







 本文详细介绍了在三台服务器上搭建Hadoop、Zookeeper、Kafka、Flink集群的完整过程,包括Java和MySQL的安装,以及各组件的配置、启动和互连测试。此外,还涉及了网络配置、SSH免密登录、时间同步等关键步骤,确保集群的稳定运行。
本文详细介绍了在三台服务器上搭建Hadoop、Zookeeper、Kafka、Flink集群的完整过程,包括Java和MySQL的安装,以及各组件的配置、启动和互连测试。此外,还涉及了网络配置、SSH免密登录、时间同步等关键步骤,确保集群的稳定运行。
安装规划
| master | slave1 | slave2 | |
|---|---|---|---|
| Java | √ | √ | √ |
| MySQL(Hvie_MetaStore) | √ | ||
| NameNode | √ | ||
| DataNode | √ | √ | √ |
| SecondaryNameNode | √ | ||
| ResouceManager | √ | ||
| NodeManager | √ | √ | √ |
| HiveServer2 | √ | ||
| Zookeeper | √ | √ | √ |
| Kafka | √ | √ | √ |
| StandaloneSessionClusterEntrypoint | √ | √ | |
| TaskManagerRunner | √ | √ | √ |
全机互通
- 准备机器

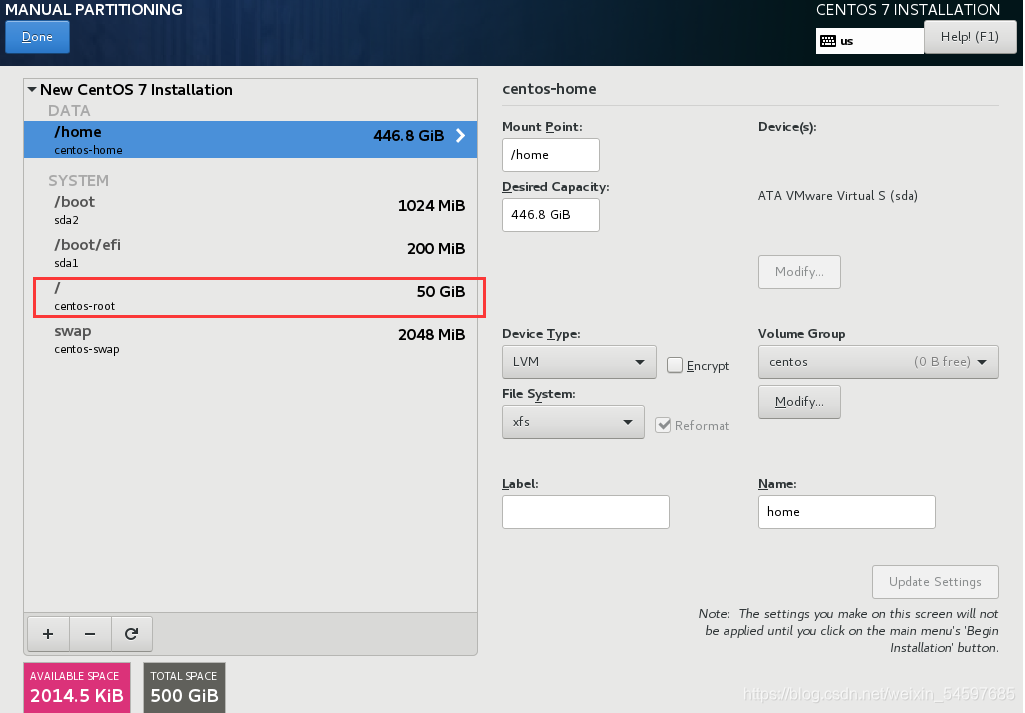
==tips:==如果只用root用户,建议安装时选择手动分区,将/home分区空间给/root分区
-
修改主机名
hostnamectl set-hostname master hostnamectl set-hostname slave1 hostnamectl set-hostname slave2 -
关闭&禁用防火墙
#查看防火墙状态 systemctl status firewalld #关闭防火墙 systemctl stop firewalld #禁用防火墙 systemctl disable firewalld -
关闭&禁用网络管理服务
#查看用网络管理服务 systemctl status NetworkManager #关闭网络管理服务 systemctl stop NetworkManager ##禁用网络管理服务 systemctl disable NetworkManager -
配置network。
#进入配置文件 vi /etc/sysconfig/network-scripts/ifcfg-ens33 #修改配置文件 :1,$s/\"//g #替换双引号 #修改 BOOTROTO=static #添加 IPADDR=自己的 NETMASK=255.255.255.0 GATEWAY=自己的 DNS1=8.8.8.8 DNS2=114.114.114.114重启网络服务
systemctl restart network -
测试网络连通性。
互ping,ping外网
-
配置主机名和IP的映射
vi /etc/hosts #---------------- 192.168.158.241 master 192.168.158.242 slave1 192.168.158.243 slave2 -
配置SSH免密登录
#修改root密码 passwd root #安装必要SSH服务 yum -y install openssh-server openssh-clients #启动SSH服务 systemctl start sshd ssh-keygen -t rsa # 三次回车 ssh-copy-id master ssh-copy-id slave1 ssh-copy-id slave2互相连接测试
ssh master exit ssh slave1 exit ssh slave2 exit -
同步服务器时钟
#master
yum -y install ntp ntpdate
ntpdate cn.pool.ntp.org
ln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
cp /etc/ntp.conf /etc/ntp.conf.bak
cp /etc/sysconfig/ntpd /etc/sysconfig/ntpd.bak
echo "restrict master mask 255.255.255.0 nomodify notrap" >> /etc/ntp.conf
echo "SYNC_HWCLOCK=yes" >> /etc/sysconfig/ntpd
systemctl restart ntpd
#slave1\slave2
yum -y install ntpdate crontabs
ln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
ntpdate hadoop1
echo "*/30 * * * * /usr/sbin/ntpdate master" >> /var/spool/cron/root
Java安装
解压、软连接、系统环境变量
tar zxvf /opt/download/jdk-8u171-linux-x64.tar.gz -C /opt/software/
ln -s /opt/software/jdk1.8.0_171 /opt/software/java
#-----------------------------------
export JAVA_HOME=/opt/software/javaexport PATH=$JAVA_HOME/bin:$PATH
Mysql安装
安装服务
tar xvf MySQL-5.5.40-1.linux2.6.x86_64.rpm-bundle.tar
rpm -ivh MySQL-server-5.5.40-1.linux2.6.x86_64.rpm
