



前言
Transformer的起源:Google Brain 翻译团队通过论文《Attention is all you need》提出了一种全新的简单网络架构——Transformer,它完全基于注意力机制,摒弃了循环和卷积操作。

正如论文标题所言“注意力机制是全部所需”,强调了注意力机制是Transformer架构的核心要素,就如同人的心脏一样,充当着发动机的作用。
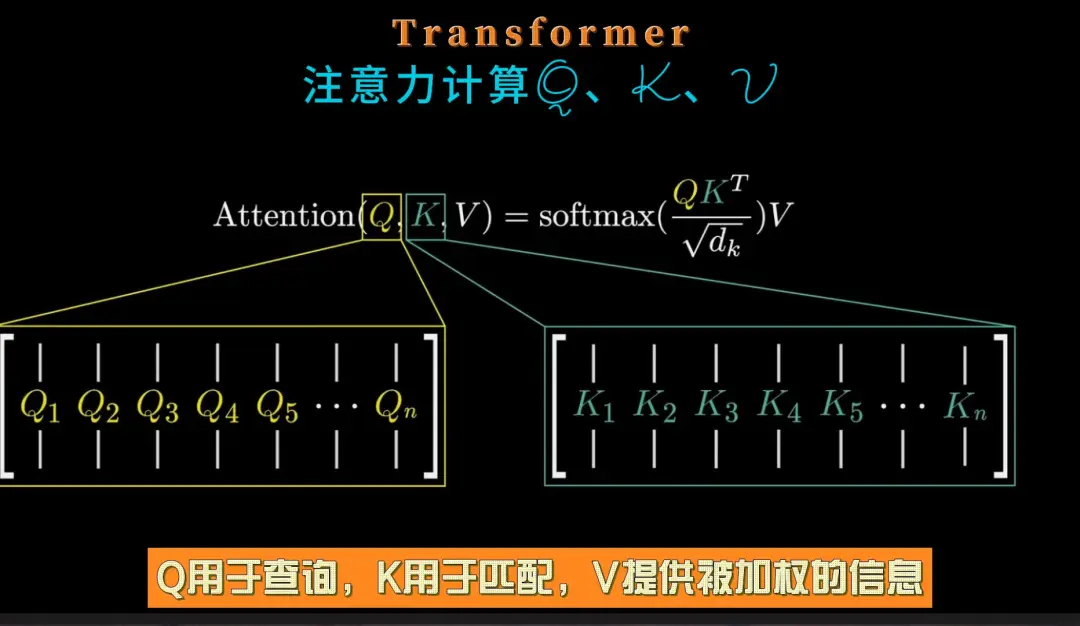
注意力计算Q、K、V:在注意力机制中,Q(Query)、K(Key)、V(Value)通过映射矩阵得到相应的向量,通过计算Q与K的点积相似度并经过softmax归一化得到权重,最后使用这些权重对V进行加权求和得到输出。

