











前言
前有文章讲解了
fixture函数中使用ids参数给测试用例函数设置别名;
查漏补缺连接:待定
当使用@pytest.mark.parametrize来参数化我们的测试函数时,也可以使用ids参数为每个参数组合指定一个唯一的标识符,这个标识符被称为id或别名。这个
id用于在测试报告中标识每个单独的测试实例,使得测试报告更具可读性。
使用ids参数设置别名
示例代码
import pytest
params = ["username", "password"]
values = [["admin", "admin"], ["guest", "guest"]]
agname = ["管理员用户:admin", "游客用户:guest"]
@pytest.mark.parametrize(argnames=params, argvalues=values, ids=agname)
def test_case_01(username, password):
print(f"username={username}, username={password}")
执行结果
在
Python中,字符串的编码默认是UTF-8。但是,在某些环境或编辑器中,如果不正确地处理或显示
UTF-8编码的字符串,可能会出现乱码。当在
pytest的@pytest.mark.parametrize中使用中文别名时,乱码问题可能会出现,特别是当环境或测试报告生成工具不支持或错误处理UTF-8编码时。
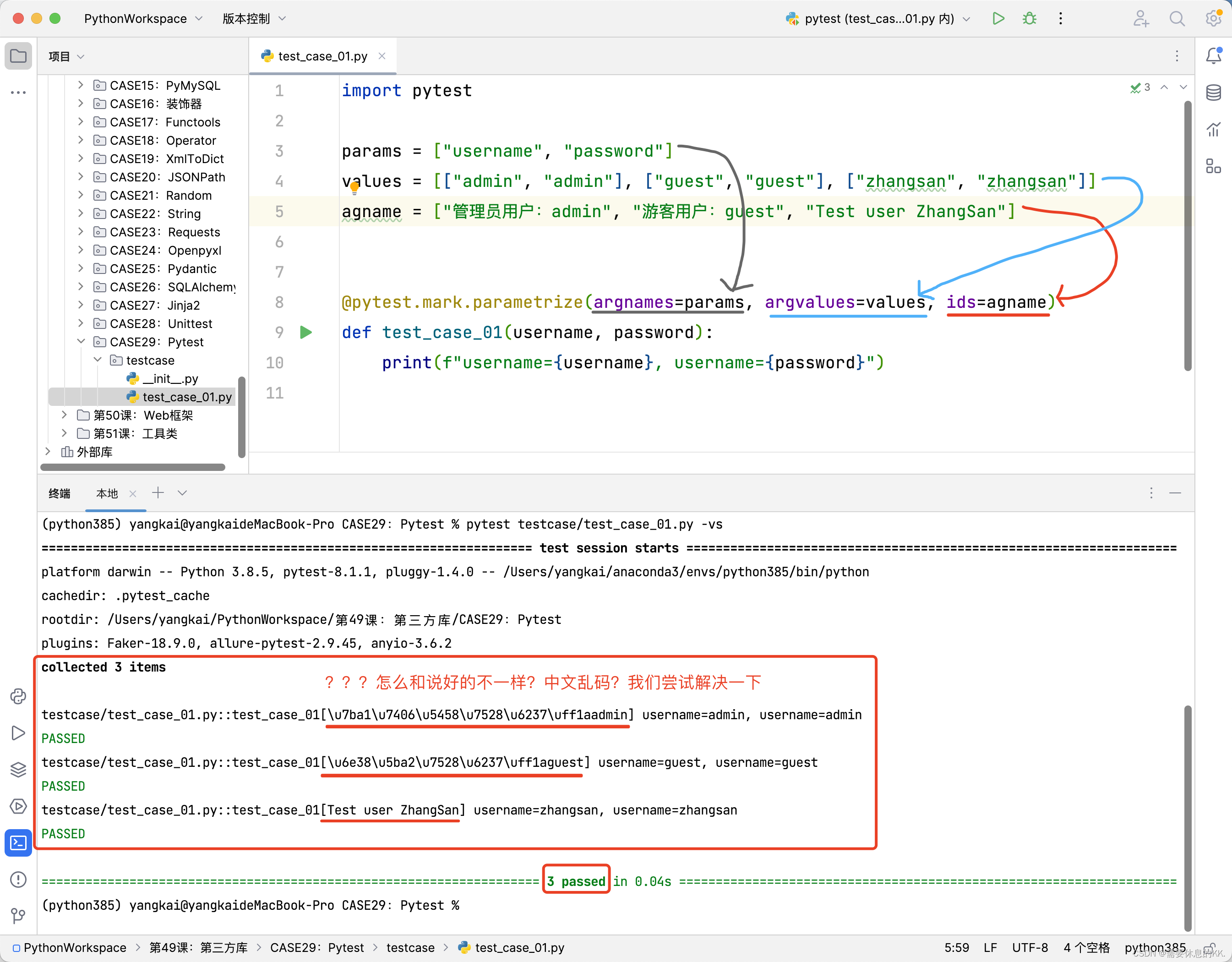
解决别名乱码方式一
conftest.py文件添加如下代码
def pytest_collection_modifyitems(items):
"""pytest_collection_modifyitems 是pytest中的一个hook函数(内置的)
是为了在测试用例收集完成后对测试项的 name 和 nodeid 进行处理,
以确保它们在控制台上的显示是正确的。
这段代码通过编码和解码操作来处理中文字符,从而解决了可能出现的乱码问题。"""
print('\n')
for item in items:
print("处理前的测试用例名称", item.name)
print("处理前的测试用例节点", item._nodeid)
item.name = item.name.encode("utf-8").decode("unicode_escape")
