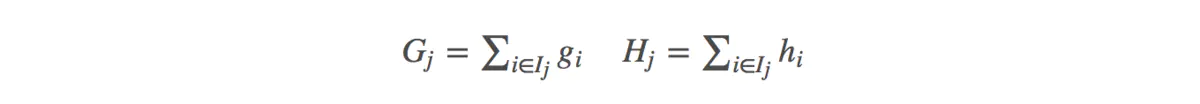
目标函数变成了:
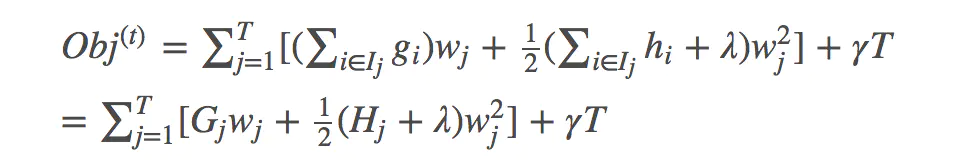
求偏导:
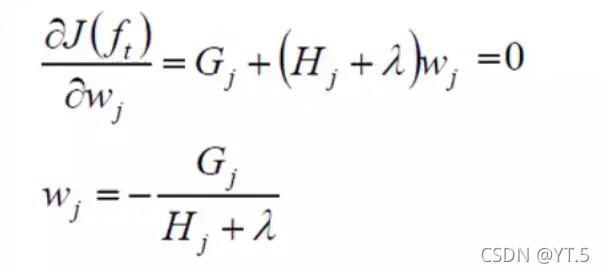
我们将求出的带回到目标函数得到,
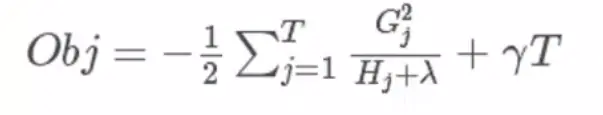
Obj代表了当我们指定一个树的结构的时候,我们在目标上面最多减少多少,可叫做结构分数,可以认为这个就是类似基尼系数一样更加一般的对于树结构进行打分的函数。Obj计算示例,
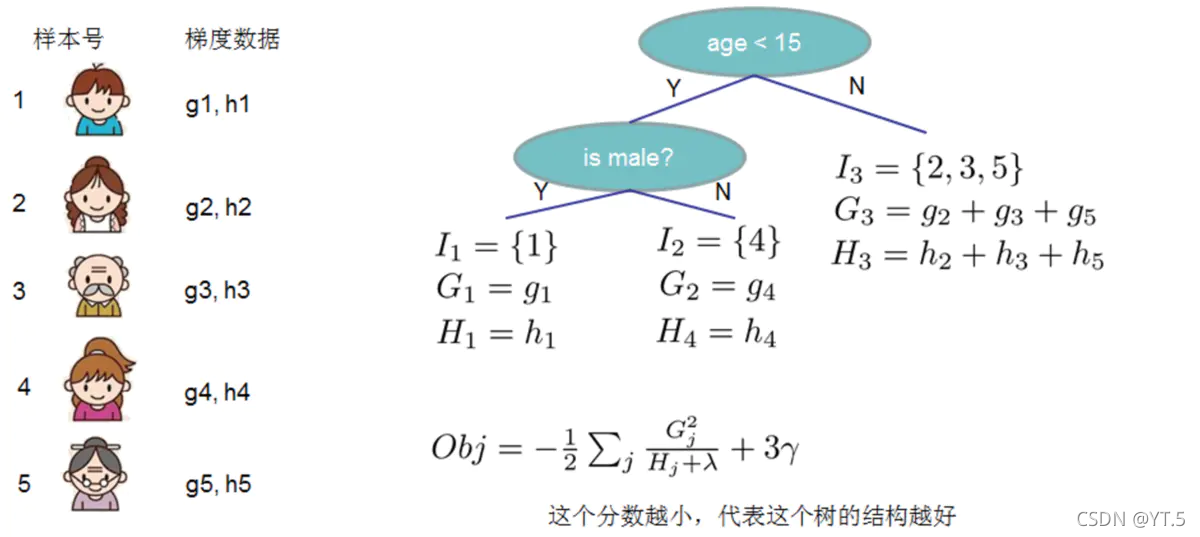
4.树的结构划分
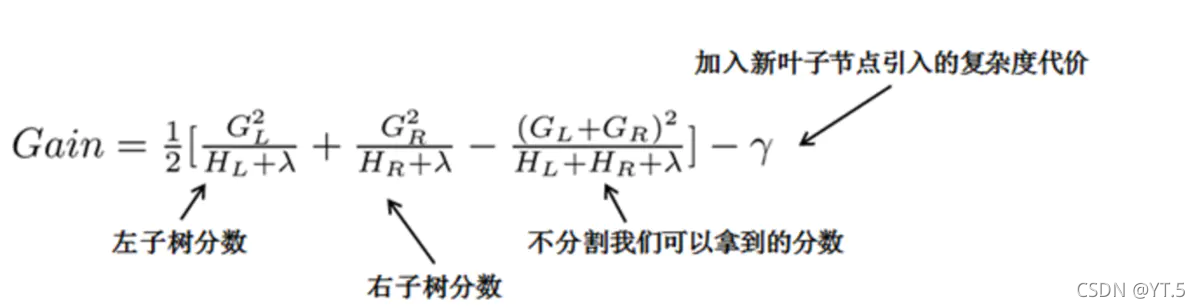
基于目标函数Obj,对结点进行分割,分别对左右子树求目标值,然后再对未分割之前的树结构进行求目标值,最后在所有特征离选择分割后,取Gain最高的那个特征。
案例分析
数据集:糖尿病数据集
数据集的目标是基于数据集中包含的某些诊断测量来诊断性的预测患者是否患有糖尿病。
1.第一次简单的预测
import xgboost
import numpy as np
from numpy import loadtxt
from xgboost import XGBClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
path = "pima-indians-diabetes.csv"
dataset = loadtxt(path,delimiter = ",")
X = dataset[:,0:8]
Y = dataset[:,8]
seed = 7 # 方便数据的复现
test_size = 0.7