权重矩阵W:W_Q、W_K和W_V
-
权重矩阵W是可训练的参数,其维度为(d_model, d_k),其中d_model是输入嵌入的维度,d_k是Q/K/V向量的维度。通过训练,模型会学习到如何从输入数据中提取出对任务有用的特征,并将其映射到Q、K、V向量中
-
初始时,这些权重矩阵的值通常是随机初始化的。经过训练后,它们会学习到如何从输入数据中提取出对任务有用的特征。
-
模型会通过反向传播算法和梯度下降来更新这些权重矩阵W的值,以最小化某个损失函数(如交叉熵损失)。
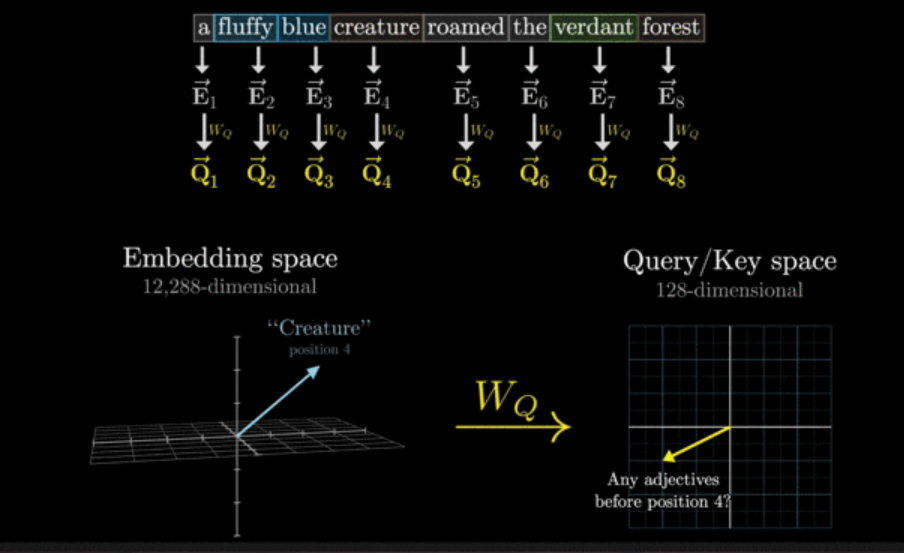
权重矩阵W_Q计算Query(Q):在Transformer模型中,Query(Q)是通过将输入数据的嵌入矩阵E与权重矩阵W_Q相乘得到的。
-
权重矩阵W_Q的定义:
- 在Transformer模型中,权重矩阵W是用于将输入数据(如词嵌入)映射到Q、K、V(Query、Key、Value)向量的线性变换矩阵。对于Query(Q),有一个专门的权重矩阵W_Q。
- W_Q的维度通常是(d_model, d_k),其中d_model是输入嵌入的维度(也是模型的维度),而d_k是Q/K/V向量的维度。假设d_k被设定为128。
-
计算Query(Q):
-
给定输入序列的嵌入矩阵E(形状为(batch_size, sequence_length, d_model)),Query矩阵Q是通过将X与权重矩阵W_Q相乘得到的。
-
具体地,对于Q中的每一个嵌入向量q_i(形状为(d_model)),Q中的一个向量q_i可以通过q_i = e_i * W_Q计算得到。
-
因此,整个Query矩阵Q(形状为(batch_size, sequence_length, d_k))可以通过E * W_Q计算得到。
-
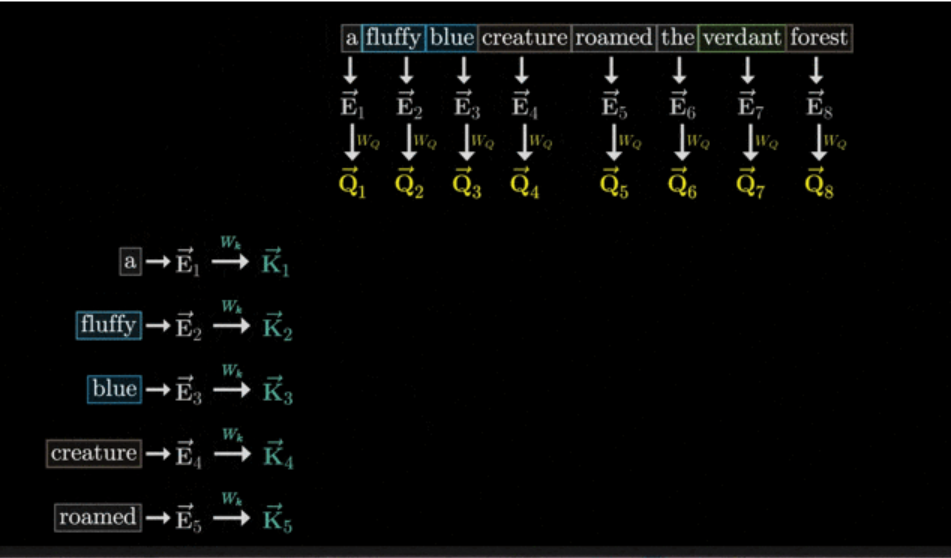
权重矩阵W_K计算Key(K):在Transformer模型中,Key(K)是通过将输入数据的嵌入矩阵E与权重矩阵W_K相乘得到的。
-
权重矩阵W_K的定义:
-
在Transformer模型中,权重矩阵W_K也是一个可训练的权重矩阵,用于将输入数据的嵌入映射到Key向量(K)。
-
W_K的维度通常是(d_model, d_k),其中d_model是输入嵌入的维度(也是Transformer模型的维度),d_k是Key向量的维度。假设d_k被设定为128。
-
-
计算Key(K):
-
给定输入序列的嵌入矩阵E(形状为(batch_size, sequence_length, d_model)),Key矩阵K是通过将E与权重矩阵W_K相乘得到的。