rpm -ivh MySQL-client-5.5.40-1.linux2.6.x86_64.rpm
#有个会报错卸载掉相关依赖rpm -e xxxxxxxxxx --nodeps
配置
# 启动服务
systemctl start mysql
# 修改MySQL密码
/usr/bin/mysqladmin -u root password 'root'
# 登陆MySQL设置权限
mysql -uroot -proot
update mysql.user set host='%' where host='localhost';
delete from mysql.user where host<>'%' or user='';
flush privileges;
改utf8
cd /usr/share/mysql
cp my-small.cnf /etc/my.cnf
vim /etc/my.cnf
#----------------
[mysqlid]
#这下面添加一行
character_set_server=utf8
Hadoop安装
解压、安装
tar zxvf hadoop-3.2.1.tar.gz -C /opt/software
ln -s /opt/software/hadoop-3.2.1/ /opt/software/hadoop
配置
配置core-site.xml
vim core-site.xml
-------------------------------------------
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/software/hadoop/data</value>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
</configuration>
-------------------------------------------
配置hdfs-site.xml
vim hdfs-site.xml
-------------------------------------------
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>slave1:9868</value>
</property>
</configuration>
-------------------------------------------
配置mapred-site.xml
vim mapred-site.xml
-------------------------------------------
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
</configuration>
-------------------------------------------
配置yarn-site.xml
vim yarn-site.xml
-------------------------------------------
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>slave2</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>512</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>4096</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>4096</value>
</property>
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://${yarn.timeline-service.webapp.address}/applicationhistory/logs</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<property>
<name>yarn.timeline-service.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.timeline-service.hostname</name>
<value>${yarn.resourcemanager.hostname}</value>
</property>
<property>
<name>yarn.timeline-service.http-cross-origin.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.system-metrics-publisher.enabled</name>
<value>true</value>
</property>
</configuration>
-------------------------------------------
配置hadoop-env.sh
vim hadoop-env.sh
-------------------------------------------
export JAVA_HOME=/opt/software/java
-------------------------------------------
配置mapred-env.sh
vim mapred-env.sh
-------------------------------------------
export JAVA_HOME=/opt/software/java
-------------------------------------------
配置yarn-env.sh
vim yarn-env.sh
-------------------------------------------
export JAVA_HOME=/opt/software/java
