







正则表达式(Regular Expression)
一、符号分类
| 符号 | 作用 |
|---|---|
| 普通符号(无功能的符号) 例如a、15、张三 | 用于匹配符号本身 |
| 特殊符号(属于是re中的保留字 具有特殊含义) 例如.、*、+、? | 由符号自身作用决定 |
| 字符组(用"[ ]"包裹 ) | 用于匹配"[ ]"中任意符号 |
| 元字符 例如\d \w \s | 由符号自身作用决定 |
| 量词{a} 、{a,b}、{a,} | 用于匹配指定次数 |
| 边界符号 如\b 、^、$ | 用于指定边界 |
二、特殊符号介绍
①.
# 功能:匹配任意符号 # 例如a.就是匹配任意带有a的字符串
②*
# 功能:匹配0到更多次 # 例如1.*b 就是匹配1和b中间夹杂任意字符的字符串(可以不包含)
③?
# 功能:匹配可选字符 或者指定匹配模式为非贪婪匹配模式(待匹配字符串后加?->例a+?) 即匹配的字符串尽可能短 # 例如ao?b就是匹配带有ab或者aob的字符串
④+
# 功能:匹配1到更多次 # 例如1.+b 就是匹配1和b中间夹杂任意字符的字符串(必须包含一个)
⑤( )
# 功能:获取匹配出的内容
# 例如(\d{4})就是提取出包含了连续4个数字的字符串
⑥|
