







【Kafka-3.x-教程】专栏:
【Kafka-3.x-教程】-【一】Kafka 概述、Kafka 快速入门
【Kafka-3.x-教程】-【二】Kafka-生产者-Producer
【Kafka-3.x-教程】-【三】Kafka-Broker、Kafka-Kraft
【Kafka-3.x-教程】-【四】Kafka-消费者-Consumer
【Kafka-3.x-教程】-【五】Kafka-监控-Eagle
【Kafka-3.x-教程】-【六】Kafka 外部系统集成 【Flume、Flink、SpringBoot、Spark】
【Kafka-3.x-教程】-【七】Kafka 生产调优、Kafka 压力测试
【Kafka-3.x-教程】-【三】Kafka-Broker、Kafka-Kraft
1)Kafka Broker 工作流程
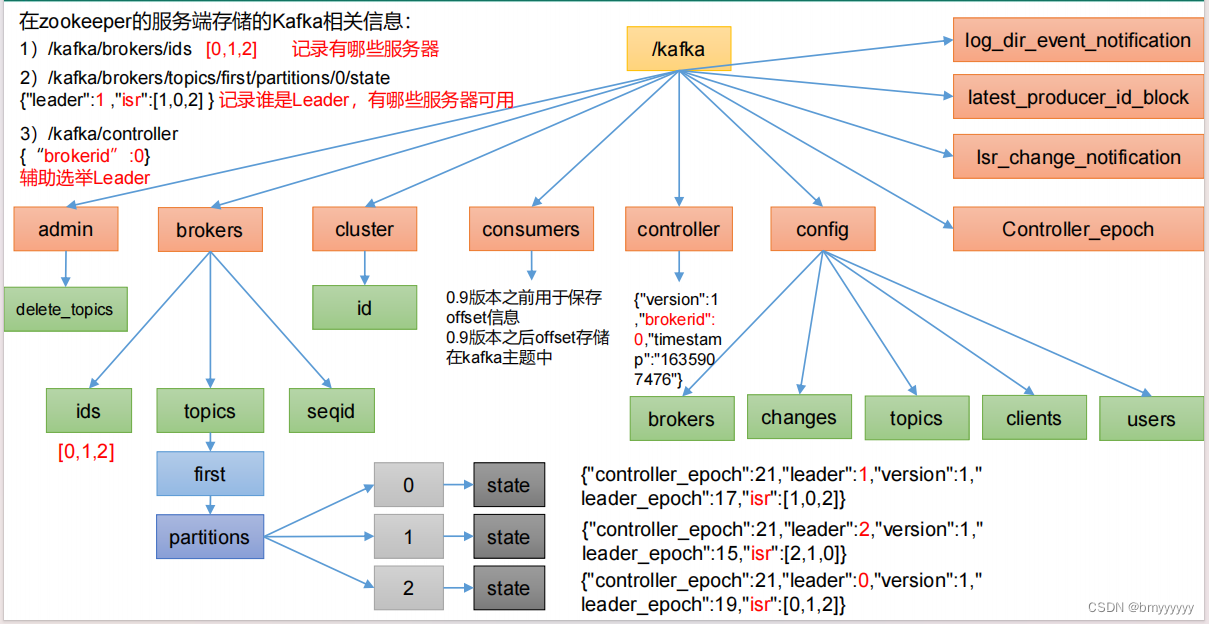
1.1.Zookeeper 存储的 Kafka 信息
Kafka 2.8 版本以后,Kafka-Kraft 模式出现,不再依赖 ZK,由 controller 节点代替 zookeeper,元数据保存在 controller 中,由 controller 直接进行 Kafka 集群管理。点击此处查看 Kafka-Kraft 模式。
1.2.Kafka Broker 总体工作流程
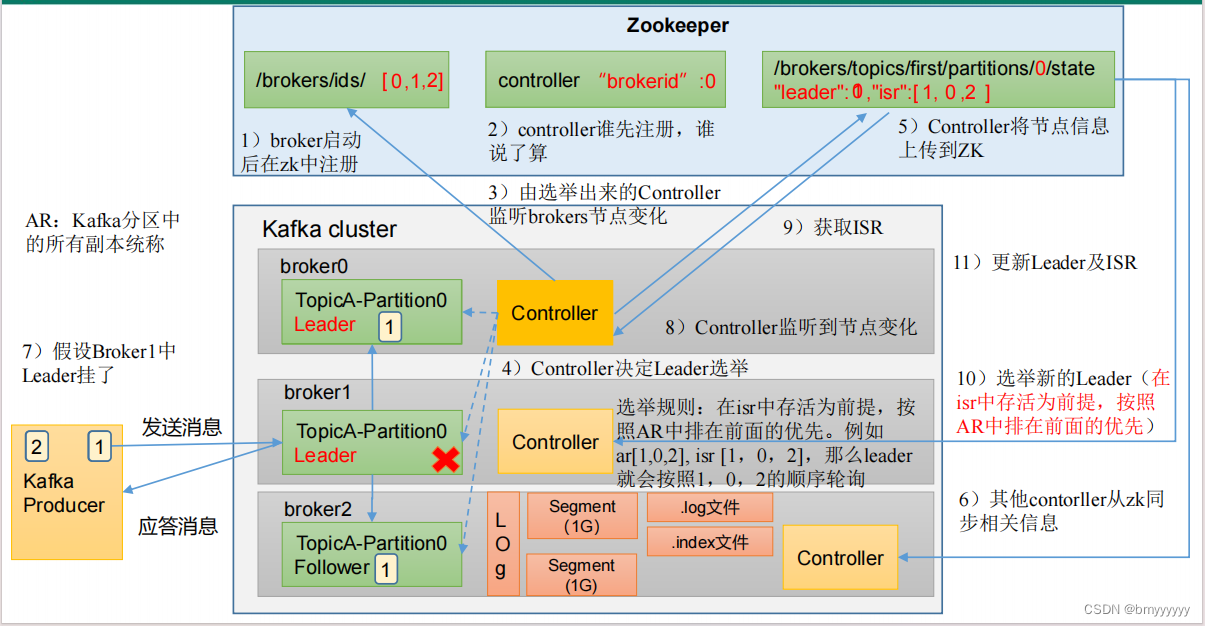
1、Broker 启动后向 ZK 进行注册,ZK 记录好存活的 Broker。
2、每个 Broker 中都有 Controller,谁的 Controller 先注册谁就是 Controller Leader。
3、Controller Leader 上线后监听已经注册的 Broker 节点的变化。
4、Controller 开始选举 Leader
(1)选举规则:在 ISR 中存活着的节点,按照 AR 中排在前面的优先,Leader 也会按照 AR 中的排列顺序进行轮询。
(2)AR:Kafka 分区中所有副本的统称。
5、Controller 将节点信息(Leader、ISR)记录在 ZK 中。
6、其他 Controller 节点从 ZK 中拉取记录好的数据(防止 Leader 挂了后其他节点上位获取相关数据)。
7、Producer 发送消息后 Follower 主动从 Leader 同步数据。
(1)底层以 log 的方式进行存储,但是 log 实际上是抽象的称呼,实际上是以 segment (1G)进行存储。
(2)segment 中包含 .log 和 .index 文件,.log 就是数据,.index 负责加快检索速度。
8、如果 Leader 挂了,Controller 会监听到这个变化,从而在 ZK 中重新拉取到 Leader 信息和 ISR 信息。
9、重新选举,原则还是按照 AR 中排在前面的优先。
10、将新的 Leader 和 ISR 信息更新回 ZK 中。
