









SpringBoot整合Datax数据同步
文章目录
1.简介
DataX 是阿里云 DataWorks数据集成 的开源版本,在阿里巴巴集团内被广泛使用的离线数据同步工具/平台。DataX 实现了包括 MySQL、Oracle、OceanBase、SqlServer、Postgre、HDFS、Hive、ADS、HBase、TableStore(OTS)、MaxCompute(ODPS)、Hologres、DRDS, databend 等各种异构数据源之间高效的数据同步功能。
DataX 是一个异构数据源离线同步工具,致力于实现各种异构数据源之间稳定高效的数据同步功能。
Download DataX下载地址
Github主页地址:https://github.com/alibaba/DataX
请点击:Quick Start
-
设计理念
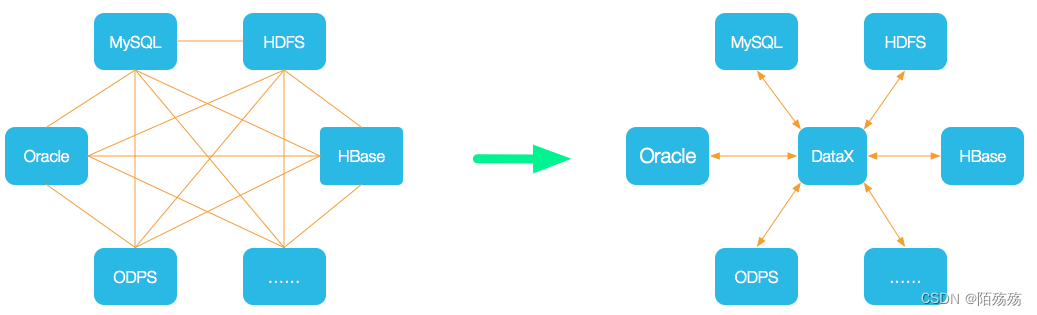
为了解决异构数据源同步问题,DataX将复杂的网状的同步链路变成了星型数据链路,DataX作为中间传输载体负责连接各种数据源。当需要接入一个新的数据源的时候,只需要将此数据源对接到DataX,便能跟已有的数据源做到无缝数据同步。
DataX3.0框架设计

DataX本身作为离线数据同步框架,采用Framework + plugin架构构建。将数据源读取和写入抽象成为Reader/Writer插件,纳入到整个同步框架中。
- Reader:Reader为数据采集模块,负责采集数据源的数据,将数据发送给Framework。
- Writer: Writer为数据写入模块,负责不断向Framework取数据,并将数据写入到目的端。
- Framework:Framework用于连接reader和writer,作为两者的数据传输通道,并处理缓冲,流控,并发,数据转换等核心技术问题。
DataX3.0核心架构
DataX 3.0 开源版本支持单机多线程模式完成同步作业运行,本小节按一个DataX作业生命周期的时序图,从整体架构设计非常简要说明DataX各个模块相互关系。
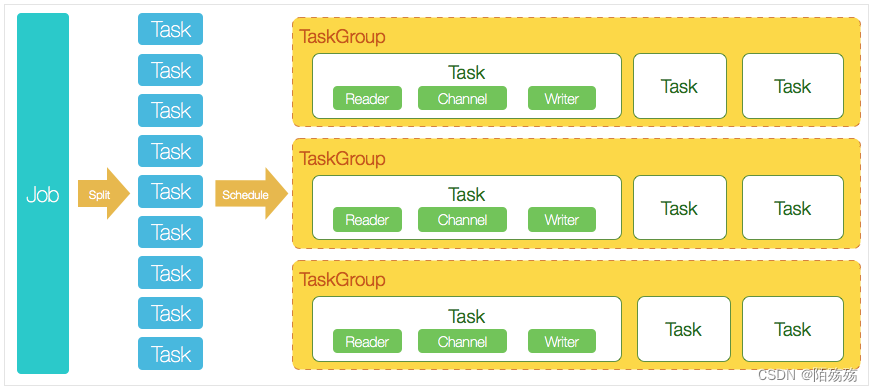
核心模块介绍
- DataX完成单个数据同步的作业,我们称之为Job,DataX接受到一个Job之后,将启动一个进程来完成整个作业同步过程。DataX Job模块是单个作业的中枢管理节点,承担了数据清理、子任务切分(将单一作业计算转化为多个子Task)、TaskGroup管理等功能。
- DataXJob启动后,会根据不同的源端切分策略,将Job切分成多个小的Task(子任务),以便于并发执行。Task便是DataX作业的最小单元,每一个Task都会负责一部分数据的同步工作。
- 切分多个Task之后,DataX Job会调用Scheduler模块,根据配置的并发数据量,将拆分成的Task重新组合,组装成TaskGroup(任务组)。每一个TaskGroup负责以一定的并发运行完毕分配好的所有Task,默认单个任务组的并发数量为5。
- 每一个Task都由TaskGroup负责启动,Task启动后,会固定启动Reader—>Channel—>Writer的线程来完成任务同步工作。
- DataX作业运行起来之后, Job监控并等待多个TaskGroup模块任务完成,等待所有TaskGroup任务完成后Job成功退出。否则,异常退出,进程退出值非0
DataX调度流程
举例来说,用户提交了一个DataX作业,并且配置了20个并发,目的是将一个100张分表的mysql数据同步到odps里面。 DataX的调度决策思路是:
- DataXJob根据分库分表切分成了100个Task。
- 根据20个并发,DataX计算共需要分配4个TaskGroup。
- 4个TaskGroup平分切分好的100个Task,每一个TaskGroup负责以5个并发共计运行25个Task。
2.DataX3.0插件体系
DataX目前已经有了比较全面的插件体系,主流的RDBMS数据库、NOSQL、大数据计算系统都已经接入,目前支持数据如下图,详情请点击:DataX数据源参考指南
| 类型 | 数据源 | Reader(读) | Writer(写) | 文档 |
|---|---|---|---|---|
| RDBMS 关系型数据库 | MySQL | √ | √ | 读 、写 |
| Oracle | √ | √ | 读 、写 | |
| OceanBase | √ | √ | 读 、写 | |
| SQLServer | √ | √ | 读 、写 | |
| PostgreSQL | √ | √ | 读 、写 | |
| DRDS | √ | √ | 读 、写 | |
| Kingbase | √ | √ | 读 、写 | |
| 通用RDBMS(支持所有关系型数据库) | √ | √ | 读 、写 | |
| 阿里云数仓数据存储 | ODPS | √ | √ | 读 、写 |
| ADB | √ | 写 | ||
| ADS | √ | 写 | ||
| OSS | √ | √ | 读 、写 | |
| OCS | √ | 写 | ||
| Hologres | √ | 写 | ||
| AnalyticDB For PostgreSQL | √ | 写 | ||
| 阿里云中间件 | datahub | √ | √ | 读 、写 |
| SLS | √ | √ | 读 、写 | |
| 图数据库 | 阿里云 GDB | √ | √ | 读 、写 |
| Neo4j | √ | 写 | ||
| NoSQL数据存储 | OTS | √ | √ | 读 、写 |
| Hbase0.94 | √ | √ | 读 、写 | |
| Hbase1.1 | √ | √ | 读 、写 | |
| Phoenix4.x | √ | √ | 读 、写 | |
| Phoenix5.x | √ | √ | 读 、写 | |
| MongoDB | √ | √ | 读 、写 | |
| Cassandra | √ | √ | 读 、写 | |
| 数仓数据存储 | StarRocks | √ | √ | 读 、写 |
| ApacheDoris | √ | 写 | ||
| ClickHouse | √ | √ | 读 、写 | |
| Databend | √ | 写 | ||
| Hive | √ | √ | 读 、写 | |
| kudu | √ | 写 | ||
| selectdb | √ | 写 | ||
| 无结构化数据存储 | TxtFile | √ | √ | 读 、写 |
| FTP | √ | √ | 读 、写 | |
| HDFS | √ | √ | 读 、写 | |
| Elasticsearch | √ | 写 | ||
| 时间序列数据库 | OpenTSDB | √ | 读 | |
| TSDB | √ | √ | 读 、写 | |
