




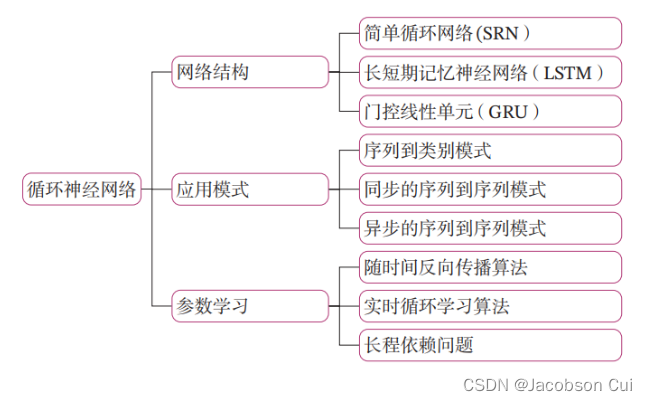
目录
循环神经网络(Recurrent Neural Network,RNN)是一类具有短期记忆能力的神经网络。在循环神经网络中,神经元不但可以接受其他神经元的信息,也可以接受自身的信息,形成具有环路的网络结构。和前馈神经网络相比,循环神经网络更加符合生物神经网络的结构。目前,循环神经网络已经被广泛应用在语音识别、语言模型以及自然语言生成等任务上。
6.1 循环神经网络的记忆能力实验
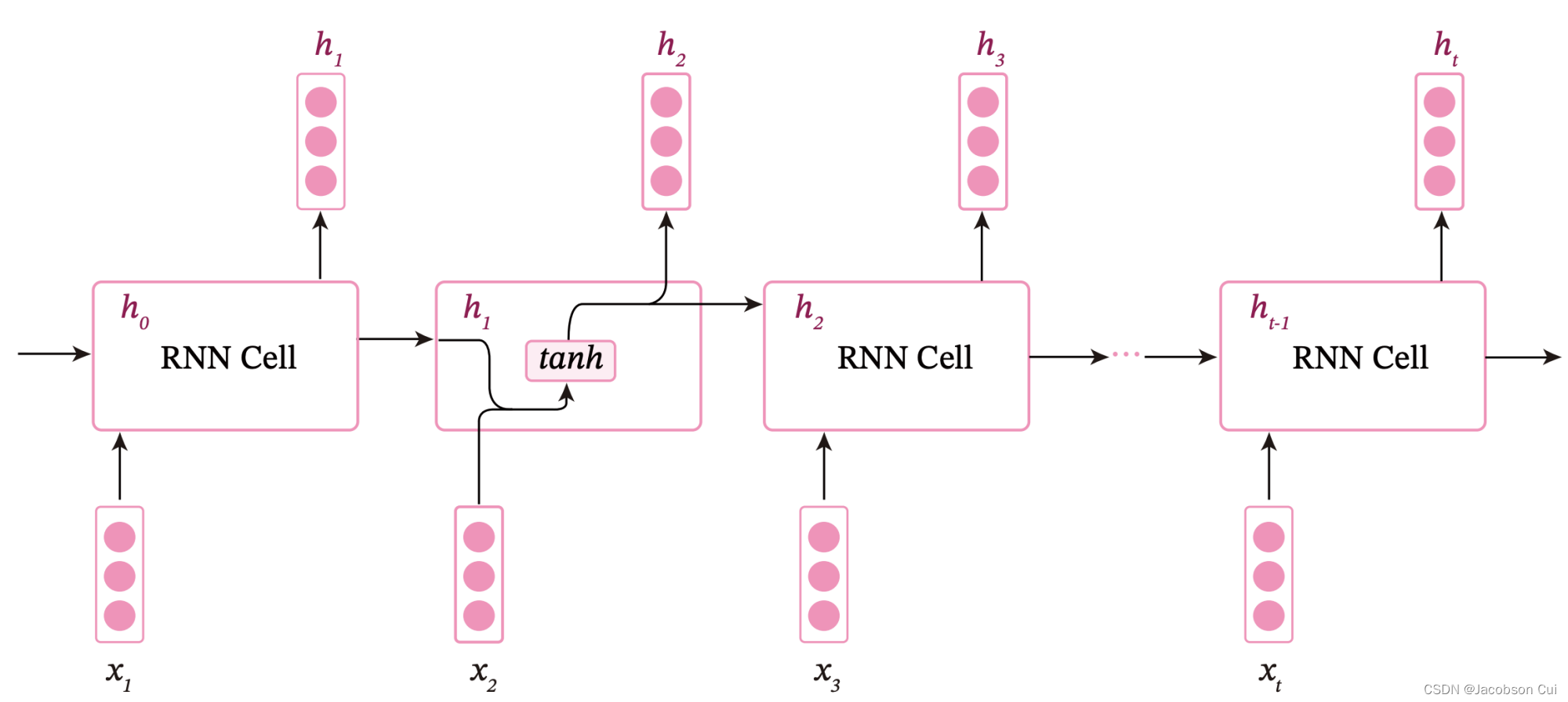
循环神经网络的一种简单实现是简单循环网络(Simple Recurrent Network,SRN)
令向量表示在时刻tt时网络的输入,
表示隐藏层状态(即隐藏层神经元活性值),则
不仅和当前时刻的输入
相关,也和上一个时刻的隐藏层状态
相关. 简单循环网络在时刻
的更新公式为
其中为隐状态向量,
为状态-状态权重矩阵,
为状态-输入权重矩阵,
为偏置向量。
简单循环网络在参数学习时存在长程依赖问题,很难建模长时间间隔(Long Range)的状态之间的依赖关系。为了测试简单循环网络的记忆能力,本节构建一个数字求和任务进行实验。
数字求和任务的输入是一串数字,前两个位置的数字为0-9,其余数字随机生成(主要为0),预测目标是输入序列中前两个数字的加和。图6.3展示了长度为10的数字序列。
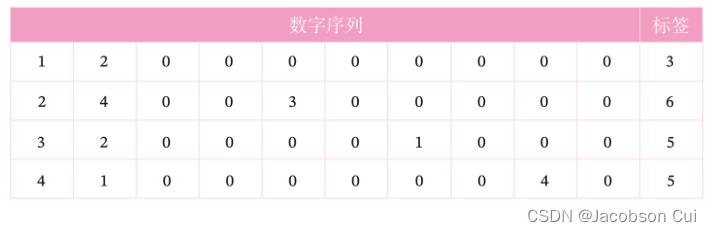
如果序列长度越长,准确率越高,则说明网络的记忆能力越好。因此,我们可以构建不同长度的数据集,通过验证简单循环网络在不同长度的数据集上的表现,从而测试简单循环网络的长程依赖能力。
6.1.1 数据集构建
构建不同长度的数字预测数据集DigitSum
6.1.1.1 数据集的构建函数
由于在本任务中,输入序列的前两位数字为 0 − 9,其组合数是固定的,所以可以穷举所有的前两位数字组合,并在后面默认用0填充到固定长度。 但考虑到数据的多样性,这里对生成的数字序列中的零位置进行随机采样,并将其随机替换成0-9的数字以增加样本的数量。
我们可以通过设置kk的数值来指定一条样本随机生成的数字序列数量。当生成某个指定长度的数据集时,会同时生成训练集、验证集和测试集。当k=3时,生成训练集。当k=1时,生成验证集和测试集。代码实现如下:
import random
import numpy as np
# 固定随机种子
random.seed(0)
np.random.seed(0)
def generate_data(length, k, save_path):
if length < 3:
raise ValueError("The length of data should be greater than 2.")
if k == 0:
raise ValueError("k should be greater than 0.")
# 生成100条长度为length的数字序列,除前两个字符外,序列其余数字暂用0填充
base_examples = []
for n1 in range(0, 10):
for n2 in range(0, 10):
seq = [n1, n2] + [0] * (length - 2)
label = n1 + n2
base_examples.append((seq, label))
examples = []
# 数据增强:对base_examples中的每条数据,默认生成k条数据,放入examples
for base_example in base_examples:
for _ in range(k):
# 随机生成替换的元素位置和元素
idx = np.random.randint(2, length)
val = np.random.randint(0, 10)
# 对序列中的对应零元素进行替换
seq = base_example[0].copy()
label = base_example[1]
seq[idx] = val
