







MusicGen: 基于文本和音频提示的高质量音乐生成模型
MusicGen是一个强大的音乐生成模型,由Meta AI的Jade Copet等研究人员提出,旨在通过文本描述或音频提示生成高质量的音乐样本。该模型的详细内容可以参考相关论文《简单且可控的音乐生成》(链接)。与传统的音乐生成方法不同,MusicGen在模型架构和训练策略上做了显著改进,以提高音乐生成的质量和速度。
模型概览
MusicGen模型分为三个关键阶段:
- 文本编码:将输入的文本描述通过一个冻结的文本编码模型编码,以生成隐藏状态表示。这些隐藏状态用于捕捉音乐的情绪、风格和内容。
- 音频标记预测:MusicGen解码器在这些隐藏状态的条件下被训练来预测离散的音频标记(音频代码),从而生成音乐序列。与传统的逐层或上采样生成方式不同,MusicGen采用了一种称为标记交错模式的策略,从而在单次前向传递中生成完整的音频代码集,大幅提升了生成效率。
- 音频解码:这些音频代码随后通过一个音频压缩模型(例如EnCodec)解码为可播放的音频波形。
预训练模型与组件
预训练的MusicGen模型使用了以下组件:
- 文本编码模型:MusicGen使用Google的t5-base作为文本编码器,将输入的文本描述转换为隐含的语义表示。
- 音频压缩模型:使用EnCodec 32kHz对音频进行编码和解码,以实现高效的音频存储和还原。
- MusicGen解码器:这是一个自定义的语言模型,专门用于从音频代码生成完整音乐波形。
标记交错模式
传统的音乐生成模型在预测音频代码时往往采用分层预测或上采样的策略。然而,这些方法通常需要多层模型的级联或不断精炼Transformer模型的输出,因而在推理速度上存在瓶颈。MusicGen创新性地采用了标记交错模式,通过在单次前向传递中并行生成完整的音频代码集,避免了级联多个模型的需求,显著提升了推理速度。这种模式极大地优化了生成效率,使得MusicGen在实际应用中更具可操作性。
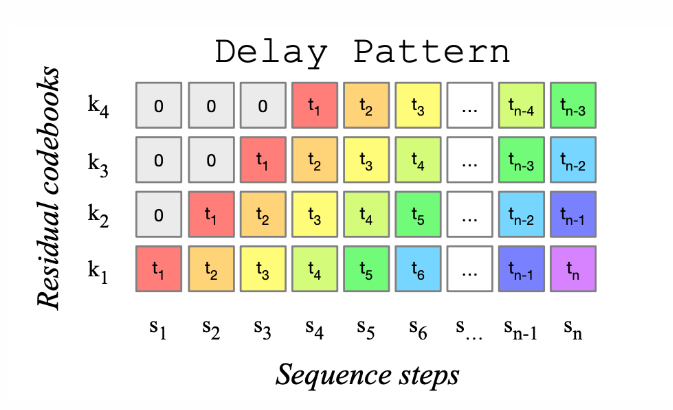
图1: MusicGen使用的代码本延迟模式。图取自MusicGen论文arxiv上的230605284。
模型加载
预训练的MusicGen模型检查点(小型、中型和大型)可以从hf-hub加载。以下代码展示了如何加载小型检查点:
from mindnlp.transformers import MusicgenForConditionalGeneration
model = MusicgenForConditionalGeneration.from_pretrained("facebook/musicgen-small")
音乐生成模式
MusicGen支持两种生成模式:贪婪生成和采样生成。相比贪婪生成,采样生成在音乐生成任务上通常能够获得更好的结果,因而更受推荐。在实际应用中,我们鼓励在可能的情况下启用采样模式(do_sample=True)。
无条件生成
无条件生成即不输入任何文本提示,通过随机采样生成音乐。可以使用get_unconditional_inputs方法获取无条件输入,随后调用generate方法生成音乐。
unconditional_inputs = model.get_unconditional_inputs(num_samples=1)
audio_values = model.generate(**unconditional_inputs, do_sample=True, max_new_tokens=256)
音频输出是一个三维的Torch张量,形状为(batch_size, num_channels, sequence_length)。可以通过IPython.display.Audio在Jupyter Notebook中播放生成的音频。
from IPython.display import Audio
sampling_rate = model.config.audio_encoder.sampling_rate
Audio(audio_values[0].asnumpy(), rate=sampling_rate)
文本条件生成
MusicGen可以根据文本描述生成条件音频样本,例如“80年代的流行音乐”或“充满低音的电子音乐”。这通过MusicgenProcessor对输入进行预处理,然后传入.generate方法进行生成。
from mindnlp.transformers import AutoProcessor
processor = AutoProcessor.from_pretrained("facebook/musicgen-small")
inputs = processor(
text=["80s pop track with bassy drums and synth", "90s rock song with loud guitars and heavy drums"],
padding=True,
return_tensors="ms",
)