-------------------------------------------
配置works
vim works
-------------------------------------------
master
slave1
slave2
-------------------------------------------
添加变量
vim /etc/profile.d/myenv.sh
------------------------------------------------
export HADOOP_HOME=/opt/software/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
------------------------------------------------
#两个配置文件都需要配置
vim $HADOOP/sbin/start-dfs.sh
vim $HADOOP/sbin/stop-dfs.sh
------------------------------------------------
HDFS_NAMENODE_USER=root
HDFS_DATANODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
YARN_RESOURCEMANAGER_USER=root
YARN_NODEMANAGER_USER=root
------------------------------------------------
vim $HADOOP/sbin/start-yarn.sh
vim $HADOOP/sbin/stop-yarn.sh
------------------------------------------------
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
------------------------------------------------
分发给slave
scp -r $hadoop slave:$PWD
scp -r $hadoop slave:$PWD
HDFS格式化
hdfs namenode -format
启动Hadoop服务
# 启动HDFS
$HADOOP_HOME/sbin/start-dfs.sh
# 启动yarn
$HADOOP_HOME/sbin/start-yarn.sh
# 启动历史服务器
mapred --daemon start historyserver
Hive安装
解压、安装
tar zxvf /opt/download/apache-hive-3.1.2-bin.tar.gz -C /opt/software/
ln -s /opt/software/apache-hive-3.1.2-bin/ /opt/software/hive
配置
# 进入路径
cd /opt/software/hive/conf/
修改hive-site.xml
cp hive-default.xml.template hive-site.xml
vim hive-site.xml
-------------------------------------------
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://master:3306/metastore?createDatabaseIfNotExist=true&useUnicode=true&characterEncoding=UTF-8</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<property>
<name>hive.metastore.uris</name>
<value>thrift://master:9083</value>
</property>
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
<property>
<name>hive.server2.thrift.bind.host</name>
<value>master</value>
</property>
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
</configuration>
-------------------------------------------
修改hive-env.sh
cp hive-env.sh.template hive-env.shvim hive-env.sh
-------------------------------------------
HADOOP_HOME=/opt/software/hadoop
-------------------------------------------
添加依赖包
cp /opt/download/mysql-connector-java-5.1.31.jar /opt/software/hive/lib/
添加环境变量
vim /etc/profile.d/myenv.sh
------------------------------------------------
export HIVE_HOME=/opt/software/hive
export PATH=$HIVE_HOME/bin:$PATH
------------------------------------------------
启动服务
# 初始化元数据表
schematool -dbType mysql -initSchema
# 启动hiveserver2服务
nohup hive --service metastore>/dev/null 2>&1 &
nohup hive --service hiveserver2>/dev/null 2>&1 &