x_train,x_test,y_train,y_test = train_test_split(X,Y,test_size = test_size,random_state = seed)
model = XGBClassifier()
model.fit(x_train,y_train)
# 预测数据
y_pred = model.predict(x_test)
predictions = [round(value) for value in y_pred]
accuracy = accuracy_score(y_test,predictions)
print(accuracy)
结果:
0.741635687732342
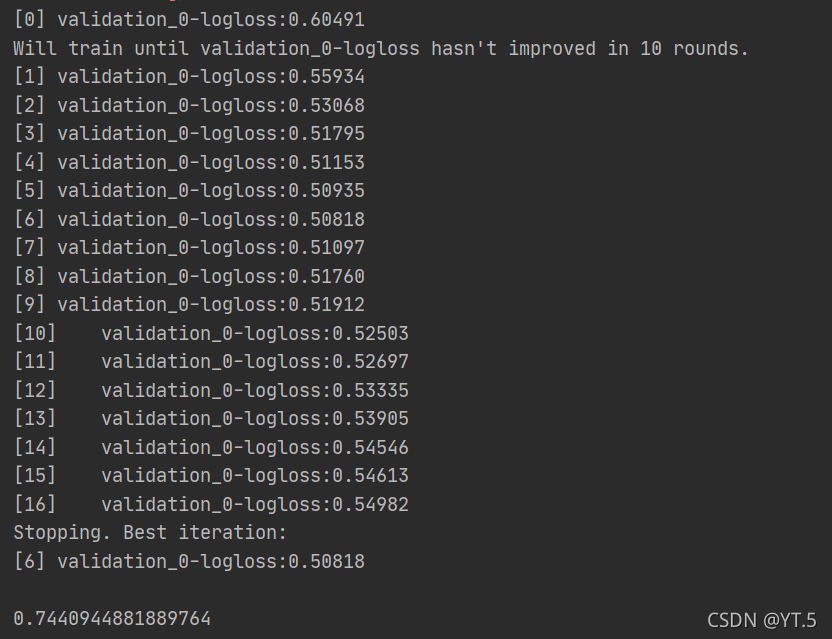
2.将损失函数每次变化的结果输出
eval_set = [(x_test,y_test)]
# early_stopping_rounds 是表示可连续10次对模型没优化效果,不然说明达到饱和状态,退出
model.fit(x_train,y_train,early_stopping_rounds=10,eval_metric="logloss",eval_set = eval_set,verbose=True)
y_pred = model.predict(x_test)
predictions = [round(value) for value in y_pred]
accuracy = accuracy_score(y_test,predictions)
print(accuracy)
结果:
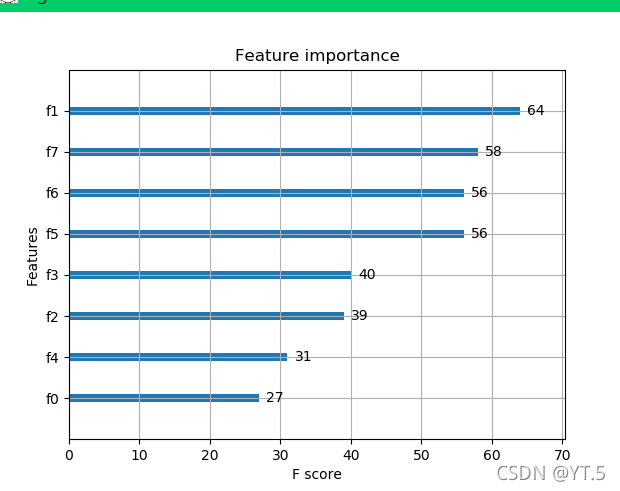
3.查看特征的重要程度
plot = plot_importance(model)
pyplot.show()
