






1.背景:
在做机器学习的时候,我很多时候都将输入的数据进行进一步的修改,在一次的修改后,程序报错RuntimeError: Trying to backward through the graph a second time。表示试图在没有保留中间值的情况下多次执行计算图的反向传播

在现在AI和大模型流行的今天,很多的问题都基本上可以借助ChatGPT进行判误以及解决问题,我首先也是向GPT提问,他给出了1.检查多余的反向传播调用 2.使用 retain_graph=True:以及 3.梯度清零的三个可能解决的方法,都对这个问题没有帮助
2.产生错误的原因——原地置换了训练数据
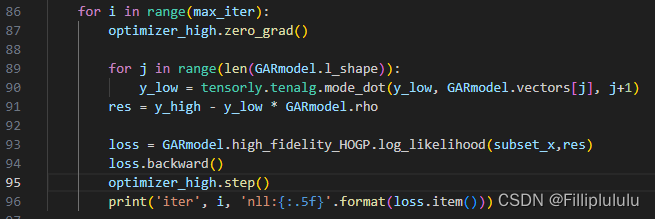
错误原因就是在90行 我在训练的时候对y_low进行的运算,导致了y_low这个训练数据变成了需要梯度回传,导致了重复多次回传的报错,这个错误很小很隐晦,我遇到了很多次,网上尝试的方法都是保留梯度图,允许多次回传之类的,但事实上并不管用,找出这个数据的流程是查看变量的属性
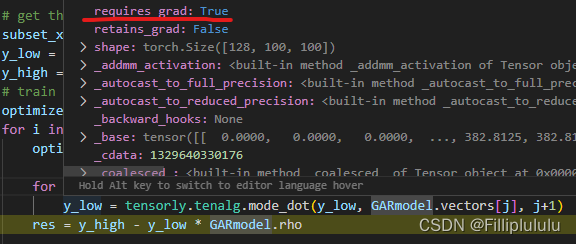
3.解决办法
产生这个报错的原因可能有很多个,我这个只是其中一个情况,我的解决办法是不让y_low的运算产生梯度回传,因此需要在相应位置添加with torch.no_grad():
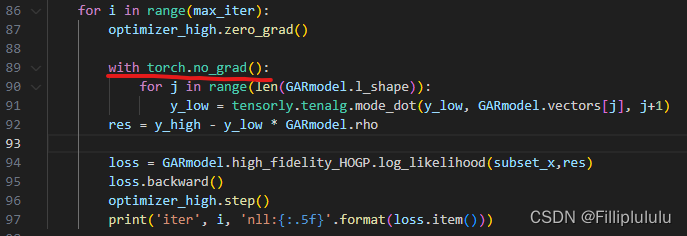
这样就解决了问题,方法是否管用还需要具体情况具体分析,有问题也可以评论区一起探讨~
补充1
date:2024.2.21
如果在神经网络的训练中,nn.Parameter没有被收集更新,保持一个不变的数值的话,也会导致这个报错的发生
比如这个语句:
self.length_scale = torch.exp(nn.Parameter(torch.log(torch.tensor(length_scale))))
它一直都是pytorch数据,而不是nn.Parameter类型,所以在第一次回传时数据就没有更新,第二次回传时就会出现上面的报错
正确的改法如下:
self.length_scale = nn.Parameter(torch.exp(torch.log(torch.tensor(length_scale))))
对于这个问题,很多情况都是因为代码不规范导致,至于报错的原因,我对这个问题的理解在不断深入,希望之后可以带来更加正确的解答,也希望大家和我多多探讨



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