| TDengine | √ | √ | 读 、写 |
3.数据同步
1.编写job的json文件
mysql数据抽取到本地内存
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": [
"id",
"name",
"amount",
],
"connection": [
{
"jdbcUrl": [
"jdbc:mysql://127.0.0.1:3306/datax?characterEncoding=UTF-8&serverTimezone=Asia/Shanghai"
],
"table": [
"user"
]
}
],
"password": "root",
"username": "root"
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"print": false,
"encoding": "UTF-8"
}
}
}
],
"setting": {
"speed": {
"channel": "1"
}
}
}
}
mysqlWriter数据写入
{
"job": {
"setting": {
"speed": {
"channel": 1
}
},
"content": [
{
"reader": {
"name": "streamreader",
"parameter": {
"column" : [
{
"value": "DataX",
"type": "string"
},
{
"value": 19880808,
"type": "long"
},
{
"value": "1988-08-08 08:08:08",
"type": "date"
},
{
"value": true,
"type": "bool"
},
{
"value": "test",
"type": "bytes"
}
],
"sliceRecordCount": 1000
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"writeMode": "insert",
"username": "root",
"password": "root",
"column": [
"id",
"name"
],
"session": [
"set session sql_mode='ANSI'"
],
"preSql": [
"delete from test"
],
"connection": [
{
"jdbcUrl": "jdbc:mysql://127.0.0.1:3306/datax?useUnicode=true&characterEncoding=gbk",
"table": [
"test"
]
}
]
}
}
}
]
}
}
mysql数据同步
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": [
"id",
"project_code",
"category"
],
"connection": [
{
"jdbcUrl": [
"jdbc:mysql://127.0.0.1:3306/test_local?characterEncoding=UTF-8&serverTimezone=Asia/Shanghai"
],
"table": [
"project_index"
]
}
],
"password": "root",
"username": "root"
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"column": [
"id",
"project_code",
"category"
],
"connection": [
{
"jdbcUrl": "jdbc:mysql://127.0.0.1:3306/datax?characterEncoding=UTF-8&serverTimezone=Asia/Shanghai",
"table": [
"project_index"
]
}
],
"password": "root",
"username": "root",
"writeMode": "update"
}
}
}
],
"setting": {
"speed": {
"channel": "1"
}
}
}
}
2.进入bin目录下,执行文件
需python环境
python datax.py {YOUR_JOB.json}
4.SpringBoot整合DataX生成Job文件并执行
1.准备工作
下载datax,安装lib下的datax-common和datax-core的jar到本地maven仓库
依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jdbc</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.30</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.54</version>
</dependency>
<dependency>
<groupId>com.alibaba.datax</groupId>
<artifactId>datax-core</artifactId>
<version>0.0.1-SNAPSHOT</version>
</dependency>
<dependency>
<groupId>com.alibaba.datax</groupId>
<artifactId>datax-common</artifactId>
<version>0.0.1-SNAPSHOT</version>
</dependency>
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.8.25</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.21</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.26</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
<version>3.12.0</version>
</dependency>
spring:
datasource:
url: jdbc:mysql://127.0.0.1:3306/test_local?characterEncoding=UTF-8&serverTimezone=Asia/Shanghai
username: root
password: root
driver-class-name: com.mysql.cj.jdbc.Driver
type: com.alibaba.druid.pool.DruidDataSource