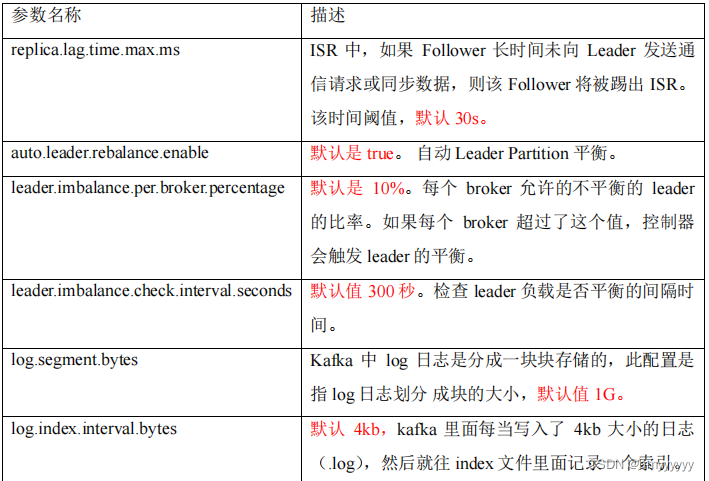
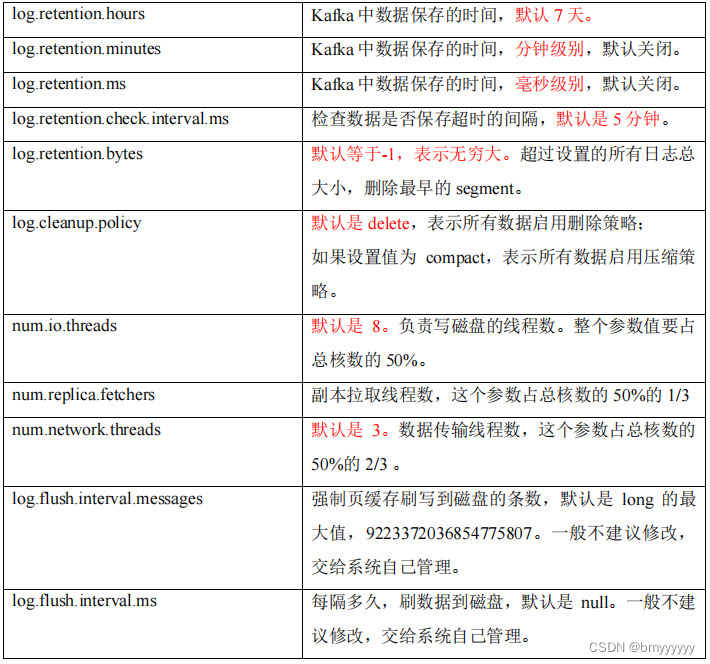
1.3.Broker 重要参数
2)节点服役和退役
实际生产中,会出现 kafka 节点的服役和退役,那么我们该如何进行负载均衡操作呢?
2.1.服役新节点
1、创建一个要均衡的主题。
vim topics-to-move.json
#添加下面内容
{
"topics": [
{
"topic": "first"}
],
"version": 1
}
2、生成一个负载均衡的计划。
bin/kafka-reassign-partitions.sh --bootstrap-server hadoop102:9092 --topics-to-move-json-file topics-to-move.json --broker-list "0,1,2,3" --generate
#Current partition replica assignment
#{"version":1,"partitions":[{"topic":"first","partition":0,"replicas":[0,2,1],"log_dirs":["any","any","any"]},{"topic":"first","partition":1,"replicas":[2,1,0],"log_dirs":["any","any","any"]},{"topic":"first","partition":2,"replicas":[1,0,2],"log_dirs":["any","any","any"]}]}
#Proposed partition reassignment configuration
#{"version":1,"partitions":[{"topic":"first","partition":0,"replicas":[2,3,0],"log_dirs":["any","any","any"]},{"topic":"first","partition":1,"replicas":[3,0,1],"log_dirs":["any","any","any"]},{"topic":"first","partition":2,"replicas":[0,1,2],"log_dirs":["any","any","any"]}]}
3、创建副本存储计划(所有副本存储在 broker0、broker1、broker2、broker3 中)。
vim increase-replication-factor.json
#输入如下内容:
{
"version":1,"partitions":[{
"topic":"first","partition":0,"replicas":[2,3,0],"log_dirs":["any","any","any"]},{
