







损失函数
半监督方法:Π模型,Temporal Ensembling,Mean-Teacher
半监督语义分割笔记(1)-数据增强方法Mixup、Cutout、CutMix、ClassMix
半监督语义分割笔记(2)-self-training和consistency learning方法
在前文中,我们了解到了半监督语义分割的三种算法和数据增强方法,其中对于每种算法,都需要计算Loss,因此此处对一些损失函数进行原理上的理解,以便更加深入地了解算法。
1 交叉熵损失(Cross Entropy Loss)
参考:交叉熵损失函数(Cross Entropy Loss)
2 MS-loss(Mumford shah)
经典的变分方法把图像分割看作一个聚类问题,例如 k-means、均值偏移、归一化切割、图切割和水平集等等,这些方法都是通过最小化一些特定的能量函数将图像像素进行分类来实现无监督图像分割的,在这些方法中最著名的能量函数就是 Mumford-Shah泛函。
Mumford-Shah 泛函的最小化一直是经典图像分割的关键问题,在过去的几十年里,已经发展了各种方法。该问题的主要技术难题是原始Mumford-Shah 泛函具有不可微性。
具体地说,对于给定的一张图像 x(r ),𝑟 ∈ 𝛺 ⊂ 𝑅²,此时用于将图像分割到 N 类分段区域的 Mumford-Shah 能量泛函定义为:
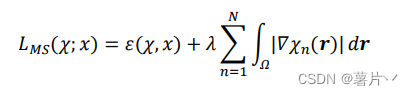
其中,
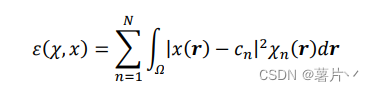
而𝜒𝑛(𝑟)表示第 n 类的特征函数,使得
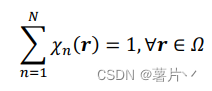
𝑐𝑛表示平均像素值。
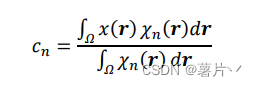
但是,Mumford-Shah 泛函式由于特征函数𝜒𝑛(𝑟)的不可知性而不可微,为了使代价函数式𝐿𝑀𝑆(𝜒; 𝑥)可微,有多种方法,就是后面发展延伸出的方法。(反向传播时,需要可微)
以下提出结合CNN的MS损失函数:
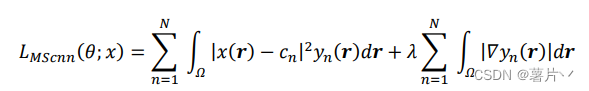
其中𝑥(𝑟)是特征函数输入,𝑦𝑛(𝑟): = 𝑦𝑛(𝑟; 𝜃) 是公式中 softmax 层的网络输出,并且
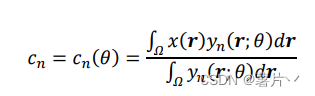
𝑐𝑛是第 n 类的平均像素值,此处的𝜃指神经网络中 softmax 层前全部可学习的网络参数。
也就是说,由于x𝑛(𝑟)和y𝑛(𝑟)的sum都是1,那么就可以将原MS中的部分x𝑛(𝑟)换成y𝑛(𝑟)。
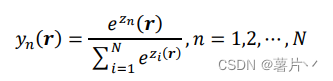
此时,公式对于参数𝜃是可微的,所以,可以通过在训练期间的反向传播最小化损失函数,也就是说可以巧妙的将最小化 Mumford-Shah 函数应用于神经网络之中。
对于MSloss,有标记和无标记的数据的LOSS可以表示为以下:
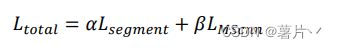
ms_loss=( MS_loss(soft_pred_l, imgs ) )*alpha + ( MS_loss(soft_logits_cons_stu_1, unsup_imgs_mixed) )*beta #alpha、beta 处 均可修改权重


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