# 功能:或者 # 例如(.zip|.7z|gz)就是提取出带有zip、7z、gz后缀的字符串
⑦?:
# 功能:非捕获分组 只使用分组的功能 不进行提取
# 例如(?:\d{2,5}|tel)[-.:](\d{5})只提取出01-75855的号码
⑧\n
# 功能:回溯引用 按照之前的规则匹配 # 例如(\w)(\w)\2\1 匹配abccba
三、符号组介绍
①[ ]
# 功能:匹配[]中任意符号 # 例如[abc]就是匹配a或b或c
四、元字符介绍
①\w
# 功能:匹配任意单词字符(包含下划线) 等价于[a-zA-Z0-9_]
②\W
# 功能:匹配任何非单词字符 即除了字母、数字、下划线之外的字符,等价于 [^a-zA-Z0-9_]
③\d
# 功能:匹配一个数字字符 等价于[0-9]
④\D
# 功能:匹配一个非数字字符 等价于[^0-9]
⑤\s
# 功能:匹配任何空白字符(包括空格、制表符、换行符等)等价于 [ \t\n\r\f\v]
⑥\S
# 功能:匹配任何非空白字符 等价于[^ \t\n\r\f\v]
五、量词介绍
①{a}
# 功能:匹配指定符号a次
# 例如a{5}就是匹配连续出现a 5次
②{a,b}
# 功能:匹配指定符号a-b次
# 例如a{1,5}就是匹配连续出现a 1到5次
③{a,}
