







前言
已经记不清这是我第几次解读大模型Transformer架构了,从浅到深,包括自己之前解读完还会从0手写一个大模型出来,去训练,去微调。但是每一次解读后,都会有更深的感受和理解,今天花时间做了一次系统的整理,有需要今后想研究大模型的,可以收藏起来,以后慢慢看。看一次就懂很难,有些地方,需要慢慢读,慢慢品,研究的多了,相信下面这张图,你都能背着画下来了。
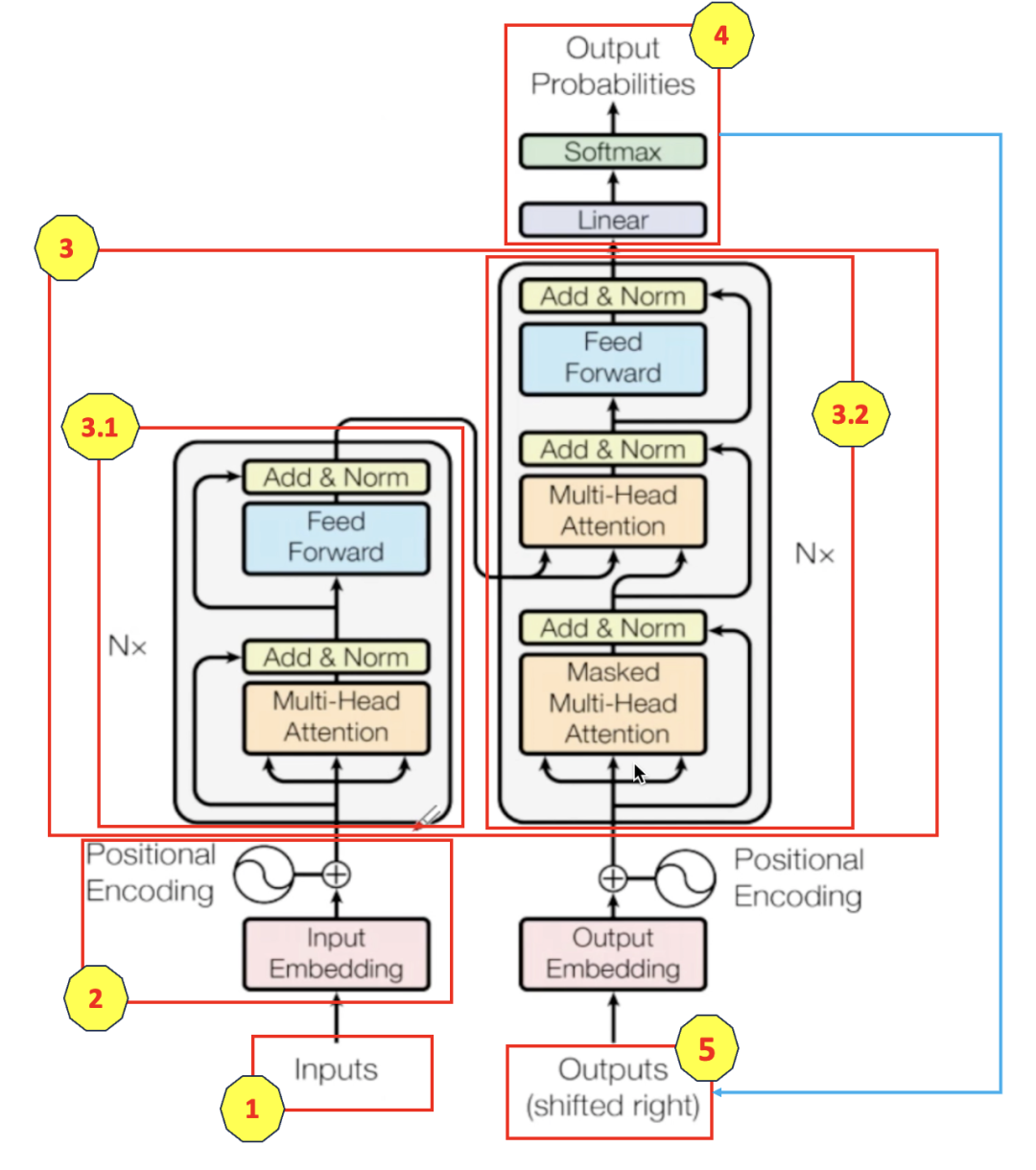
(Transformer架构)
Transformer架构起源
Transformer是谷歌在2017年发表的一篇论文,它的出现为自然语言处(NLP)提供了一种全新的范式,尤其是其核心自注意力机制,提供了一种更加高效、更加强大的方法来处理序列数据。Transformer的架构图上图所示,按照我的理解我给标上了序号并分成了5个大部分,方便后面讲解。
1、Inputs
输入的内容:这个就是用于我们用于交互的输入,比如输入一段文字:端午节我国都有什么活动?
**2、**输入预处理部分
输入预处理部分:这里包含两部分,Inputs Embedding (把文字转码成用512个数字去表示)和 Positional Encoding(标记文字的位置,这里为什么要标记位置呢,因为同样的字,比如我爱你和你爱我,位置不同,表示的含义不同,所以需要对输入的每一个文字,进行位置的标记)。整体总结:**这一步所做的事是将输入的文字转换为用数字表示,并标记位置。**这里我们将这一步称之为Q矩阵。
**3、**大模型核心部分
第三部分就是我们传统意义上的说的大模型部分了,这部分最为复杂,包括左边的编码器和右边的解码器,里面还有各种组件,其中最重要的就是之前提到的自注意力机制。
先简单解读一下,里面的内容在图上没有,是为了让大家先简单了解下大模型背后的本质是什么:
大模型的组成:模型 = 公式 + 参数(系数),比如一个数学公式,z=2x+7y,其中的2和7就是参数,而x和y是你输入的内容,z就是要计算后输出的结果。比如ChatGPT-3.5有1750亿个参数就是指的这个,现在GPT-4已经有万亿参数了。
大模型参数:大模型在没开始训练前,每个参数都是随机数,训练完成后,每个参数都是一个固定的数字。大模型训练后,当你把第二部分Q矩阵传入进去,跟着参数(比如ChatGPT3.5的1750亿个参数)做计算,最后就产生输出了。因为现在大家大模型底层都是Transformer架构,大家公式都差不多,最后评估一个大模型靠不靠谱,主要还是看参数。而机器学习训练大模型的过程,本质上就是让参数越来越靠谱的过程。
说完上面了,我们再来结合图,详细分析一下
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