-
具体地,对于K中的每一个嵌入向量k_i(形状为(d_model)),K中的一个向量k_i可以通过k_i = e_i * W_K计算得到。
-
因此,整个Key矩阵K(形状为(batch_size, sequence_length, d_k))可以通过X * W_K计算得到。
-
权重矩阵W_V计算Value(V):在Transformer模型中,Value(V)是通过将输入数据的嵌入矩阵E与权重矩阵W_V相乘得到的。
-
权重矩阵W_V的定义:
-
在Transformer模型中,权重矩阵W_V也是一个可训练的权重矩阵,用于将输入数据的嵌入映射到Value向量(V)。
-
W_V的维度通常是(d_model, d_v),其中d_model是输入嵌入的维度(也是Transformer模型的维度),d_v是Value向量的维度。假设d_k被设定为128。
-
-
计算Value(V):
-
给定输入序列的嵌入矩阵E(形状为(batch_size, sequence_length, d_model)),Value矩阵V是通过将E与权重矩阵W_V相乘得到的。
-
具体地,对于E中的每一个嵌入向量e_i(形状为(d_model)),V中的一个向量v_i可以通过v_i = e_i * W_V计算得到。
-
因此,整个Value矩阵V(形状为(batch_size, sequence_length, d_v))可以通过E * W_V计算得到。
-
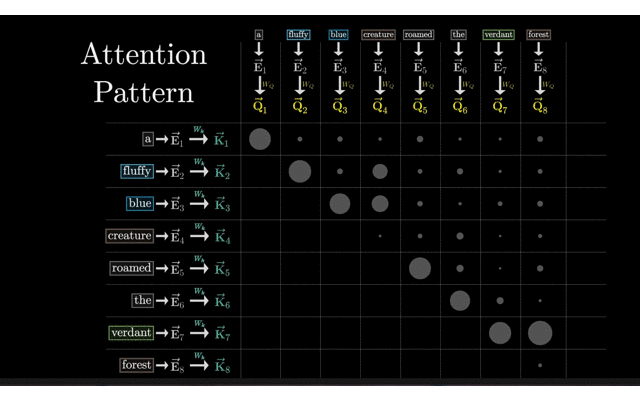
Q、K、V计算:Q用于查询,K用于匹配,V提供被加权的信息。通过计算Q和K的点积来衡量注意力分数,进而决定V的加权方式。
最后
感谢你们的阅读和喜欢,我收藏了很多技术干货,可以共享给喜欢我文章的朋友们,如果你肯花时间沉下心去学习,它们一定能帮到你。
因为这个行业不同于其他行业,知识体系实在是过于庞大,知识更新也非常快。作为一个普通人,无法全部学完,所以我们在提升技术的时候,首先需要明确一个目标,然后制定好完整的计划,同时找到好的学习方法,这样才能更快的提升自己。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

五、面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下。

这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