server:
port: 8080
# datax 相关配置,在生成文件时使用
datax:
home: D:/software/datax/
# job文件存储位置
save-path: D:/software/datax/job/
属性配置
/**
* datax配置
* @author moshangshang
*/
@Data
@Component
@ConfigurationProperties("datax")
public class DataXProperties {
private String home;
private String savePath;
}
公共实体
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Content {
private Reader reader;
private Writer writer;
}
@Data
public class DataXJobRoot {
private Job job;
}
@Data
public class Job {
private List<Content> content;
private Setting setting = new Setting();
}
@Data
public class Setting {
private Speed speed = new Speed();
@Data
public static class Speed {
private String channel = "1";
}
}
public abstract class Parameter {
}
/**
* 读取抽象类
* @author moshangshang
*/
@Data
public abstract class Reader {
private String name;
private Parameter parameter;
}
/**
* 写入抽象类
* @author moshangshang
*/
@Data
public abstract class Writer {
private String name;
private Parameter parameter;
}
公共处理接口
public interface DataXInterface {
/**
* 获取读对象
*/
Reader getReader(String table);
/**
* 获取写对象
*/
Writer getWriter(String table);
/**
* 同类型读取写入,如mysql到mysql
*/
String getJobTaskName(String readerTable,String writeTable);
/**
* 自定义读取写入
* @param reader 读处理
* @param write 写处理
* @param suffix 文件名
*/
String getJobTaskName(Reader reader,Writer write, String suffix);
}
/**
* 接口抽象类
* @author moshangshang
*/
@Component
public abstract class AbstractDataXHandler implements DataXInterface {
@Autowired
private DataXProperties dataXProperties;
/**
* 自定义读取写入
* @param reader 读处理
* @param write 写处理
* @param suffix 文件名
*/
@Override
public String getJobTaskName(Reader reader, Writer write, String suffix) {
DataXJobRoot root = new DataXJobRoot();
Job job = new Job();
root.setJob(job);
Content content = new Content(reader,write);
job.setContent(Collections.singletonList(content));
String jsonStr = JSONUtil.parse(root).toJSONString(2);
String fileName = "datax_job_"+ UUID.randomUUID().toString().replaceAll("-","") +"_"+suffix+".json";
File file = FileUtil.file(dataXProperties.getSavePath(),fileName);
FileUtil.appendString(jsonStr, file, "utf-8");
return fileName;
}
}
工具方法
@Repository
public class DatabaseInfoRepository {
private final JdbcTemplate jdbcTemplate;
@Autowired
public DatabaseInfoRepository(JdbcTemplate jdbcTemplate) {
this.jdbcTemplate = jdbcTemplate;
}
/**
* 获取所有表名
*/
public List<String> getAllTableNames() {
String sql = "SHOW TABLES";
return jdbcTemplate.queryForList(sql, String.class);
}
/**
* 根据表名获取字段信息
*/
public List<Map<String, Object>> getTableColumns(String tableName) {
String sql = "SHOW FULL COLUMNS FROM " + tableName;
return jdbcTemplate.queryForList(sql);
}
}
@Slf4j
@Service
public class DatabaseInfoService {
private final DatabaseInfoRepository databaseInfoRepository;
@Autowired
public DatabaseInfoService(DatabaseInfoRepository databaseInfoRepository) {
this.databaseInfoRepository = databaseInfoRepository;
}
public void printAllTablesAndColumns() {
// 获取所有表名
