






Python基础之深浅copy
1.is == id
-
id
我们创建的数据存储在内存,先会在内存中开辟一个空间,然后给整个空间分配一个唯一的内存地址(房间号),然后将这个数据存储在这个内存地址中。给变量赋值一个数据,其实变量指向的不是数据本身,而是数据所在的内存地址。

python提供了一个内置函数,id() 获取这个数据的内存地址。
name = 'bary' print(id(name)) name2 = 100 print(id(name2)) -
== is
- == 判断等号两边的数值是否相等。
- is 判断等号两边的数据的id是否相等。

- 如果两个变量is返回的是True,则两个变量指向的数据是同一个,那么这两个变量==一定是True。
- 如果两个变量==返回的是True,则两个变量is不一定是True。
2.代码块
"""
根据提示我们从官方文档找到了这样的说法:
A Python program is constructed from code blocks. A block is a piece of Python program text that is executed as a unit. The following are blocks: a module, a function body, and a class definition. Each command typed interactively is a block. A script file (a file given as standard input to the interpreter or specified as a command line argument to the interpreter) is a code block. A script command (a command specified on the interpreter command line with the ‘-c‘ option) is a code block. The string argument passed to the built-in functions eval() and exec() is a code block.
A code block is executed in an execution frame. A frame contains some administrative information (used for debugging) and determines where and how execution continues after the code block’s execution has completed.
"""
上面的主要意思是:
Python程序是由代码块构造的。块是一个python程序的文本,他是一个执行单元的。
代码块:一个模块,一个函数,一个类,一个文件等都是一个代码块。
而作为交互方式输入的每个命令都是一个代码块。
# 一个py文件是一个代码块。
# 终端命令交互模式下,一行代码代表一个代码块。

总结:
"""
python程序如果想要执行,必须依赖于一个代码块,一个代码块就代表一个执行单元。
一个py文件是一个代码块。
终端命令交互模式下,一行代码代表一个代码块。
"""
那么,可能有的同学还有一些不理解代码块,可以这样解释:我们都上过学对吧,你们在初中的时候,有没有过值周?就以一个班的学生用一星期的时间打扫整个学校,再比如有没有运动会,无论是值周,还是运动会,还是组织什么活动,都是以什么为单位呢?对,都是以班级为单位,那么咱们学生就好比是代码,班级就好比是代码块,我们想让代码运行起来,必须依靠班级去执行,也就是代码块。
3.同一代码块的缓存机制
前提:在同一个代码块内。
**机制内容:**Python在执行同一个代码块的初始化对象的命令时,会检查是否其值是否已经存在,如果存在,会将其重用。换句话说:执行同一个代码块时,遇到初始化对象的命令时,他会将初始化的这个变量与值存储在一个字典中,在遇到新的变量时,会先在字典中查询记录,如果有同样的记录那么它会重复使用这个字典中的之前的这个值。所以在你给出的例子中,文件执行时(同一个代码块)会把i1、i2两个变量指向同一个对象,满足缓存机制则他们在内存中只存在一个,即:id相同。

适应的数据类型(不可变的数据类型):
- 所有的数字。
- 几乎所有的字符串。
- 布尔值。
- 元组。
缓存机制的好处:
- 节省内存空间。
- 避免数据的重复的创建与销毁,提升效率。
4.不同代码块的缓存机制
-
前提:在不同代码块内。(也称为小数据池,字符串的缓存机制,字符串的驻留机制)
-
机制内容:Python自动将-5~256的整数进行了缓存,当你将这些整数赋值给变量时,并不会重新创建对象,而是使用已经创建好的缓存对象。python会将一定规则的字符串在字符串驻留池中,创建一份,当你将这些字符串赋值给变量时,并不会重新创建对象, 而是使用在字符串驻留池中创建好的对象。其实,无论是缓存还是字符串驻留池,都是python做的一个优化,就是将~5-256的整数,和一定规则的字符串,放在一个‘池’(容器,或者字典)中,无论程序中那些变量指向这些范围内的整数或者字符串,那么他直接在这个‘池’中引用,言外之意,就是内存中之创建一个。

