







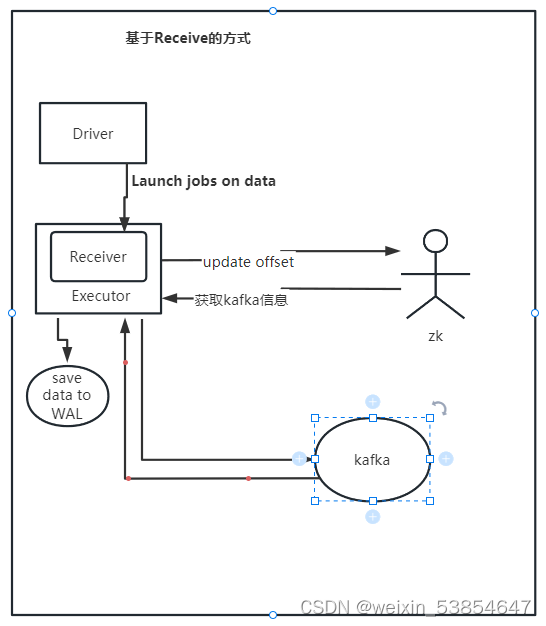
一、基于Receive 的方法这种方式使用Receiver来获取数据
Receive 是使用高级的API,需要消费者连接zk读取数据。是由Zookeeper来维护偏移量,接收的数据存储在Executor中(默认为内存满后存放在磁盘),后来sparkStreaming启动作业去处理数据,处理完这一批数据之后,更新zookeeper中保存的kafka的topic的分区的偏移量。不用我们来手动维护,这样的话就比较简单一些,减少了代码量。但是天下没有免费的午餐,它也有很多缺点:
1. 导致丢失数据,它是由Executor内的Receive来拉取数据并存放在内存中,再由Driver端提交的job来处理数据。
2. 浪费资源,将数据同步到高可用数据存储平台上,开启WAL机制,利用WAL日志导致磁盘内存等加大
3. 可能重复消费,可能导致spark和zk不同步,导致一份数据读取了两次。
4. 效率低
总结
在这个方式中,需要处理两件事,一是数据,二是offset。其中一个出现问题,都会导致数据处理异常。
1.数据处理成功,但是没有保存偏移量,造成数据重复消费->at least one
2.offset保存成功,但是数据处理失败,造成数据最多处理一次 -> at most once
3.都成功 -> exactly-once
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1725
1725

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









