



一、Linux文本三剑客---grep、sed、awk
4.awk内置变量
-
FS :输入字段分隔符,默认为空白字符
-
OFS :输出字段分隔符,默认为空白字符
-
RS :输入记录分隔符,指定输入时的换行符,原换行符仍有效
-
ORS :输出记录分隔符,输出时用指定符号代替换行符
-
NF :字段数量,共有多少字段, $NF引用最后一列,$(NF-1)引用倒数第2列
-
NR :行号,后可跟多个文件,第二个文件行号继续从第一个文件最后行号开始
-
FNR :各文件分别计数, 行号,后跟一个文件和NR一样,跟多个文件,第二个文件行号从1开始
-
FILENAME :当前文件名
-
ARGC :命令行参数的个数
-
ARGV :数组,保存的是命令行所给定的各参数,查看参数
5.高阶用法
(4)显示每一行的每个单词和其长度
[root@along ~]# awk -F: '{for(i=1;i<=NF;i++) {print$i,length($i)}}' awkdemo
hello 5
world 5
linux 5
redhat 6
lalala 6
hahaha 6
along 5
love 4
you 3
---求男m、女f各自的平均
#NF:列数 横向处理
(6)去重
[root@along ~]# cat awkdemo2
aaa
bbbb
aaa
123
123
123
---去除重复的行 走到第一行,$0就是第一行,然后取出aaa放入数组,在数组中无值,就取不出来,为假(0),进行取反,0变1,awk为真的数据会打印。
[root@along ~]# awk '!arr[$0]++' awkdemo2
aaa
bbbb
123
可以去重,是key不是value
---打印文件内容,和该行重复第几次出现 取反不会影响数组中的值,只有再++的时候值才会改变
第一次进来false,取反true,(++,加完一以后往下走一行才打印),打印了aaa 1,aaa再过来时,取反成负数,不影响值,值还是1,往下走成2(等于是在++以后进行统计)
[root@along ~]# awk '{!arr[$0]++;print $0,arr[$0]}' awkdemo2
aaa 1
bbbb 1
aaa 2
123 1
123 2
123 3
分析:arr['aaa']为假 取反为真 1 aaa=2
arr['aaa']为真,取反为假 0
二、awk经典案例
1.统计TCP连接状态数量
(1)netstat
$ netstat -tnap-t或--tcp:显示TCP传输协议的连线状况;
-n或--numeric:直接使用ip地址,而不通过域名服务器;
-a或--all:显示所有连线中的Socket;
-p或--programs:显示正在使用Socket的程序识别码和程序名称;
(2)相关命令
netstat -antp | awk '{arr[$6]++}END{for (i in arr){print arr[i], i}}'
netstat -antp | grep 'tcp' | awk '{print $6}' | sort | uniq -cnetstat -tna | awk '/^tcp/{arr[$6]++}END{for(state in arr){print arr[state] ": " state}}'
netstat -tna | /usr/bin/grep 'tcp' | awk '{print $6}' | sort | uniq -c(3)实例
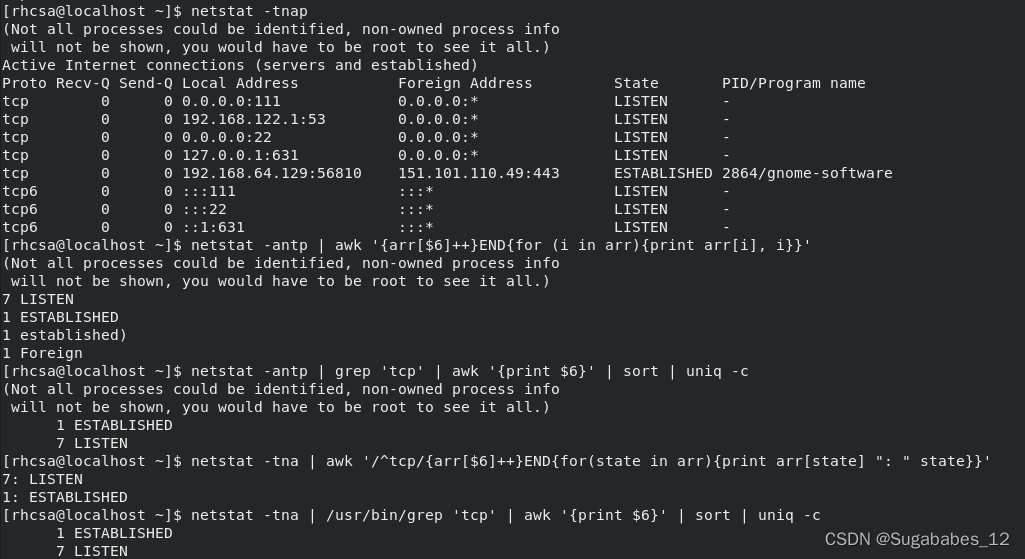
2.筛选给定时间范围内的日志
(1)mktime函数
grep/sed/awk用正则去筛选日志时,如果要精确到小时、分钟、秒,则非常难以实现。
但是awk提供了mktime()函数,它可以将时间转换成epoch时间值。
# 2019-11-10 03:42:40转换成epoch为1970-01-01 00:00:00
$ awk 'BEGIN{print mktime("2019 11 10 03 42 40")}'