List<String> tableNames = databaseInfoRepository.getAllTableNames();
// 遍历表名,获取并打印每个表的字段信息
for (String tableName : tableNames) {
System.out.println("Table: " + tableName);
// 获取当前表的字段信息
List<Map<String, Object>> columns = databaseInfoRepository.getTableColumns(tableName);
// 遍历字段信息并打印
for (Map<String, Object> column : columns) {
System.out.println(" Column: " + column.get("Field") + " (Type: " + column.get("Type") + ")" + " (Comment: " + column.get("Comment") + ")");
}
// 打印空行作为分隔
System.out.println();
}
}
/** 查询指定表的所有字段列表 */
public List<String> getColumns(String tableName) {
List<String> list = new ArrayList<>();
// 获取当前表的字段信息
List<Map<String, Object>> columns = databaseInfoRepository.getTableColumns(tableName);
// 遍历字段信息并打印
for (Map<String, Object> column : columns) {
list.add(column.get("Field").toString());
}
return list;
}
/** 查询指定表的所有字段列表,封装成HdfsWriter格式 */
public List<HdfsWriter.Column> getHdfsColumns(String tableName) {
List<HdfsWriter.Column> list = new ArrayList<>();
// 获取当前表的字段信息
List<Map<String, Object>> columns = databaseInfoRepository.getTableColumns(tableName);
// 遍历字段信息并打印
for (Map<String, Object> column : columns) {
String name = column.get("Field").toString();
String typeDb = column.get("Type").toString();
String type = "string";
if (typeDb.equals("bigint")) {
type = "bigint";
} else if (typeDb.startsWith("varchar")) {
type = "string";
} else if (typeDb.startsWith("date") || typeDb.endsWith("timestamp")) {
type = "date";
}
HdfsWriter.Column columnHdfs = new HdfsWriter.Column();
columnHdfs.setName(name);
columnHdfs.setType(type);
list.add(columnHdfs);
}
return list;
}
}
datax的job任务json执行方法
/**
* 执行器
* @author moshangshang
*/
@Slf4j
@Component
public class DataXExecuter {
@Autowired
private DataXProperties dataXProperties;
public void run(String fileName) throws IOException {
System.setProperty("datax.home", dataXProperties.getHome());
String filePath = dataXProperties.getSavePath()+fileName;
String dataxJson = JSONUtil.parse(FileUtils.readFileToString(new File(filePath),"UTF-8")).toJSONString(2);
log.info("datax log:{}",dataxJson);
String[] dataxArgs = {"-job", filePath, "-mode", "standalone", "-jobid", "-1"};
try {
Engine.entry(dataxArgs);
}catch (DataXException e){
log.error("执行失败",e);
} catch (Throwable throwable) {
log.error("DataX执行异常,error cause::\n" + ExceptionTracker.trace(throwable));
}
}
}
2.文件目录如图
3.Mysql数据同步
1.编写mysql读写对象,继承读写接口
@Data
public class MysqlReader extends Reader {
public String getName() {
return "mysqlreader";
}
@Data
public static class MysqlParameter extends Parameter {
private List<String> column;
private List<Connection> connection;
private String password;
private String username;
private String splitPk;
private String where;
}
@Data
public static class Connection {
private List<String> jdbcUrl;
private List<String> table;
private List<String> querySql;
}
}
@EqualsAndHashCode(callSuper = true)
@Data
public class MysqlWriter extends Writer {
public String getName() {
return "mysqlwriter";
}
@EqualsAndHashCode(callSuper = true)
@Data