item._nodeid = item.nodeid.encode("utf-8").decode("unicode_escape")
执行结果
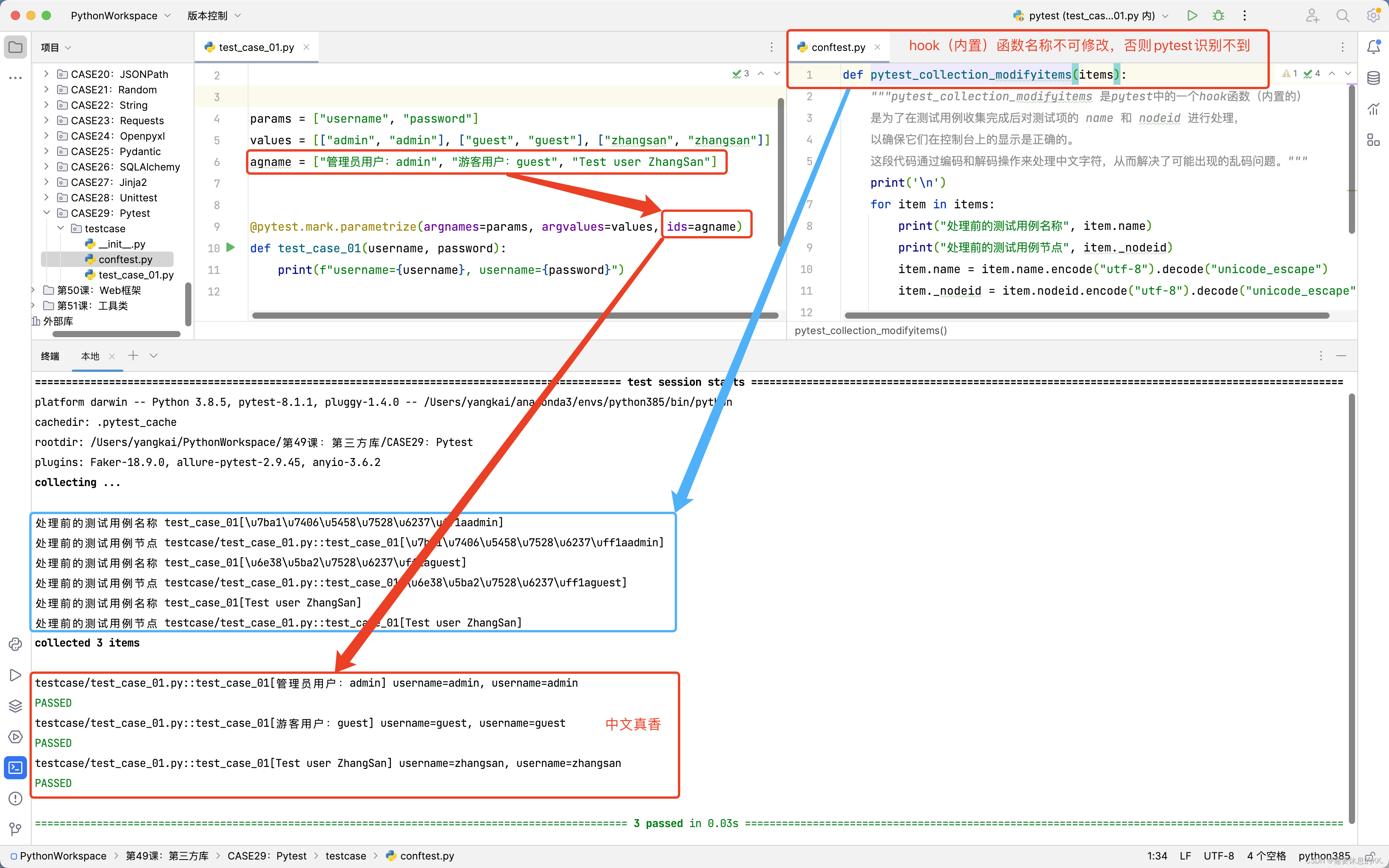
解决别名乱码方式二
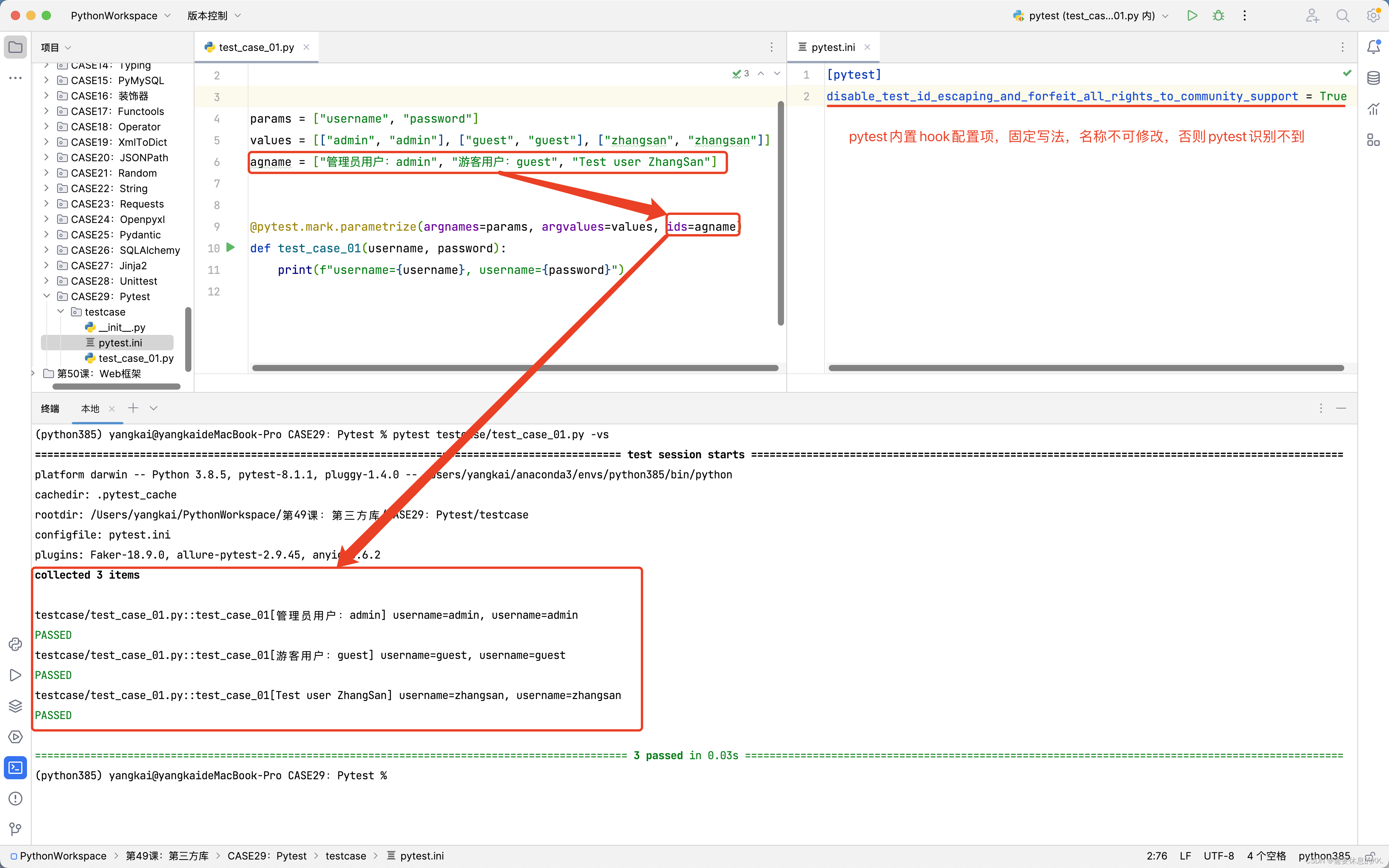
在
pytest.ini配置文件中添加如下代码这个配置项的目的是禁止
pytest对测试ID(通常是通过@pytest.mark.parametrize的ids参数设置的)中的特殊字符(如非ASCII字符)进行转义。默认情况下,
pytest会对测试ID中的特殊字符进行转义,以确保它们可以在命令行和测试报告中正确显示。然而,在某些情况下,特别是当控制台或终端的字符编码设置不正确时,这种转义可能会导致乱码。
[pytest]
disable_test_id_escaping_and_forfeit_all_rights_to_community_support = True
执行结果



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











