







 本文探讨了在Python pandas中优化速度的方法,对比了for循环、iterrows、apply以及矢量化操作的性能。通过实例展示了如何利用isin、apply、pd.cut和NumPy的digitize函数大幅提高数据处理速度,特别是digitize方法在处理10年小时数据时,速度提升了315倍。
本文探讨了在Python pandas中优化速度的方法,对比了for循环、iterrows、apply以及矢量化操作的性能。通过实例展示了如何利用isin、apply、pd.cut和NumPy的digitize函数大幅提高数据处理速度,特别是digitize方法在处理10年小时数据时,速度提升了315倍。

for是所有编程语言的基础语法,初学者为了快速实现功能,依懒性较强。但如果从运算时间性能上考虑可能不是特别好的选择。
本次介绍几个常见的提速方法,一个比一个快,了解pandas本质,才能知道如何提速。
下面是一个例子
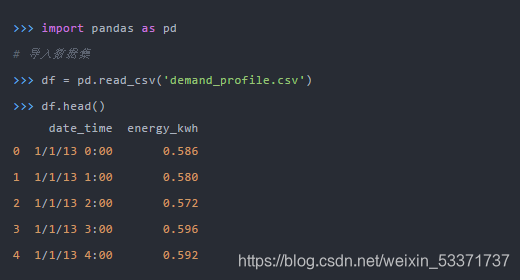
基于上面的数据,我们现在要增加一个新的特征,但这个新的特征是基于一些时间条件生成的,根据时长(小时)而变化,如下:

因此,如果你不知道如何提速,那正常第一想法可能就是用apply方法写一个函数,函数里面写好时间条件的逻辑代码。
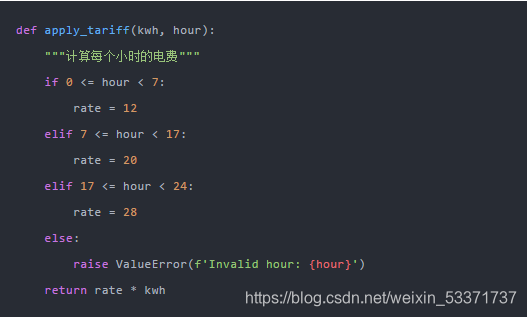
然后使用for循环来遍历df,根据apply函数逻辑添加新的特征,如下:
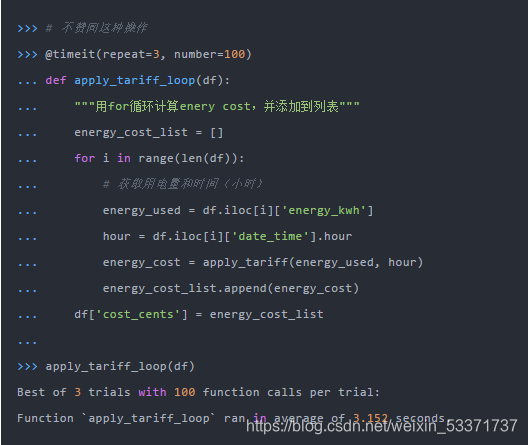
对于那些写Pythonic
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