适应的数据类型(不可变的数据类型):
-
-5~256数字。
-
一定规则的字符串。
-
布尔值。
-
缓存机制的好处:
-
节省内存空间。
-
避免数据的重复的创建与销毁,提升效率。
-
-
小结:
- 如果在同一代码块下,则采用同一代码块下的缓存机制。
- 如果是不同代码块,则采用小数据池的驻留机制
5.深浅copy
面试必考。
-
赋值运算
l1 = [200, 300, ['Allen', '大姚'], 3] l2 = l1 l1[0] = 20 print(l1, l2) l1 = [200, 300, ['Allen', '大姚'], 3] l2 = l1 # l1[0] = 20 # print(l1, l2) l1[-2].append(666) print(l1, l2)
-
浅copy
copy就是拷贝,复制。浅copy,只是复制一部分,剩下的公用。
# l1 = [200, 300, ['Allen', '大姚'], 3] # l2 = l1.copy() # print(id(l1), id(l2)) # print(id(l1[0]), id(l1[0])) # print(id(l1[-2]), id(l1[-2])) l1 = [200, 300, ['Allen', '大姚'], 3] l2 = l1.copy() # l1[0] = 20 l1[-2].append(666) print(l1, l2) l1 = [200, 300, ['Allen', '大姚'], 3] l2 = l1.copy() l1[-2] = 100 print(l1, l2)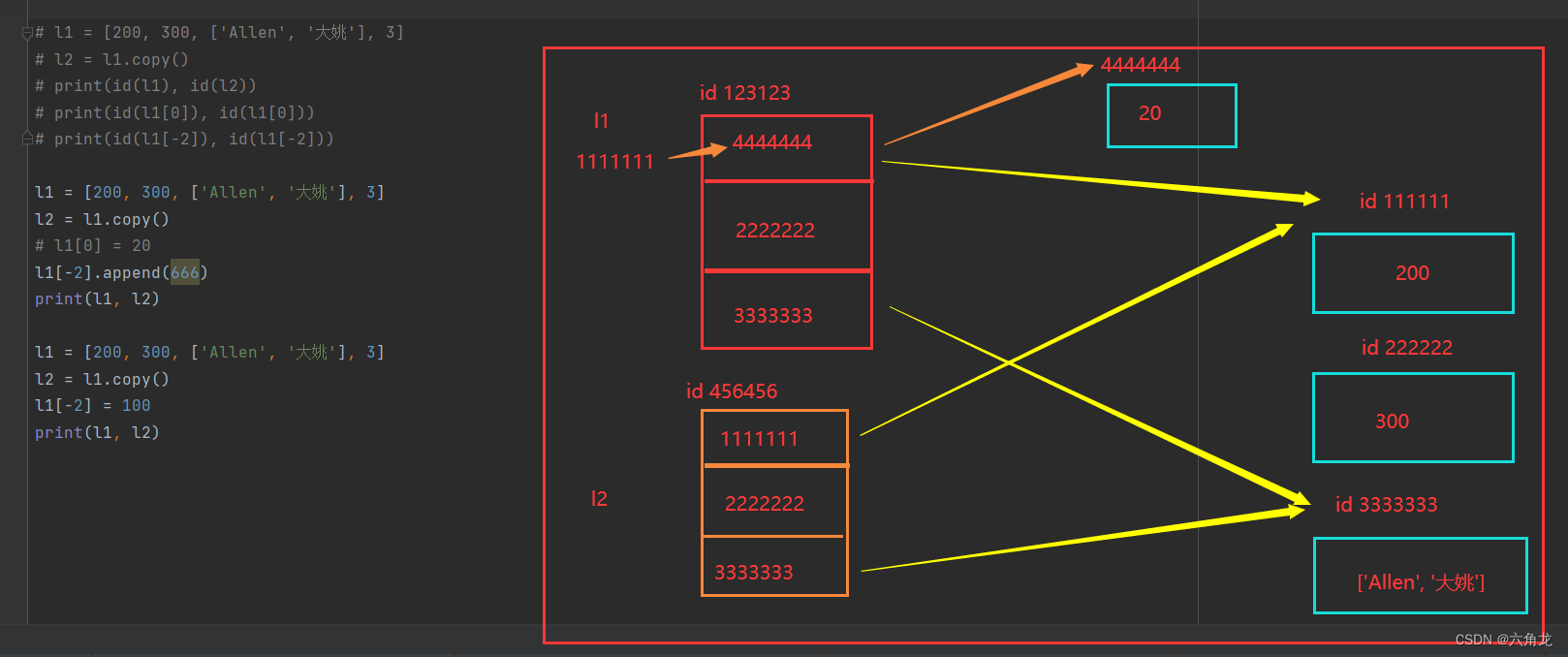
对于浅copy:在内存中重新创建一个新列表,但是新列表里面的数据还是沿用之间的列表里面的数据,如果你对列表中的可变的数据类型进行增删改时,另一个列表跟随改变。但是!!如果你列表的数据进行直接替换,另一个列表不会改变。
-
深copy
深copy就是全部创建新的,但是有例外。
import copy # l1 = [200, 300, ['allen', '大姚']] l2 = copy.deepcopy(l1) # 深copy # print(id(l1), id(l2)) # print(id(l1[-1]), id(l2[-1])) # l1[-1].append(666) # print(l2) print(id(l1[0]), id(l2[0]))深copy则会在内存中开辟新空间,将原列表以及列表里面的可变的数据类型重新创建一份,不可变的数据类型则沿用之前的。(缓存机制带来的效果)。
-
面试题
l1 = [200, 300, ['allen', '大姚']] l2 = l1[:] # 切片是浅copy l1[-1].append(666) print(l2)
深copy则会在内存中开辟新空间,将原列表以及列表里面的可变的数据类型重新创建一份,不可变的数据类型则沿用之前的。(缓存机制带来的效果)。
-
面试题
l1 = [200, 300, ['allen', '大姚']] l2 = l1[:] # 切片是浅copy l1[-1].append(666) print(l2)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