# 功能:匹配指定符号a到更多次
# 例如a{1}就是匹配连续出现a 1次或多次
六、边界符号介绍
①^
# 功能:匹配指定符号开头的字符串 或者表示取反 # 例如^1 就是匹配1开头的字符串
②$
# 功能:匹配指定符号结尾的字符串 # 例如1$ 就是匹配1结尾的字符串
③\b
# 功能:匹配以指定字符为边界的字符串 # 例如\bhello\就是匹配完整包含hello的字符串 比如hello world 但不能匹配helloworld
七、断言
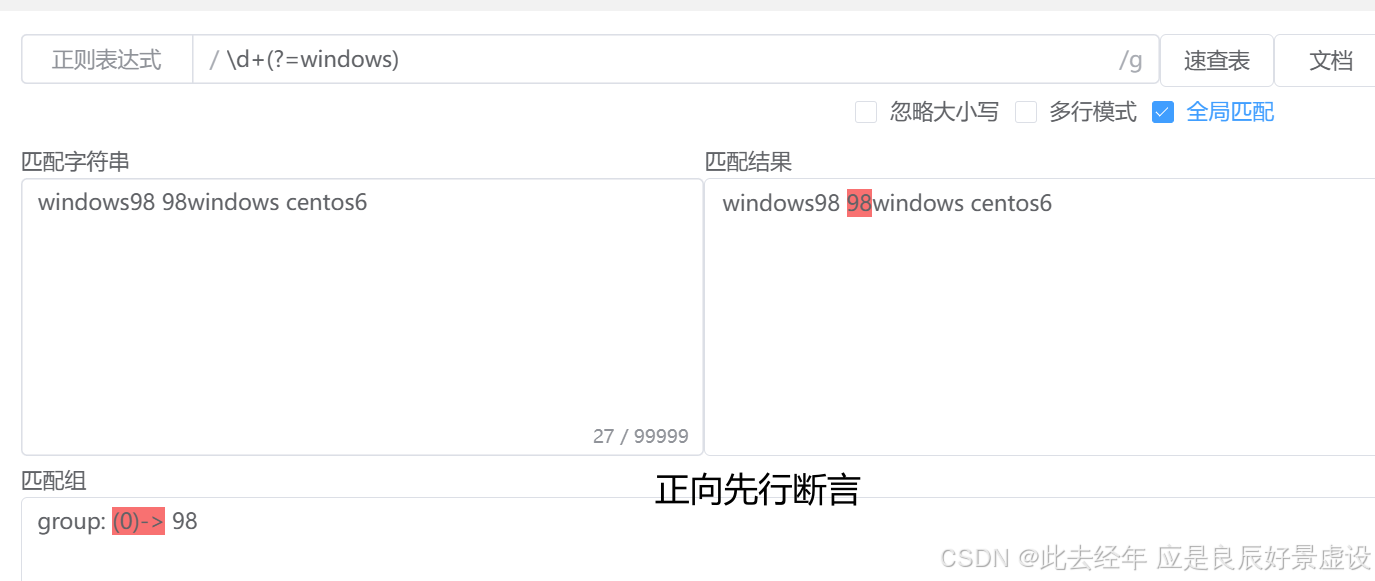
①正向先行断言