"topic":"first","partition":1,"replicas":[3,0,1],"log_dirs":["any","any","any"]},{
"topic":"first","partition":2,"replicas":[0,1,2],"log_dirs":["any","any","any"]}]}
4、执行副本存储计划。
bin/kafka-reassign-partitions.sh --bootstrap-server hadoop102:9092 --reassignment-json-file increase-replication-factor.json --execute
5、验证副本存储计划。
bin/kafka-reassign-partitions.sh --bootstrap-server hadoop102:9092 --reassignment-json-file increase-replication-factor.json --verify
#Status of partition reassignment:
#Reassignment of partition first-0 is complete.
#Reassignment of partition first-1 is complete.
#Reassignment of partition first-2 is complete.
#Clearing broker-level throttles on brokers 0,1,2,3
#Clearing topic-level throttles on topic first
2.2.退役旧节点
1、执行负载均衡操作
先按照退役一台节点,生成执行计划,然后按照服役时操作流程执行负载均衡。
(1)创建一个要均衡的主题。
vim topics-to-move.json
{
"topics": [
{
"topic": "first"}
],
"version": 1
}
2、创建执行计划。
bin/kafka-reassign-partitions.sh --bootstrap-server hadoop102:9092 --topics-to-move-json-file topics-to-move.json --broker-list "0,1,2" --generate
#Current partition replica assignment
#{"version":1,"partitions":[{"topic":"first","partition":0,"replicas":[2,0,1],"log_dirs":["any","any","any"]},{"topic":"first","partition":1,"replicas":[3,1,2],"log_dirs":["any","any","an 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