public static class MysqlParameter extends Parameter {
private List<String> column;
private List<Connection> connection;
private String password;
private String username;
private String writeMode = "update";
}
@Data
public static class Connection {
private String jdbcUrl;
private List<String> table;
}
}
2.配置mysql读和写的数据库信息
/**
* mysql读写配置
* @author moshangshang
*/
@Data
@ConfigurationProperties("datax.mysql.reader")
public class DataXMysqlReaderProperties {
private String url;
private String password;
private String username;
}
/**
* mysql读写配置
* @author moshangshang
*/
@Data
@ConfigurationProperties("datax.mysql.writer")
public class DataXMysqlWriterProperties {
private String url;
private String password;
private String username;
}
# datax 相关配置,在生成文件时使用
datax:
mysql:
reader:
url: jdbc:mysql://127.0.0.1:3306/test_local?characterEncoding=UTF-8&serverTimezone=Asia/Shanghai
username: root
password: root
writer:
url: jdbc:mysql://127.0.0.1:3306/ruoyi_local?characterEncoding=UTF-8&serverTimezone=Asia/Shanghai
username: root
password: root
2.编写mysql处理类,继承抽象处理接口。生成job文件
/**
* mysql读写处理
* @author moshangshang
*/
@Component
@EnableConfigurationProperties({DataXMysqlReaderProperties.class, DataXMysqlWriterProperties.class})
public class MysqlHandler extends AbstractDataXHandler{
@Autowired
private DatabaseInfoService databaseInfoService;
@Autowired
private DataXProperties dataXProperties;
@Autowired
private DataXMysqlReaderProperties dataXMysqlReaderProperties;
@Autowired
private DataXMysqlWriterProperties dataXMysqlWriterProperties;
@Override
public Reader getReader(String table) {
MysqlReader reader = new MysqlReader();
MysqlReader.MysqlParameter readerParameter = new MysqlReader.MysqlParameter();
readerParameter.setPassword(dataXMysqlReaderProperties.getPassword());
readerParameter.setUsername(dataXMysqlReaderProperties.getUsername());
List<String> readerColumns = databaseInfoService.getColumns(table);
readerParameter.setColumn(readerColumns);
MysqlReader.Connection readerConnection = new MysqlReader.Connection();
readerConnection.setJdbcUrl(Collections.singletonList(dataXMysqlReaderProperties.getUrl()));
readerConnection.setTable(Collections.singletonList(table));
readerParameter.setConnection(Collections.singletonList(readerConnection));
reader.setParameter(readerParameter);
return reader;
}
@Override
public Writer getWriter(String table) {
MysqlWriter writer = new MysqlWriter();
MysqlWriter.MysqlParameter writerParameter = new MysqlWriter.MysqlParameter();
writerParameter.setPassword(dataXMysqlWriterProperties.getPassword());
writerParameter.setUsername(dataXMysqlWriterProperties.getUsername());
List<String> columns = databaseInfoService.getColumns(table);
writerParameter.setColumn(columns);
MysqlWriter.Connection connection = new MysqlWriter.Connection();
connection.setJdbcUrl(dataXMysqlWriterProperties.getUrl());
connection.setTable(Collections.singletonList(table));
writerParameter.setConnection(Collections.singletonList(connection));
writer.setParameter(writerParameter);