# 语法:(?=pattern) # 用法:检查当前位置之后的字符是否匹配 pattern
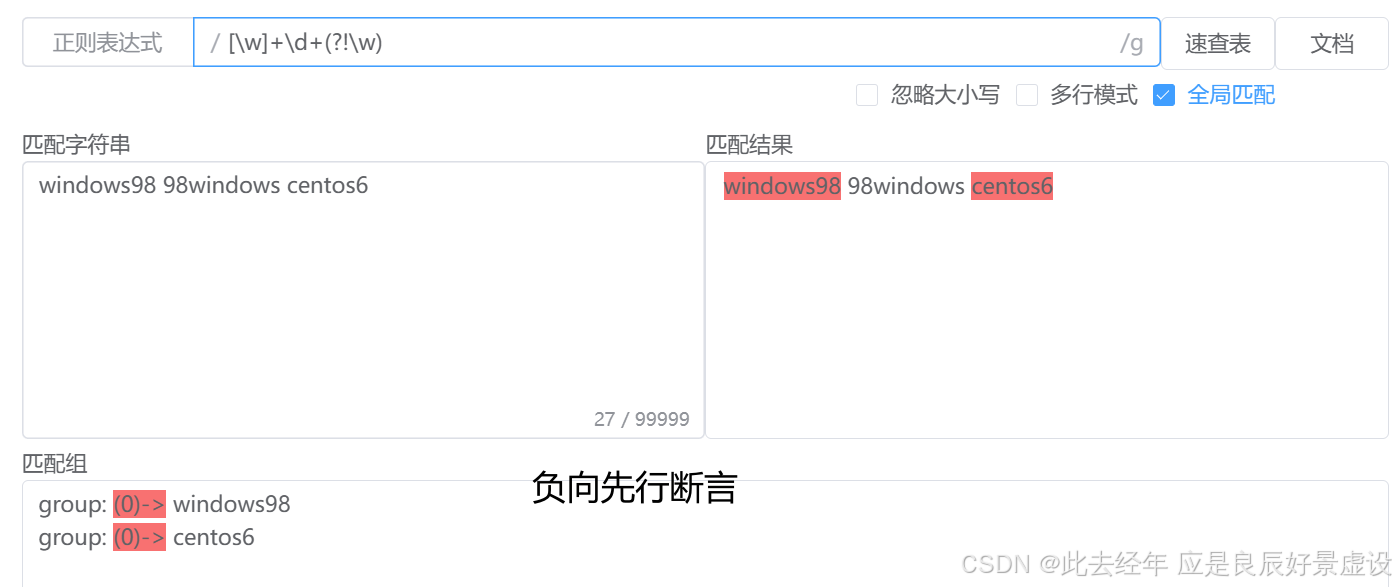
②负向先行断言
# 语法:(?!pattern) # 用法:检查当前位置之后的字符是否不匹配 pattern 如果不匹配 则继续进行后续匹配
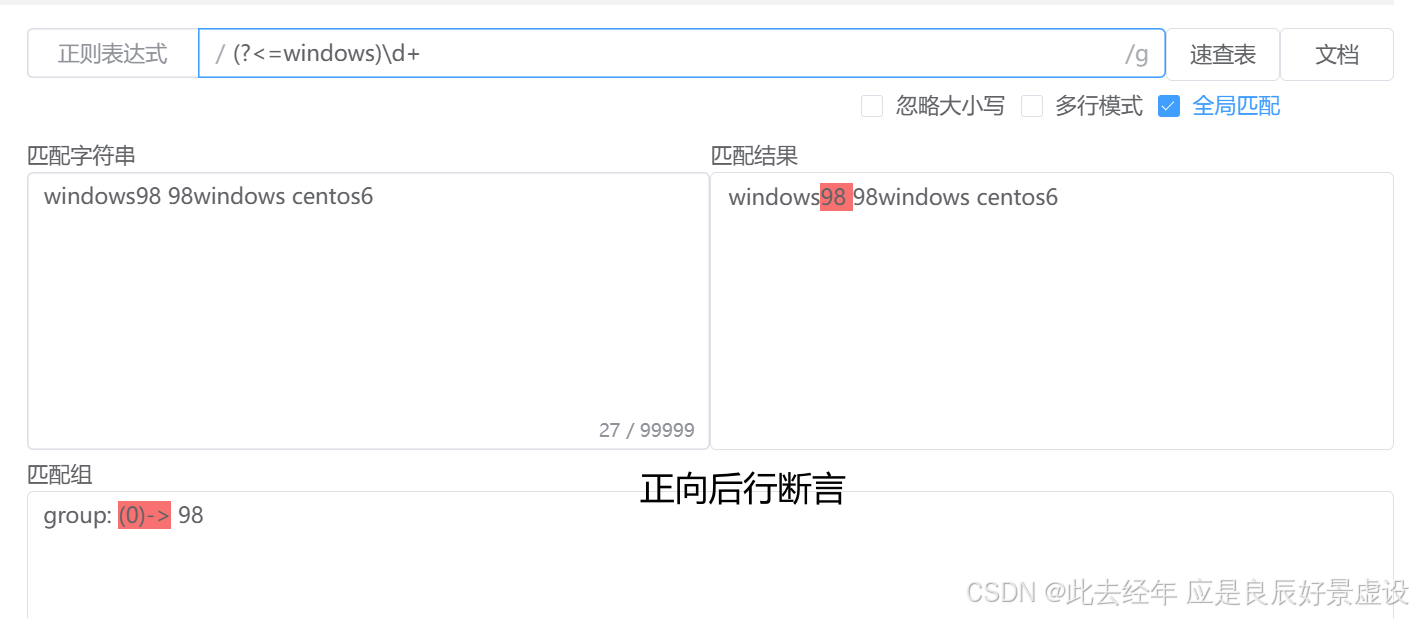
③正向后行断言
# 语法:(?<=pattern) # 用法:检查当前位置之前的字符是否匹配 pattern
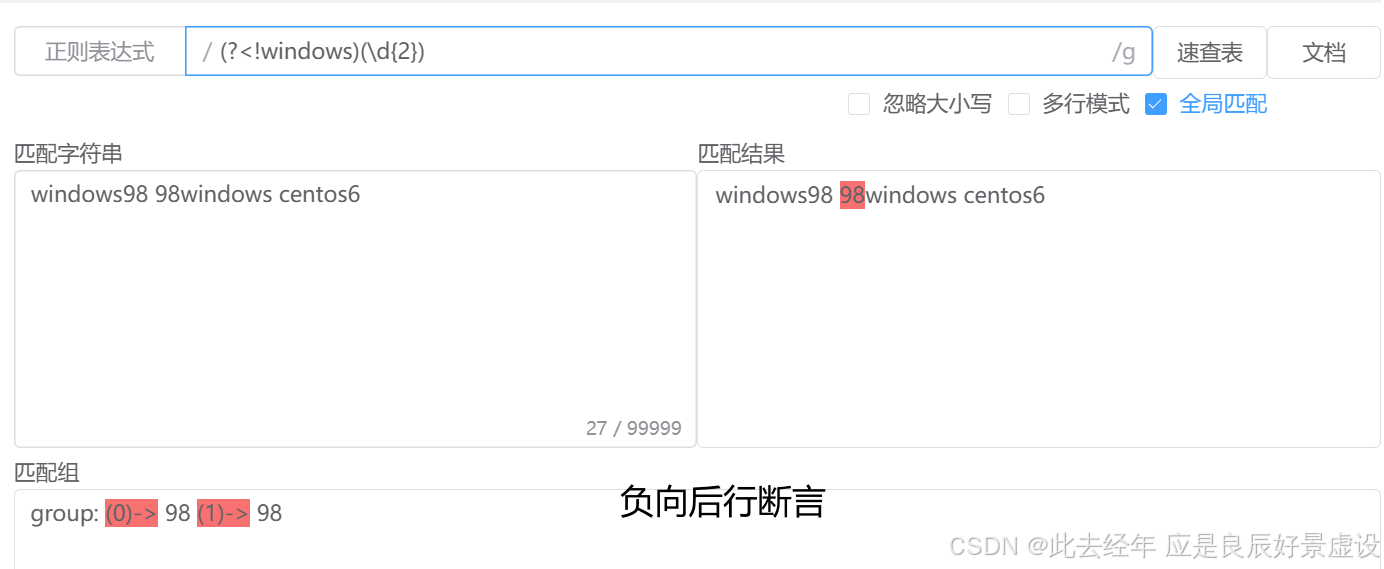
④负向后行断言