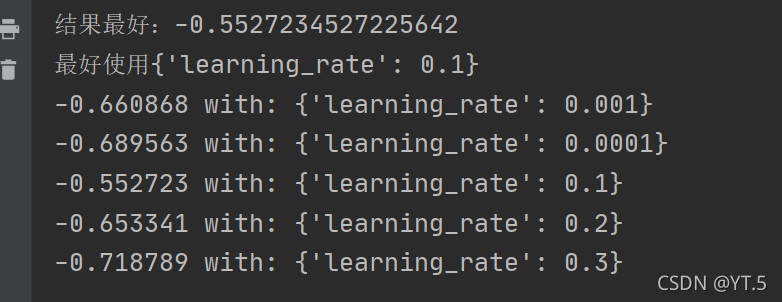
4.超参数的调节(学习率)
database = loadtxt(path,delimiter = ",")
X = database[:,0:8]
Y = database[:,8]
model = XGBClassifier()
learning_rate = [0.001,0.0001,0.1,0.2,0.3] # 学习率
param_grid = dict(learning_rate = learning_rate)
kfold = StratifiedKFold(n_splits=10,shuffle=True,random_state=7) # 交叉验证
grid_search = GridSearchCV(model,param_grid=param_grid,scoring="neg_log_loss",n_jobs = -1,cv = kfold) # n_jobs=-1 :调动空闲cpu
grid_result = grid_search.fit(X,Y)
print("结果最好:",end="")
print(grid_result.best_score_)
print("最好使用",end="")
print(grid_result.best_params_)
means = grid_search.cv_results_['mean_test_score']
params = grid_result.cv_results_['params']
for mean,param in zip(means,params):
print("%f with: %r" % (mean,param))
结果:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