return writer;
}
@Override
public String getJobTaskName(String readerTable,String writeTable) {
DataXJobRoot root = new DataXJobRoot();
Job job = new Job();
root.setJob(job);
Content content = new Content(getReader(readerTable),getWriter(writeTable));
job.setContent(Collections.singletonList(content));
String jsonStr = JSONUtil.parse(root).toJSONString(2);
String fileName = "datax_job_"+ UUID.randomUUID().toString().replaceAll("-","") +"_h2h.json";
File file = FileUtil.file(dataXProperties.getSavePath(),fileName);
FileUtil.appendString(jsonStr, file, "utf-8");
return fileName;
}
}
3.调用执行器,执行任务job
@SpringBootTest
public class DataxTest {
@Autowired
private MysqlHandler mysqlHandler;
@Autowired
private DataXExecuter dataXExecuter;
/**
* 读t_user表同步到user
*/
@Test
public void test() throws IOException {
String jobTask = mysqlHandler.getJobTaskName("t_user", "user");
dataXExecuter.run(jobTask);
}
/**
* 直接执行json文件
*/
@Test
public void test2() throws IOException {
dataXExecuter.run("datax_job_83798b5f1766406289a44fe681dc8878_m2m.json");
}
}
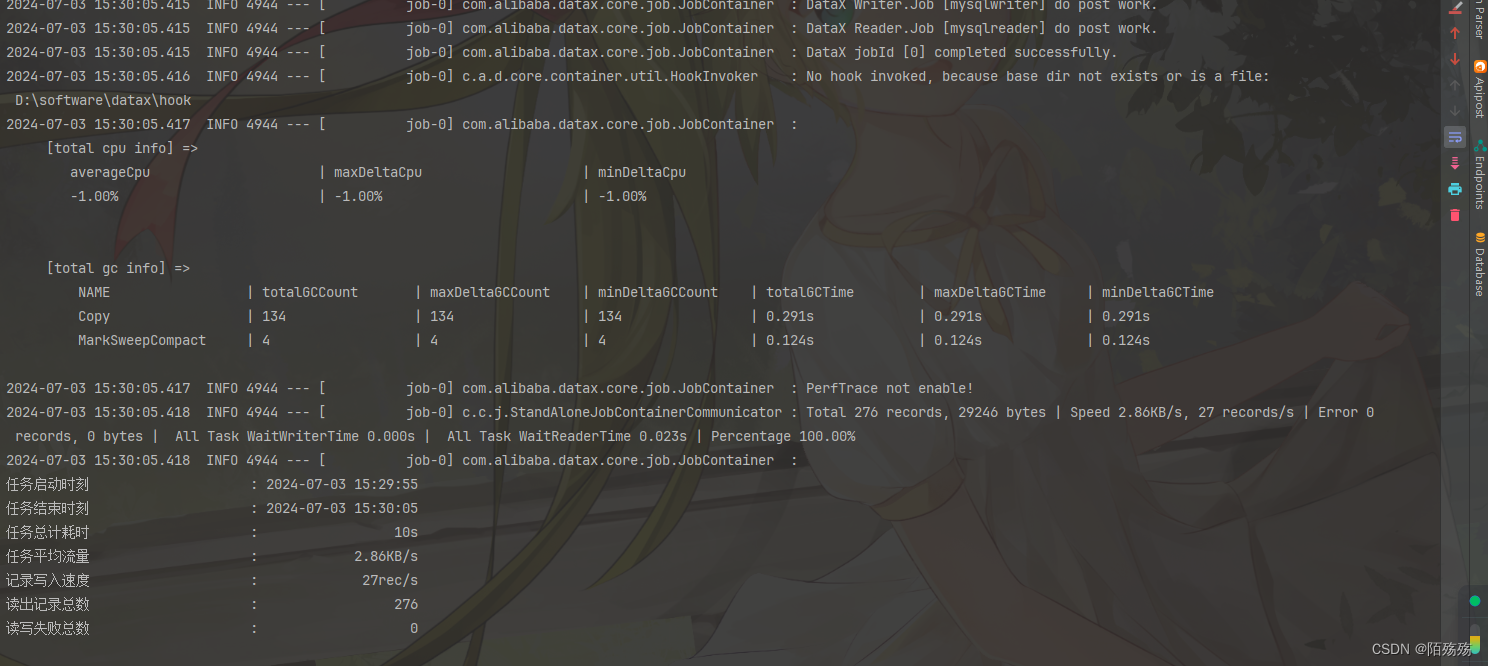
4.执行结果
4.Elasticsearch写入Mysql数据
注意事项:
- es目前只支持写入
不支持读取 - mysql数据写入es时,需保证es与mysql的
列数column相同,不支持类似mysql的部分字段写入 需保证列的顺序相同,写入时不会根据name名称字段去自动对应,如果顺序不一致,则可能会转换错误。如id,name,写入name,id
原理:使用elasticsearch的rest api接口, 批量把从reader读入的数据写入elasticsearch
创建es索引映射
PUT datax_data
{
"mappings": {
"properties": {
"name":{"type": "keyword"},
"amount":{"type": "long"}
}
}
}
1.添加es配置和文件
spring:
elasticsearch:
#username:
#password:
#path-prefix:
uris: http://127.0.0.1:9200
#连接elasticsearch超时时间
connection-timeout: 60000
socket-timeout: 30000
# datax 相关配置,在生成文件时使用
datax:
elasticsearch:
writer:
url: http://127.0.0.1:9200
username:
password:
/**
* es写配置
* @author moshangshang
*/
@Data
@ConfigurationProperties("datax.elasticsearch.writer")
public class DataXElasticSearchProperties {
private String url;
private String username;
private String password;
}
2.编写生成job文件实体类
@EqualsAndHashCode(callSuper = true)
@Data
public class ElasticSearchWriter extends Writer {
public String getName() {
return "elasticsearchwriter";
}
@EqualsAndHashCode(callSuper = true)
@Data
public static class ElasticSearchParameter extends Parameter {
private List<Column> column;
private String endpoint;
private String accessId;
private String accessKey;
private String index;
private Settings settings;
private String type = "default";
private boolean cleanup = true;
private boolean discovery = false;
private Integer batchSize = 1000;
private String splitter = ",";
}
@Data
@AllArgsConstructor
@NoArgsConstructor
public static class Column {
private String name;
private String type;
private String analyzer;
}
@Data
public static class Settings {
private Map<String,Object> index;
}
}
3.es接口扩展
/**
* es接口扩展
* @author moshangshang
*/
public interface DataXElasticsearchInterface extends DataXInterface {
Writer getWriter(String table, Map<String,Object> indexSettings);
}
4.es核心处理类
@Component
@EnableConfigurationProperties({DataXElasticSearchProperties.class})