# 语法:(?<!pattern) # 用法:检查当前位置之前的字符是否不匹配 pattern 如果不匹配 则继续进行后续匹配
八、案例
以下案例来源于编程胶囊-打造学习编程的最好系统
① 案例1
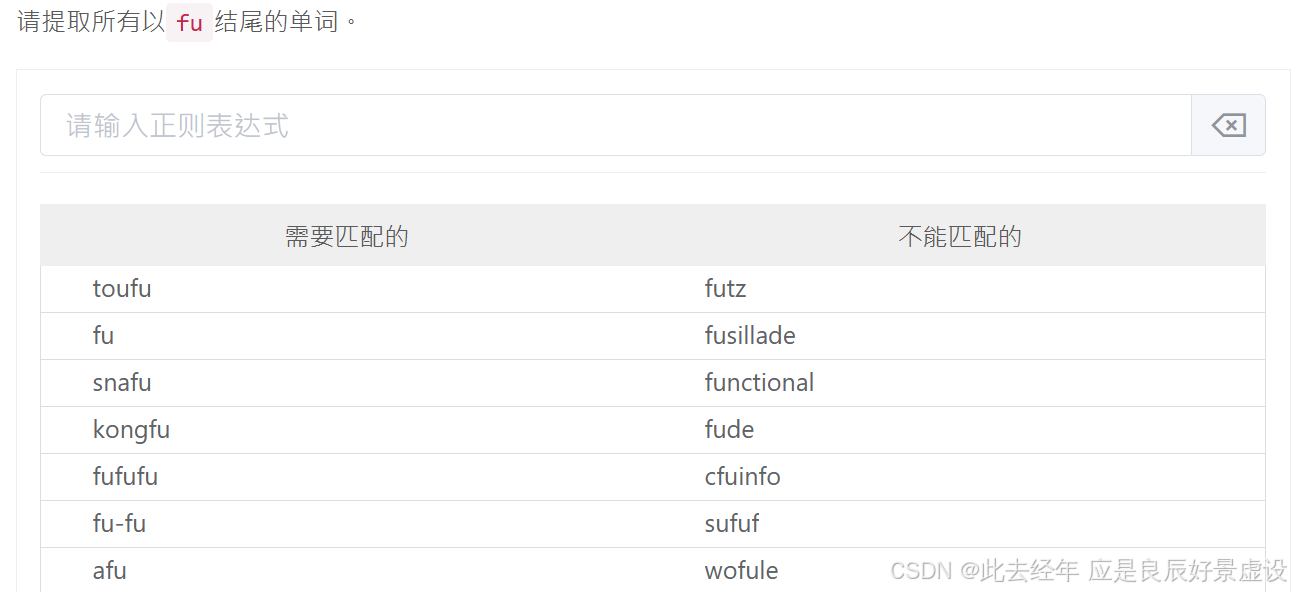
fu$
②案例2
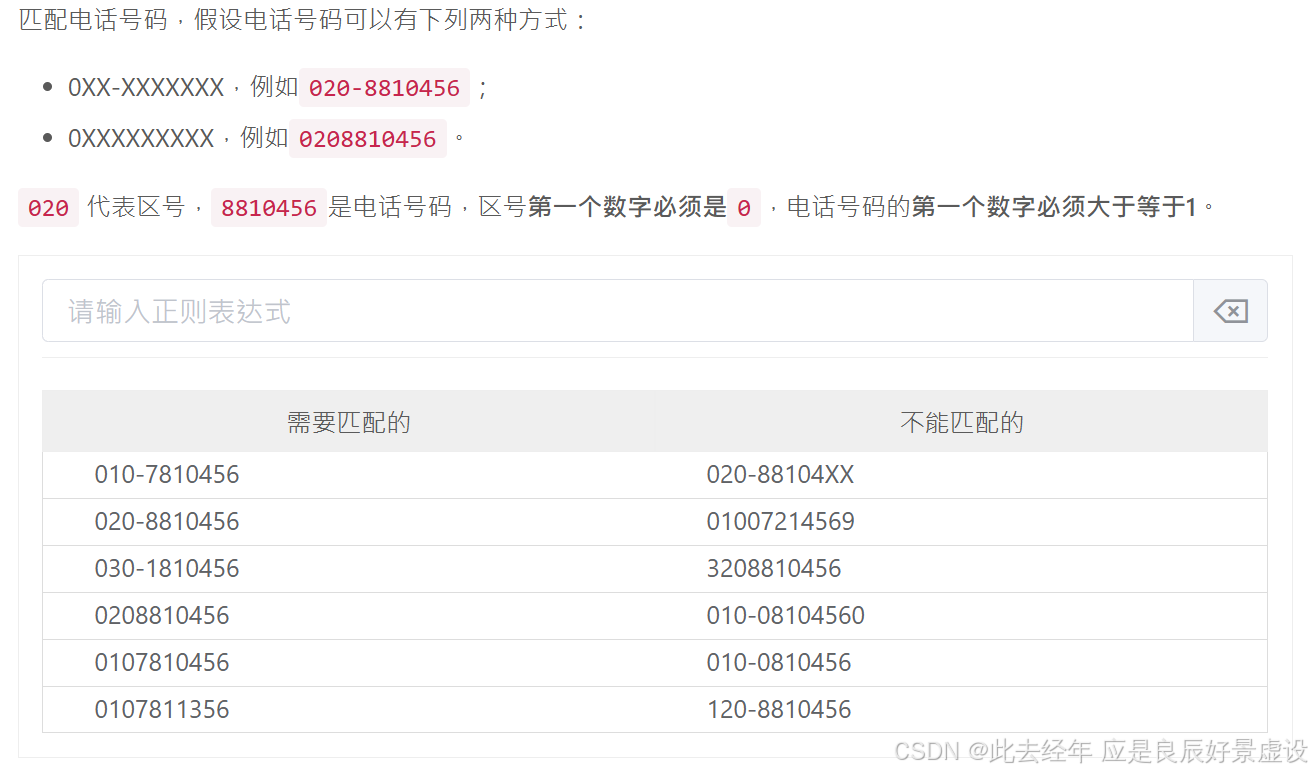
^0\d{2}[-]?[1-9]\d{6}
③案例3
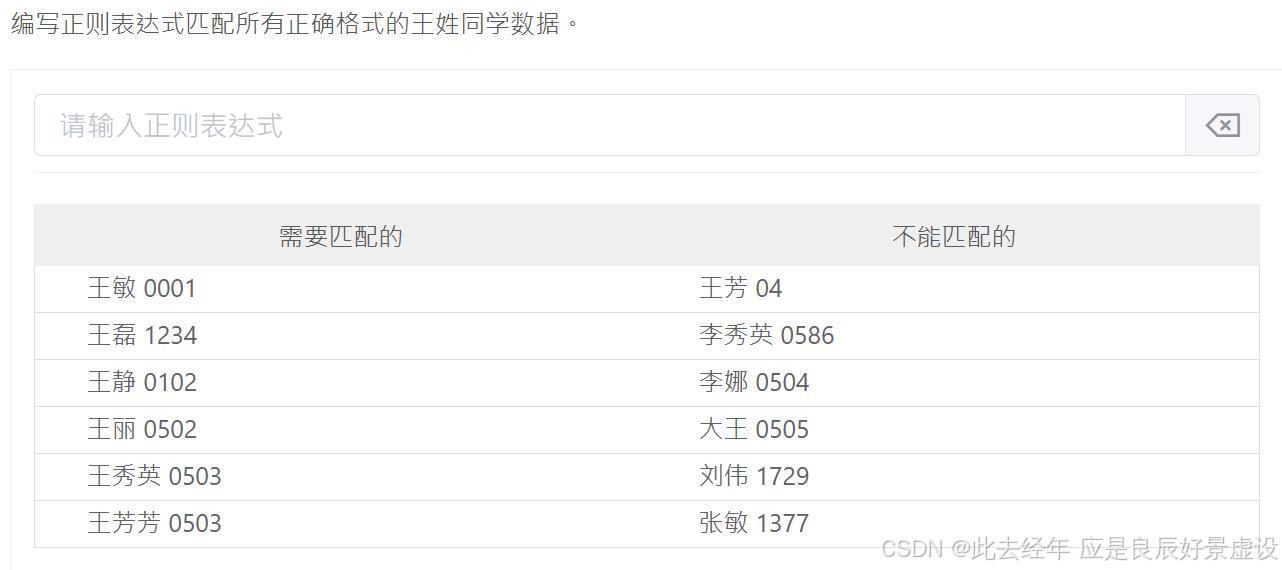
^王.+.*?\d{4}
④案例4
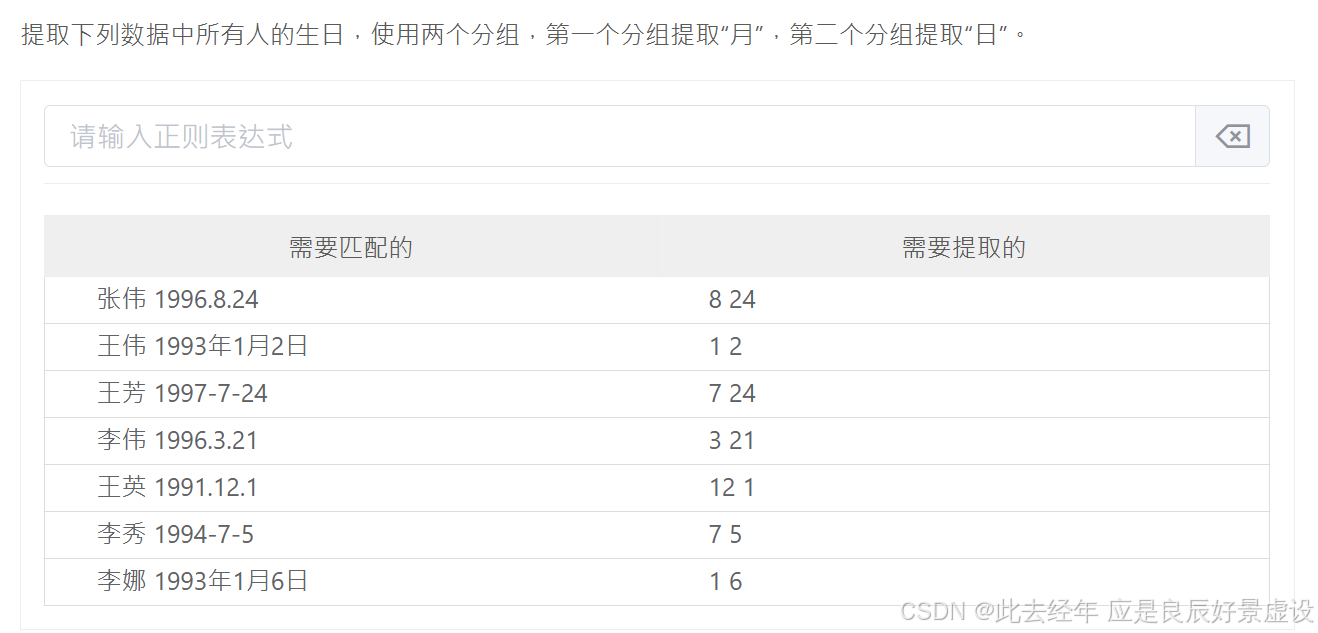