examples.append((seq, label))
# 保存增强后的数据
with open(save_path, "w", encoding="utf-8") as f:
for example in examples:
# 将数据转为字符串类型,方便保存
seq = [str(e) for e in example[0]]
label = str(example[1])
line = " ".join(seq) + "\t" + label + "\n"
f.write(line)
print(f"generate data to: {save_path}.")
# 定义生成的数字序列长度
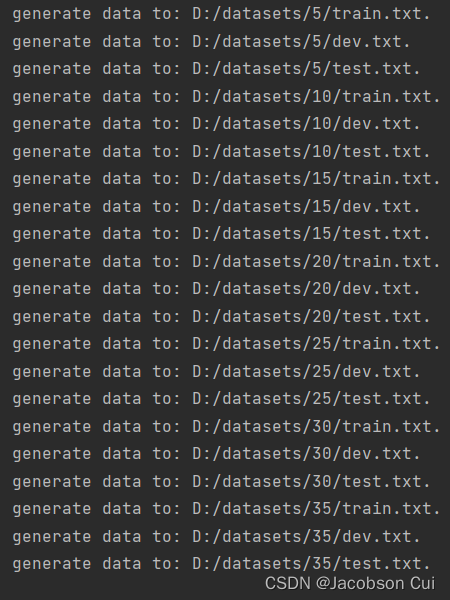
lengths = [5, 10, 15, 20, 25, 30, 35]
for length in lengths:
# 生成长度为length的训练数据
save_path = f"D:/datasets/{length}/train.txt"
k = 3
generate_data(length, k, save_path)
# 生成长度为length的验证数据
save_path = f"D:/datasets/{length}/dev.txt"
k = 1
generate_data(length, k, save_path)
# 生成长度为length的测试数据
save_path = f"D:/datasets/{length}/test.txt"
k = 1
generate_data(length, k, save_path)运行结果:
6.1.1.2 加载数据并进行数据划分
为方便使用,本实验提前生成了长度分别为5、10、 15、20、25、30和35的7份数据,存放于“./datasets”目录下,读者可以直接加载使用。代码实现如下:
import os
# 加载数据
def load_data(data_path):
# 加载训练集
train_examples = []
train_path = os.path.join(data_path, "train.txt")
with open(train_path, "r", encoding="utf-8") as f:
for line in f.readlines():
# 解析一行数据,将其处理为数字序列seq和标签label
items = line.strip().split("\t")
seq = [int(i) for i in items[0].split(" ")]
label = int(items[1])
train_examples.append((seq, label))
# 加载验证集
dev_examples = []
dev_path = os.path.join(data_path, "dev.txt")
with open(dev_path, "r", encoding="utf-8") as f:
for line in f.readlines():
# 解析一行数据,将其处理为数字序列seq和标签label
items = line.strip().split("\t")
seq = [int(i) for i in items[0].split(" ")]
label = int(items[1])
dev_examples.append((seq, label))
# 加载测试集
test_examples = []
test_path = os.path.join(data_path, "test.txt")
with open(test_path, "r", encoding="utf-8") as f:
for line in f.readlines():
# 解析一行数据,将其处理为数字序列seq和标签label
items = line.strip().split("\t")
seq = [i 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