public class ElasticSearchHandler extends AbstractDataXHandler implements DataXElasticsearchInterface{
@Autowired
private ElasticsearchRestTemplate elasticsearchRestTemplate;
@Autowired
private DataXElasticSearchProperties dataXElasticSearchProperties;
@Override
public Reader getReader(String table) {
return null;
}
/**
* 普通写入
* @param index 索引
* @return Writer
*/
@Override
public Writer getWriter(String index) {
ElasticSearchWriter writer = new ElasticSearchWriter();
ElasticSearchWriter.ElasticSearchParameter writerParameter = getElasticSearchWriter(index);
writer.setParameter(writerParameter);
return writer;
}
@Override
public String getJobTaskName(String readerTable, String writeTable) {
return null;
}
/**
* es写入,带setting设置
*/
@Override
public Writer getWriter(String index,Map<String,Object> map) {
ElasticSearchWriter writer = new ElasticSearchWriter();
ElasticSearchWriter.ElasticSearchParameter writerParameter = getElasticSearchWriter(index);
ElasticSearchWriter.Settings settings = new ElasticSearchWriter.Settings();
settings.setIndex(map);
writerParameter.setSettings(settings);
writer.setParameter(writerParameter);
return writer;
}
/**
* 获取公共写入参数
*/
public ElasticSearchWriter.ElasticSearchParameter getElasticSearchWriter(String index){
ElasticSearchWriter.ElasticSearchParameter writerParameter = new ElasticSearchWriter.ElasticSearchParameter();
List<Column> columns = getEsColumns(index);
writerParameter.setColumn(columns);
writerParameter.setEndpoint(dataXElasticSearchProperties.getUrl());
writerParameter.setAccessId(dataXElasticSearchProperties.getUsername());
writerParameter.setAccessKey(dataXElasticSearchProperties.getPassword());
writerParameter.setIndex(index);
return writerParameter;
}
/**
* 获取指定索引的映射字段
* 读取时和创建顺序相反
*/
public List<ElasticSearchWriter.Column> getEsColumns(String index){
List<ElasticSearchWriter.Column> columns = new ArrayList<>();
// 获取操作的索引文档对象
IndexOperations indexOperations = elasticsearchRestTemplate.indexOps(IndexCoordinates.of(index));
Map<String, Object> mapping = indexOperations.getMapping();
mapping.forEach((k,value) ->{
JSONObject json = JSON.parseObject(JSONObject.toJSONString(value));
for (Map.Entry<String, Object> entry : json.entrySet()) {
String key = entry.getKey();
JSONObject properties = JSON.parseObject(JSONObject.toJSONString(entry.getValue()));
String type = properties.getString("type");
String analyzer = properties.getString("analyzer");
columns.add(new ElasticSearchWriter.Column(key,type,analyzer));
}
});
return columns;
}
}
5.测试
@Test
public void test3() throws IOException {
Map<String,Object> settings = new HashMap<>();
settings.put("number_of_shards",1);
settings.put("number_of_replicas",1);
String jobTask = elasticSearchHandler.getJobTaskName(mysqlHandler.getReader("t_user")
, elasticSearchHandler.getWriter("datax_data",settings),"m2e");
dataXExecuter.run(jobTask);
}
5.Job文件参数说明
1.MysqlReader
| 参数名 | 描述 | 必选 |
|---|---|---|