audio_values = model.generate(**inputs, do_sample=True, guidance_scale=3, max_new_tokens=256)
Audio(audio_values[0].asnumpy(), rate=sampling_rate)
分类器自由引导(CFG):生成过程中,可以通过guidance_scale参数控制生成样本与文本描述的相关性。较高的guidance_scale值会使生成结果更贴合输入描述,但可能以牺牲音频质量为代价。一般推荐值为3,较高的值可用于对特定提示生成更准确的结果。
音频提示生成
MusicGen还支持根据已有音频片段进行扩展,即“音频续写”模式。在此模式下,模型通过已有音频片段的特征信息来生成风格一致的扩展音乐片段。例如,我们可以使用🤗 Datasets库加载一个音频文件,并对其进行续写生成。
from mindnlp.dataset import load_dataset
dataset = load_dataset("sanchit-gandhi/gtzan", split="train", streaming=True)
sample = next(iter(dataset.create_dict_iterator(output_numpy=True)))["audio"]
# 使用前半段作为提示
sample["array"] = sample["array"][: len(sample["array"]) // 2]
inputs = processor(
audio=sample["array"],
sampling_rate=sample["sampling_rate"],
text=["80s blues track with groovy saxophone"],
padding=True,
return_tensors="ms",
)
audio_values = model.generate(**inputs, do_sample=True, guidance_scale=3, max_new_tokens=256)
Audio(audio_values[0].asnumpy(), rate=sampling_rate)
批量生成与填充处理
MusicGen支持批量处理不同长度的音频提示。输入音频会在传递给模型前自动填充到相同长度,生成后可通过处理器类去除填充部分。
sample_1 = sample["array"][: len(sample["array"]) // 4]
sample_2 = sample["array"][: len(sample["array"]) // 2]
inputs = processor(
audio=[sample_1, sample_2],
sampling_rate=sample["sampling_rate"],
text=["80s blues track with groovy saxophone", "90s rock song with loud guitars and heavy drums"],
padding=True,
return_tensors="ms",
)
audio_values = model.generate(**inputs, do_sample=True, guidance_scale=3, max_new_tokens=256)
# 去除填充后的音频
audio_values = processor.batch_decode(audio_values, padding_mask=inputs.padding_mask)
Audio(audio_values[0], rate=sampling_rate)

生成配置
MusicGen的生成过程可以通过多个参数进行微调,如采样模式、引导比例和生成的标记数量。生成配置保存在generation_config中,可以根据需要进行更新:
model.generation_config.guidance_scale = 4.0
model.generation_config.max_new_tokens = 256
model.generation_config.temperature = 1.5
重新调用generate方法时将使用更新后的配置:
audio_values = model.generate(**inputs)
配置优先级
传递给generate方法的参数将优先于生成配置中的设置。例如,若在调用generate时设置do_sample=False,即使model.generation_config.do_sample=True,生成过程仍会以贪婪模式执行。
总结
MusicGen是一个功能强大且灵活的音乐生成模型,能够根据文本或音频提示生成高质量的音乐样本。其高效的标记交错模式、分类器自由引导和批量处理能力,使其在生成音乐片段时既快又准确。无论是用于创意音乐生成还是音频续写,MusicGen都展示了极高的潜力。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











