







 代码示例展示了如何加载两个不同版本的GPT-2模型到PyTorch设备上,并设置为评估模式。在运行过程中,模型的配置文件和权重被下载,这些文件通常用于训练后的推理任务。此外,讨论了模型的保存和缓存机制。
代码示例展示了如何加载两个不同版本的GPT-2模型到PyTorch设备上,并设置为评估模式。在运行过程中,模型的配置文件和权重被下载,这些文件通常用于训练后的推理任务。此外,讨论了模型的保存和缓存机制。
运行代码: model1 = GPT2LMHeadModel.from_pretrained(‘gpt2-xl’, return_dict=True).to(device) model1.config.pad_token_id = model1.config.eos_token_id model2 = GPT2LMHeadModel.from_pretrained(‘gpt2’, return_dict=True).to(device) model1.eval() model2.eval() 显示一串内容 n:0 total:689 elapsed:0.03336215019226074 ncols:null nrows:null prefix:“Downloading (…)lve/main/config.json” ascii:false unit:“B” unit_scale:true rate:null bar_format:null postfix:null unit_divisor:1000 initial:0 colour:null Filter… n:0 total:6431878936 elapsed:0.033989667892456055 ncols:null nrows:null prefix:“Downloading (…)“pytorch_model.bin”;” ascii:false unit:“B” unit_scale:true rate:null bar_format:null postfix:null unit_divisor:1000 initial:0 colour:null 是什么意思?
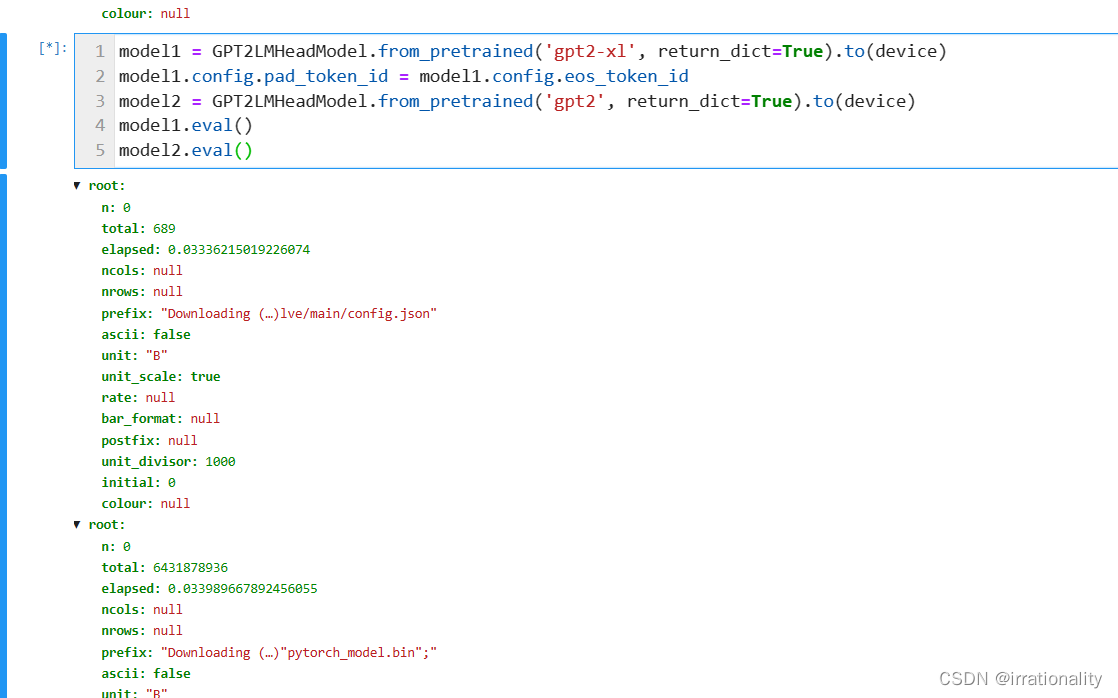
代码是用来加载两个预训练的 GPT-2 模型,并将它们设置为评估模式。GPT-2 是一个自回归语言模型,可以生成文本¹²³。
显示一串内容是你的代码运行时的输出,它显示了你正在下载两个模型的配置文件和权重文件,以及下载进度和速度⁴⁵。
这些模型会被下载到你的缓存目录中,你可以通过设置 TORCH_HOME 环境变量来指定这个目录³。你也可以用 torch.save() 函数来保存模型的状态字典,这样可以方便地恢复模型²。一般来说,PyTorch 的惯例是用 .pt 或 .pth 文件扩展名来保存模型²。
用find命令也可以查找




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