借此,可以取得日志中的时间字符串部分,再将它们的年、月、日、时、分、秒都取出来,然后放入mktime()构建成对应的epoch值。因为epoch值是数值,所以可以比较大小,从而决定时间的大小。
(2) epoch
UNIX及Linux的时间系统是由「新纪元时间」Epoch开始计算起,单位为秒,Epoch则是指定为1970年一月一日凌晨零点零分零秒,格林威治时间。
目前大部份的UNIX系统都是用32位元来记录时间,正值表示为1970以後,负值则表示1970年以前。我们可以很简单地计算出其时间领域:
2^31/86400(s) = 24855.13481(天) ~ 68.0958(年)
1970+68.0958 = 2038.0958
1970-68.0958 = 1901.9042
时间领域为[1901.9042,2038.0958]。
(3)实例分析
将2022-12-02T00:00:00+08:00格式的字符串转换成epoch值,然后和which_time比较大小即可筛选出精确到秒的日志。
BEGIN{
# 要筛选什么时间的日志,将其时间构建成epoch值
which_time = mktime("2022 12 02 00 00 00")
}
{
# 取出日志中的日期时间字符串部分
match($0,"^.*\\[(.*)\\].*",arr)
# 将日期时间字符串转换为epoch值
tmp_time = strptime2(arr[1])
# 通过比较epoch值来比较时间大小
if(tmp_time > which_time){
print
}
}
# 构建的时间字符串格式为:"02/Dec/2022:00:00:00+08:00"
function strptime2(str,dt_str,arr,Y,M,D,H,m,S) {
dt_str = gensub("[/:+]"," ","g",str)
split(dt_str,arr," ")
Y=arr[3]
M=mon_map(arr[2])
D=arr[1]
H=arr[4]
m=arr[5]
S=arr[6]
return mktime(sprintf("%s %s %s %s %s %s",Y,M,D,H,m,S))
}
function mon_map(str,mons){
mons["Jan"]=1
mons["Feb"]=2
mons["Mar"]=3
mons["Apr"]=4
mons["May"]=5
mons["Jun"]=6
mons["Jul"]=7
mons["Aug"]=8
mons["Sep"]=9
mons["Oct"]=10
mons["Nov"]=11
mons["Dec"]=12
return mons[str]
}①代码分析
a:awk全局替换函数(gsub/gensub)
gsub 是 AWK 中的一个函数,用于全局替换字符串中的子字符串。以下是 gsub 函数的语法:
gsub(regexp, replacement, target)
其中,regexp 表示要替换的字符串模式,可以是一个正则表达式;replacement 表示替换目标字符串的新内容;target 表示要操作的目标字符串。
gsub 函数会在 target 字符串中查找并替换所有与 regexp 匹配的子字符串,将其替换为 replacement 指定的内容,并返回替换的次数。如果 target 字符串中不存在与 regexp 匹配的子字符串,则 gsub 不进行任何操作,直接返回 0。
以下是一个示例:
$ echo "abracadabra" | awk '{gsub("a", "o"); print}'
obrocodobro
在这个例子中,我们将 gsub 函数应用于字符串 "abracadabra"。"a" 是被替换的目标字符串模式,"o" 是替换后的新内容。因此,gsub 函数将在字符串中查找所有的 "a",并将它们替换为 "o",最终输出结果为 "obrocodobro"。
b:awk 将日期时间字符串转换为时间:strptime2 ()
strftime([format [, timestamp [, utc-flag] ] ]):将时间按指定格式转换为字符串并返回转的结果 字符串
strptime2()函数转为 epoch值
c:mktime函数将日期时间信息转换为 epoch 值,方便直接比较时间了
d:match函数匹配正则表达式,取出日志中的日期时间字符串部分
e:函数内部通过 gensub函数匹配正则,将 “/ : +”替换成空格
f:使用 split函数,将字符串按照空格分隔,保存在 arr数组
g:mon_map函数,将月份的英文转换为数字,返回 mktime函数处理后的 epoch值


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