#############报错 Exception in thread "main" java.lang.NoSuchMethodError
################
# jar 包冲突, 需要删除低版本包
rm -rf /opt/software/hive/lib/guava-19.0.jar
cp /opt/software/hadoop/share/hadoop/common/lib/guava-27.0-jre.jar /opt/software/hive/lib/
连接hive
beeline -u jdbc:hive2://master:10000 -n root -p 0000 --color=true
Zookeeper安装
解压、安装
tar -zxvf apache-zookeeper-3.6.1-bin.tar.gz -C /opt/softwareln -s apache-zookeeper-3.6.1-bin zookeeper
配置
创建zkdata zklogs
#在/opt/software/zookeeper下创建文件夹
mkdir zkdata zklogs
配置zoo.cfg
cd conf/mv zoo_sample.cfg zoo.cfg
vi zoo.cfg
#修改:
dataDir=/usr/software/zookeeper/zkdata
#末尾添加:
dataLogDir=/usr/software/zookeeper/zklogs/
server.1=master:2888:3888
server.2=slave1:2888:3888
server.3=slave2:2888:3888
分发给slave
scp -r $zookeeper slave1:$PWD
scp -r $zookeeper slave2:$PWD
创建myid
cd $zookeeper/zkdatamkdir myid
#master 1
#slave1 2
#slave2 3
myid里面存放的内容就是服务器的id,就是server.1=master:2888:3888当中的id, 就是1。
配置环境变量
export ZK_HOME=/usr/software/zookeeperexport PATH=$PATH:$ZK_HOME/bin
启动
#启动
zkServer.sh start
#查看状态
zkServer.sh status
#关闭
zkServer.sh stop
Kafka安装
解压、安装
tar -zxvf kafka_2.12-2.7.0.tgz -C /opt/software/
ln -s kafka_2.12-2.7.0 kafka
配置
修改server.properties
broker.id=0
#从0 开始,0 1 2
delete.topic.enable=true #这条在文件中没有,手动添加,默认主题不允许删除
listeners=PLAINTEXT://master:9092log.dirs=/usr/software/kafka/kafka-logs# 数据存放的目录,会自动生成,不需要创建
zookeeper.connect=master:2181,slave1:2181,slave2:2181
分发给slave
scp -r $kafka slave1:$PWDscp -r $kafka slave2:$PWD
在其他的节点上,修改broker.id 和listeners 中的主机名。
配置环境变量
export KAFKA_HOME=/opt/software/kafkaexport PATH=$KAFKA_HOME/bin:$PATH
启动
#启动
kafka-server-start.sh
#以后台守护进程启动:
kafka-server-start.sh -daemon /usr/software/kafka/config/server.properties
#关闭
kafka-server-stop.sh
Flink安装
解压、安装
tar -zxvf flink-1.13.0-bin-scala_2.12.tgz -C /opt/software/
ln -s flink-1.13.0 flink
配置
配置 vim masters
master:8081slave1:8081
配置 vim workers
masterslave1slave2
配置 flink-conf.yaml
#修改
jobmanager.rpc.address: master
#最后添加
state.backend: filesystem
state.backend.fs.checkpointdir: hdfs://master:9000/flink-checkpoints
high-availability: zookeeper
high-availability.storageDir: hdfs://master:9000/flink/ha/
high-availability.zookeeper.quorum: master:2181,slave1:2181,slave2:2181
分发到slave
scp -r flink-1.13.0 slave1:$PWD
scp -r flink-1.13.0 slave2:$PWD
修改slave1上的jobmanager 通信地址
vim flink-conf.yaml
#--------------------- ↓这里要有空格!!
jobmanager.rpc.address: slave1
将flink-shaded-hadoop-2-uber-2.7.5-10.0.jar 拷贝到flink的lib目录下
配置环境变量
export FLINK_HOME=/o/software/flinkexport PATH=$PATH:$FLINK_HOME/bin
启动服务
start-cluster.sh

















 2241
2241

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