| jdbcUrl | 对端数据库的JDBC连接信息并支持一个库填写多个连接地址。之所以使用JSON数组描述连接信息,是因为阿里集团内部支持多个IP探测,如果配置了多个,MysqlReader可以依次探测ip的可连接性,直到选择一个合法的IP,如果全部连接失败,MysqlReader报错。 注意,jdbcUrl必须包含在connection配置单元中。对于阿里外部使用情况,JSON数组填写一个JDBC连接即可。 | 是 |
| username | 数据源的用户名 | 是 |
| password | 数据源指定用户名的密码 | 是 |
| table | 所选取的需要同步的表。支持多张表同时抽取,用户自己需保证多张表是同一schema结构,注意,table必须包含在connection配置单元中。 | 是 |
| column | 所配置的表中需要同步的列名集合,使用JSON的数组描述字段信息。用户使用代表默认使用所有列配置,例如['']。 | 是 |
| splitPk | 分区主键,DataX因此会启动并发任务进行数据同步。推荐splitPk用户使用表主键 | 否 |
| where | 筛选条件,MysqlReader根据指定的column、table、where条件拼接SQL,并根据这个SQL进行数据抽取。注意:limit不是SQL的合法where子句。where条件可以有效地进行业务增量同步。如果不填写where语句,包括不提供where的key或者value,均视作同步全量数据。 | 否 |
| querySql | 查询SQL同步。当用户配置了这一项之后,当用户配置querySql时,MysqlReader直接忽略table、column、where条件的配置,querySql优先级大于table、column、where选项。 | 否 |
2.MysqlWriter
| 参数名 | 描述 | 必选 |
|---|---|---|
| jdbcUrl | 目的数据库的 JDBC 连接信息。作业运行时,DataX 会在你提供的 jdbcUrl 后面追加如下属性:yearIsDateType=false&zeroDateTimeBehavior=convertToNull&rewriteBatchedStatements=true;在一个数据库上只能配置一个 jdbcUrl 值。这与 MysqlReader 支持多个备库探测不同,因为此处不支持同一个数据库存在多个主库的情况(双主导入数据情况) | 是 |
| username | 数据源的用户名 | 是 |
| password | 数据源指定用户名的密码 | 是 |
| table | 目的表的表名称。支持写入一个或者多个表。当配置为多张表时,必须确保所有表结构保持一致。table 和 jdbcUrl 必须包含在 connection 配置单元中 | 是 |
| column | 目的表需要写入数据的字段,例如: “column”: [“id”,“name”,“age”]。如果要依次写入全部列,使用*表示, 例如: "column": ["*"]。 | 是 |
| session | DataX在获取Mysql连接时,执行session指定的SQL语句,修改当前connection session属性 | 否 |
| preSql | 写入数据到目的表前,会先执行这里的标准语句。如果 Sql 中有你需要操作到的表名称,请使用 @table 表示,这样在实际执行 Sql 语句时,会对变量按照实际表名称进行替换。比如你的任务是要写入到目的端的100个同构分表(表名称为:datax_00,datax01, … datax_98,datax_99),并且你希望导入数据前,先对表中数据进行删除操作,那么你可以这样配置:"preSql":["delete from 表名"],效果是:在执行到每个表写入数据前,会先执行对应的 delete from 对应表名称 | 否 |
| postSql | 写入数据到目的表后,会执行这里的标准语句 | 否 |
| writeMode | 控制写入数据到目标表采用 insert into 或者 replace into 或者 ON DUPLICATE KEY UPDATE 语句;可选:insert/replace/update,默认insert | 是 |
| batchSize | 一次性批量提交的记录数大小,该值可以极大减少DataX与Mysql的网络交互次数,并提升整体吞吐量。但是该值设置过大可能会造成DataX运行进程OOM情况。默认:1024 | 否 |
3.ElasticsearchWriter
| 参数名 | 描述 | 必选 |
|---|---|---|
| endpoint | ElasticSearch的连接地址 | 是 |
| accessId | http auth中的user | 否 |
| accessKey | http auth中的password | 否 |
| index | elasticsearch中的index名 | 是 |
| type | elasticsearch中index的type名,默认index名 | 否 |
| cleanup | 是否删除原表, 默认值:false | 否 |
| batchSize | 每次批量数据的条数,默认值:1000 | 否 |
| trySize | 失败后重试的次数, 默认值:30 | 否 |
| timeout | 客户端超时时间,默认值:600000 | 否 |
| discovery | 启用节点发现将(轮询)并定期更新客户机中的服务器列表。默认false | 否 |
| compression | http请求,开启压缩,默认true | 否 |
| multiThread | http请求,是否有多线程,默认true | 否 |
| ignoreWriteError | 忽略写入错误,不重试,继续写入,默认false | 否 |
| alias | 数据导入完成后写入别名 | 否 |
| aliasMode | 数据导入完成后增加别名的模式,append(增加模式), exclusive(只留这一个),默认append | 否 |
| settings | 创建index时候的settings, 与elasticsearch官方相同 | 否 |
| splitter | 如果插入数据是array,就使用指定分隔符,默认值:-,- | 否 |
| column | elasticsearch所支持的字段类型,样例中包含了全部 | 是 |
| dynamic | 不使用datax的mappings,使用es自己的自动mappings,默认值: false | 否 |
参考资料:https://blog.youkuaiyun.com/wlddhj/article/details/137585979
Github主页地址:https://github.com/alibaba/DataX


















 1493
1493

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