(?:\W{2,3})[ ](?:\d{4})[\W](\d{1,2})[\W](\d{1,2})[\W]?
⑤案例5
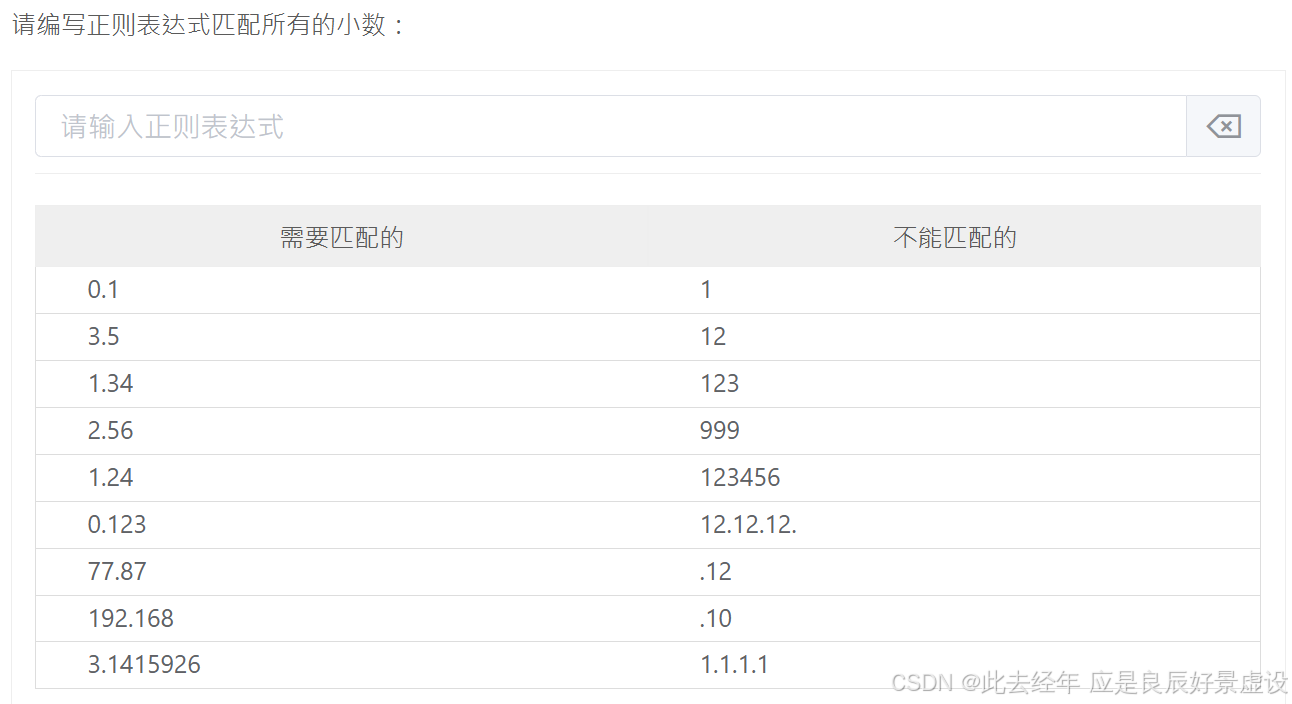
^\d+\.\d+$
⑥案例6
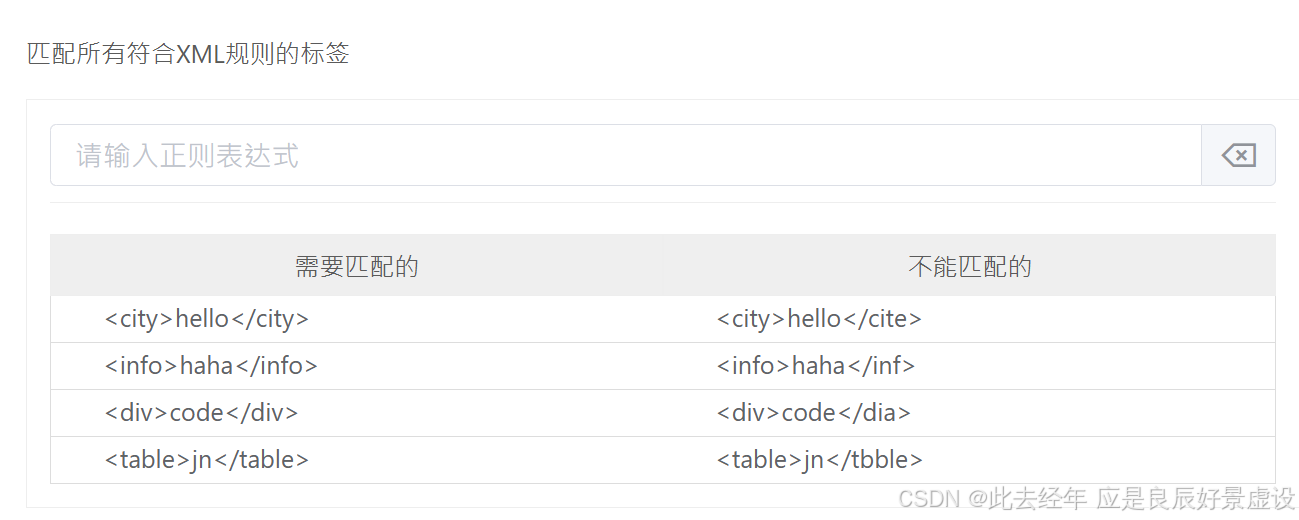
<(\w+)>.+<(\/\1)>

















 1489
1489

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









